


文章に書かれている内容から、どのカテゴリに分類するか判断を行う文書分類は、新聞記事のカテゴリ分類(政治、経済、スポーツなど)や、身近なところでは迷惑メールフィルタでの利用があります。また業務においては、大量に発生する文書、例えば契約書、提案書、日報、作業報告書などを効率よく分類することで業務効率化を図るなど様々な利用が考えれます。今回、文書分類器としてfasttext、Watson Natural Language Classifierを対象に分類精度、速度、費用について比較を行います。

fasttextとWatson Natural Language Clasifier
本記事での比較はfacebookがオープンソースとして公開しているfasttextと、商用サービスとして公開しているIBM WatsonのNatural Language Classifier(以降 NLC)を対象に文章分類の精度評価を行います。尚、プログラムはGoogle Colabo上で実装しており、そのリンクを記事の最後に掲載しますので、Google アカウントのある方は試してみてください。ただし、NLCは有料サービスとなります。このため無料の範囲で確認できるのは、スクレイピングとfasttextによる分類までとなります。
fasttextは、様々な文章のベクトル化と分類を高速に行う事ができる自然言語処理ライブラリで、大量の文書を高速に処理できる特徴があります。サイトの説明では、1日〜5日かかっていたものが5〜10秒で処理が行え、10億語を10分で処理し50万文章を30万カテゴリに分類するのに5分かからないという処理の速さとのことです。
NLCはIBM Watsonから提供されている自然言語分類器で、テキストの背後にある意図を解釈し、関連性に基づいて分類が行われます。クラウドから提供されるWebサービスとなり、APIを使い開発を行うため実装が素早く簡単に行う事ができます。

ニュースの分類器
本記事で行う分類テーマは、ニュースタイトルからどのカテゴリのニュースであるかを推定します。尚、ニュースはライブドアニュースが公開しているAPIを利用し訓練データ、検証データの作成を行います。収集するニュースのカテゴリは、”スポーツ”、”海外”、”経済”、”グルメ”、”宇宙”の5カテゴリとします。訓練データは各カテゴリ100件、検証データは各カテゴリ20件とします。
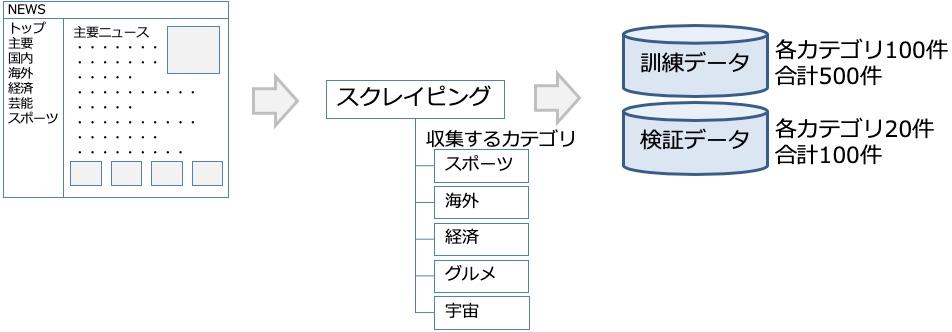
収集した訓練データは次のようにラベルを割り当てます。
| ラベル | カテゴリ | ニュースサイト |
| __label__0 | スポーツ | https://news.livedoor.com/topics/category/sports/ |
| __label__1 | 海外 | https://news.livedoor.com/topics/category/world/ |
| __label__2 | 経済 | https://news.livedoor.com/article/category/2/ |
| __label__3 | グルメ | https://news.livedoor.com/topics/category/gourmet/ |
| __label__4 | 宇宙 | https://news.livedoor.com/topics/keyword/32398/ |
fasttextの訓練データの形式は”ラベル, ニュースタイトル“、NLCは”ニュースタイトル,ラベル“の順となるため項目を入れ替えてそれぞれの訓練データとします。
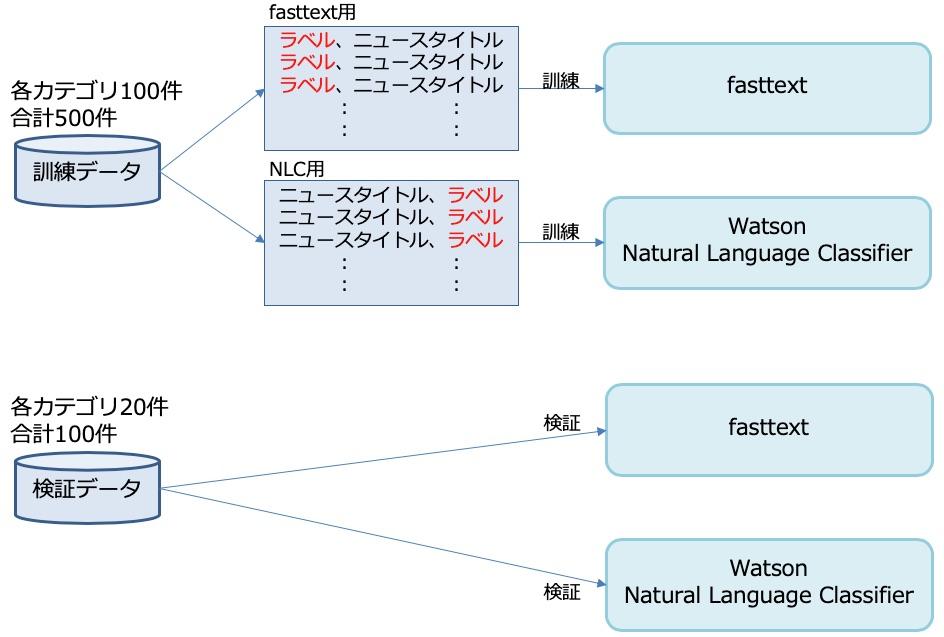

