


こんにちは!
やまさきあです。
最近私はほぼ在宅にて勤務しています。
そのため、会社へ通勤するときは定期券を購入せず、
都度、経費の申請を行っています。
このように、コロナ禍において働き方は大きく変化しました。
働き方が変化すると、私のように経費の申請回数が増える例に始まり、
在宅勤務の申請等、事務処理の量が増えた方も多くいらっしゃるのではないでしょうか。
申請する量が増えるということは当然、それを見る側の仕事量も増えます。
その際、自動で書類の内容が読み込まれたらいいと思いませんか(^^)?
本日は、そういったドキュメント内の文章を、AIを用いてロボットが解析・処理してくれる
「UiPath Document Understanding」
の使い方やメリット等を説明していきます!
UiPath社の公式サイトによると、
「PDF、画像、手書き、およびスキャン原稿からユーザーに代わってデータを抽出、解析、処理」してくれる機能です。
自動化対象の業務において処理対象となるドキュメントが、同じ入力ファイルでも種類の異なるテンプレートを使用していたり、
あるいは手書きだったりといった場合、自動化業務対象外とするか、高精度のOCR製品を組み込むといったことでなんとか処理していました。
もしくは、
ロボット実行が完了したら、
人間がドキュメント内容を確認して、処理、
そして次のロボットが実行される・・・
などと、自動ワークフローの途中に人間が介入してドキュメント内容を確認し、処理する必要がありました。
↓
ロボットが文章解析を含むすべてのプロセスを処理できるので、人間はデータの検証、チェックと例外処理のみで済むようになります!
ドキュメントはそれぞれ、レイアウトやフォーマットが異なります。固定形式のものもあれば、自由形式のものもあります。手書きやチェックボックス、署名が含まれている場合もあります。
UiPath Document Understandingは、そのようなドキュメントのほとんどについて処理することが可能です。(※一部、形式に対応していない場合もあります。)
文章解析の精度向上のためには、高機能なロボットが必要になってきます。
UiPathでは、ロボットを強化するためAIや機械学習モデルを活用しています。
また、機械学習モデルが繰り返し学習を行うことで、文章解析の精度向上が期待できます。
ドキュメントが回転している、ゆがんでいる、多くの種類がある、低解像度であるといった「ノイズ」はロボットが思うように動作しないことにつながる場合がありますが、UiPath のロボットはこのような「ノイズ」に対応し、適切に文章を読み込んでくれます。
みなさまにもおなじみの、「UiPath Studio」において、Document Understandingアクティビティをドラッグアンドドロップすることで簡単にワークフローに組み込むことができます。
というところで、なんとな~くイメージがついたと思います。
みなさんもDocument Understandingを使ってみたくなったのではないでしょうか(^-^)
それでは、ここからは実際に Document Understanding に触れてみましょう(^^)/
実装の際には、こちらを参考にさせていただきました!
さて、早速、Document Understandingの使い方について説明していきます。
アンケートを読み込み、抽出したい項目だけ抜き出し、Excelに転記する。
読み込みたいドキュメントを用意しておく。
- 回答が記入されているドキュメント
- 回答が記入されていない、まっさらのアンケートテンプレート(あれば)
アンケートや請求書等、通常使っているものでかまいません。
記入済みのものに加え、記入前のものもできれば用意してください。
※ Community Licenseの場合、抽出したデータが精度向上等に使用されるため、セキュリティポリシーに引っかからないかチェックをお願いします!
UiPath Studioをインストールし、立ち上げてください。
Community License(個人のRPA開発者および小規模事業者向け)でもOKです。
インストールがお済みでない方は、こちらのページからインストーラをダウンロードし、インストールしてください。
UiPathを立ち上げたら、新規プロジェクトのプロセスを作成してください。
今回のUiPathバージョンは、2019.10.5 を使用しました。
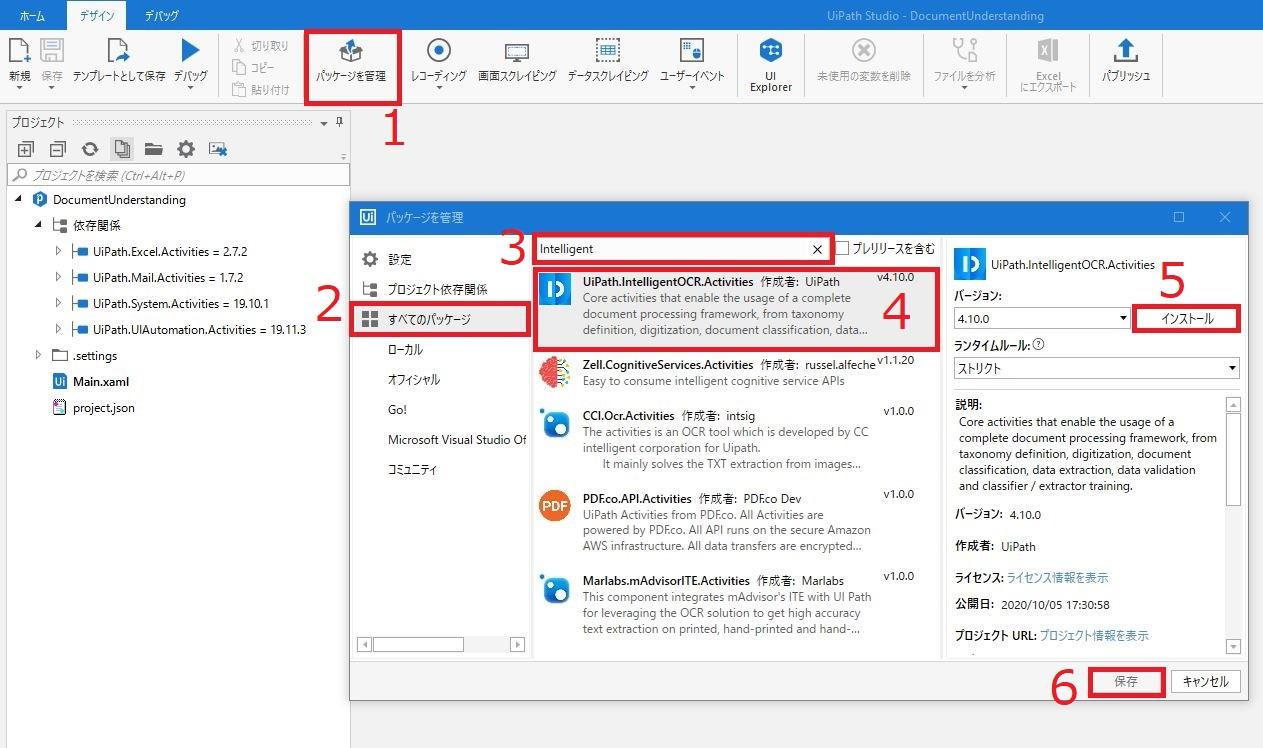
- 「パッケージを管理」をクリック
- 「すべてのパッケージ」をクリック
- 検索窓で「Intelligent」と検索
- 「UiPath.IntelligentOCR.Activities」をクリック
- 「インストール」をクリック
- 「保存」をクリック
- 「ライセンスへの同意」ウィンドウが表示されたら、「同意する」をクリック
インストールするまでに、少し時間がかかります。
インストールが完了したら、元のStudioの画面に戻りますのでそれまで待ちます。
タクソノミーとは、ドキュメントの定義のことです!
ドキュメントの種類と、ドキュメント内の項目について定義されます。
1.「タクソノミーマネージャー」をクリック
(IntelligentOCRパッケージを入れた後にしか出てこないので、注意!)