fasttextとWatson Natural Language Classifierの比較
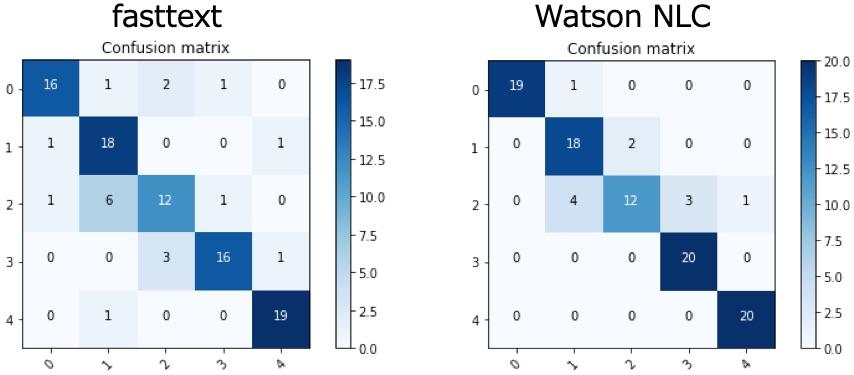
混同行列を見てましょう。このマトリックスは横方向が予測したクラス、縦方向が実際のクラスとなります。分かりやすところで説明すると、右のWatson NLCにおいてクラスが0と判断したニュース19件あり、それが全て正解であったことが分かります。ただし、検証データは各クラス20件としています。実際のクラスを示す縦方向、0の行を見ると本来クラス0となるべきニュースをWatsonがクラス1と分類している事がわかります。この混同行列は対角方向の数字が高いほど良いモデルと視覚的にも分かりやすく判断ができます。
このマトリックスからはfasttextが若干劣っている事が分かります。もちろんfasttextはパラメータをチューニングする事で精度向上が望めます。ちなみに今回のfasttextではepoch数を1,000、損失関数にHierarchical Softmax(hs)を指定し、他はデフォルト値を採用しています。
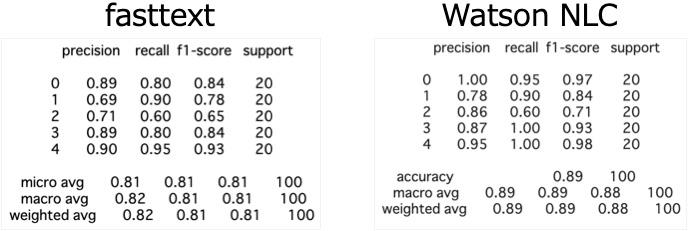
他の指標も見てみましょう。
さすがに有料なだけあって精度は、Watson NLCの方がいいですね。
| 指標(マクロ平均) | fasttext | Watson NLC |
| 正解率(accuracy) | 0.81 | 0.89 |
| 適合率(precision) | 0.82 | 0.89 |
| 再現率(recall) | 0.81 | 0.89 |
| F値(F1-measure) | 0.81 | 0.88 |
クラス数がこの程度ですので、クラスごとにも指標を見てみましょう。sklearnに評価指標をまとめて表示してくれるものがありますので、それを実行した結果を貼り付けます。これを見ると、どちらもクラス2の経済ニュースの分類が苦手なようです。
訓練データ500件を使い学習を行なった際にかかった時間です。fasttextが圧倒的に早い事がわかります。企業で扱う文書の多さや、特にシステム構築時には大量の文書を使い訓練を行わせる事を考えると、訓練時間も無視できない評価項目となります。
| 分類器 | 訓練時間 |
| fasttext
|
2.03秒 |
| Watson Natural Language Classifier | 16分4秒 |
fasttextはOSSのため費用なし表記しました。NLCは1ヶ月当たりの特典はあるものの分類器を置いておくだけでも費用が発生します。また訓練1回あたりにも費用が発生します。この点は人間と一緒で教育にはお金がかかりますね。
2019年12月調べ
| 分類器 | 費用 | 備考 |
| fasttext
|
なし | |
| Watson Natural Language Classifier | \2,240/1分類器月額
\0.392/API call \336/訓練1回あたり |
1ヶ月当たりに1つの Natural Language Classifierが無料
1ヶ月当たり1,000件のAPI呼び出しが無料 1ヶ月当たり4件のトレーニング・イベントが無料 |