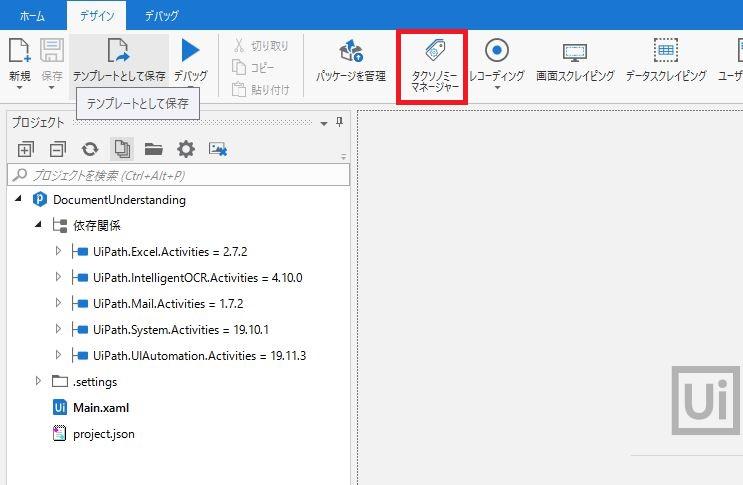
2.タクソノミーマネージャーが開かれる
この時、プロジェクトフォルダ下の「DocumentProcessing」フォルダ内にタクソノミーを管理するファイル「taxonomy.json」が作成されます。
(タクソノミーマネージャーの右上に表示される緑枠内のパスに保存場所が記載されています)
3.「新しいドキュメントの種類を追加」をクリック
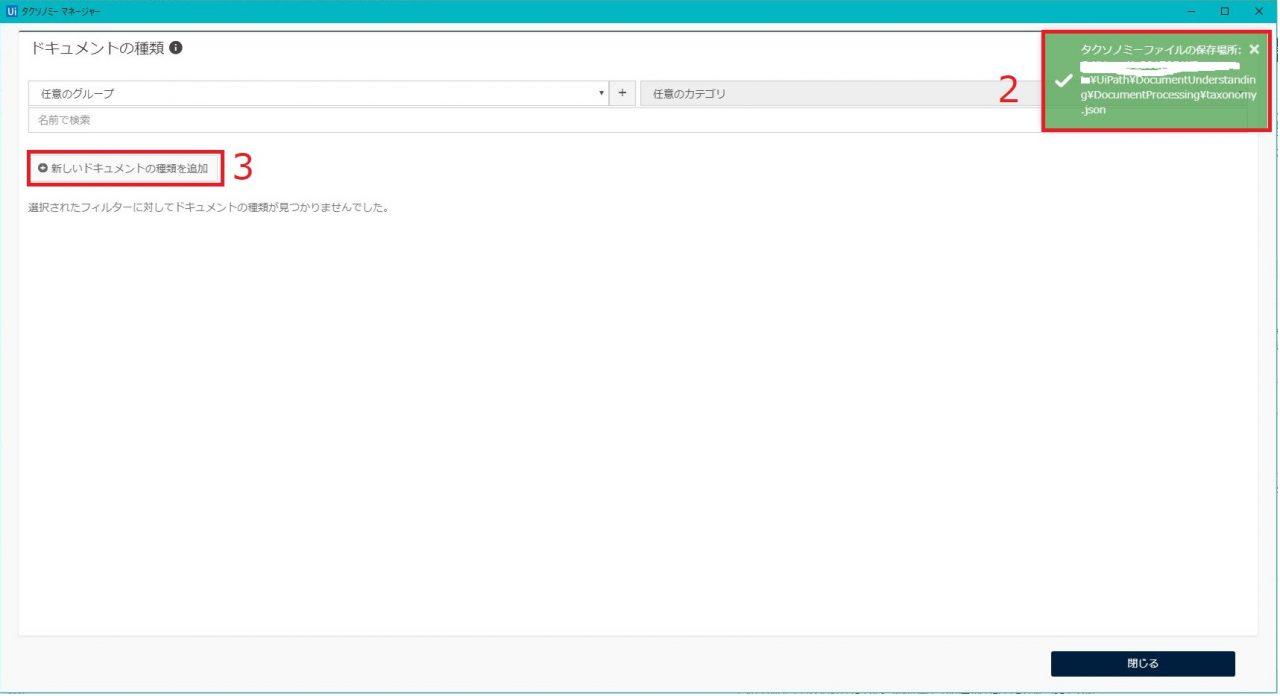
4.「名前」にドキュメントの名称を入力
5.グループを指定する
指定するグループが存在しない場合には、