まとめ
・ライブドアニュースのタイトルからカテゴリの分類を実施
・ニュースは5カテゴリ(”スポーツ”、”海外”、”経済”、”グルメ”、”宇宙”)
・訓練データは各カテゴリ100件とし、合計 500件
・検証データは各カテゴリ20件とし、合計100件
・認識精度はWatson NLCの方が7、8%良い結果となった
・訓練時間はfasttextの方が2.03秒と非常に短い時間で行えた
・費用にいても確認を行なった(表参照)
今回はfasttext、Watson NLCを対象に文書分類について比較を行なった、若干精度が劣ったfasttextであったが訓練速度、費用面においては有利な結果となった、Watsonは精度もよくWebAPIを使う開発のため簡単に素早く実装が行え得る事が確認できた。
また利用シーンによっては、fasttextでも十分活用できると考えられるため、求められる精度やシステムの重要度、コストを考慮してWatson、fastextの使い分けが考えらる。また、fasttextについては、複数のアルゴリズムを用いてアンサンブル学習とする事で精度はさらに向上すると考えれます。

プログラム
今回の検証にて実装を行なったプログラムは下記にリンクを貼りました。Google Colaboratoryでの実行を想定したもになっていますので、ダウンロードしローカルで実行する場合は、プログラム中のGoogleドライブマウント処理をコメントとしてください。
(2)〜(4)は、(1)のスクレイピングによって収集したデータを前提としています。
尚、Watsonの利用に関しては、IBM CLOUDアカウントが必要なります。またNLCは有料サービスとなりますのでご注意ください。尚、費用が発生しても当方で責任は負わないものとします。
(1)ライブドアニュースのスクレイピングプログラム(Google Colaboratoryから共有, python)
(2)fasttext(訓練、分類)プログラム(Google Colaboratoryから共有, python)
(3)Watson Natural Language Classierの分類器作成と訓練(curl、注:NLCは有料サービスです)
分類器の作成、訓練を行うスクリプト(curlにてWatsonのWebAPIを実行)
(4)Watson Natural Language Classifierの分類プログラム(Google Colaboratoryから共有, python)
それでは、良いクリスマスを!