「ドキュメントの種類」にある「任意のグループ」の右側の「+」ボタンをクリック
→名称を入力
→チェックボタン押下 で作成してください。
6.カテゴリを指定する
指定するカテゴリが存在しない場合には、
「ドキュメントの種類」にある追加対象のグループを選択
→「任意のカテゴリ」の右側の「+」ボタンをクリック
→名称を入力
→チェックボタン押下 で作成してください。
7.フィールドを追加(必要な回数繰り返す)
フィールドとは、ドキュメントから抽出したい項目のことです。
そちらを設定していきます。
「新しいフィールド」をクリック
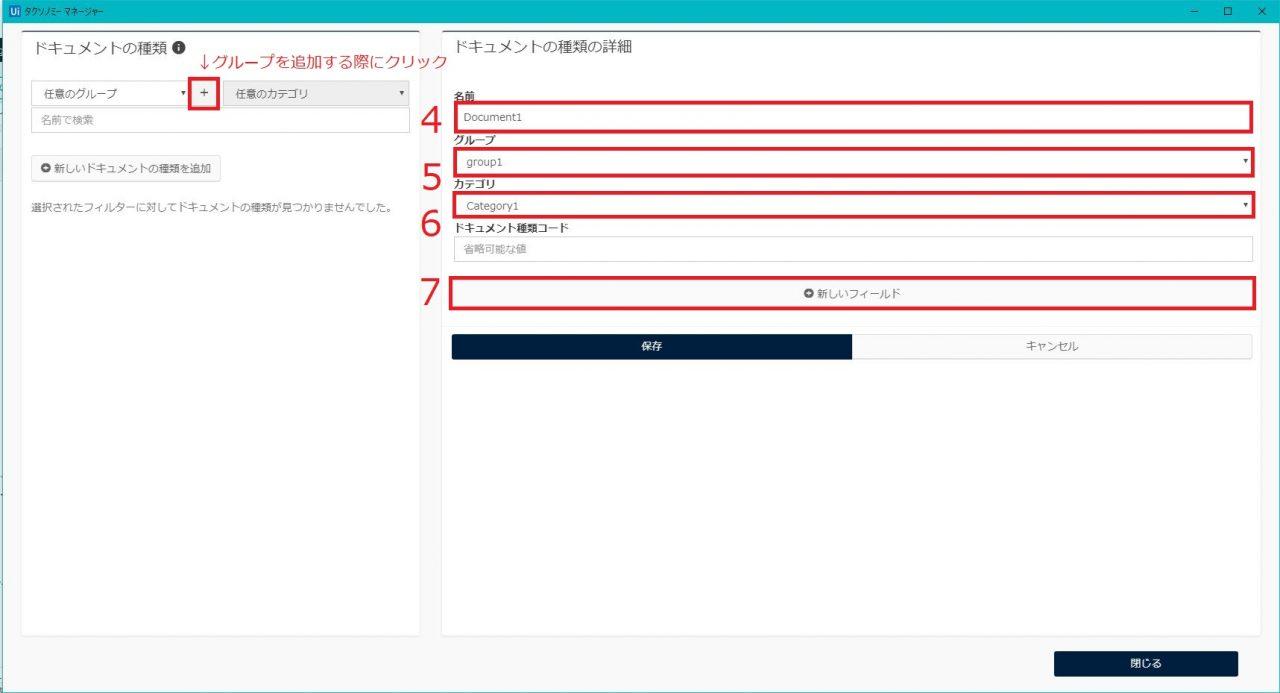
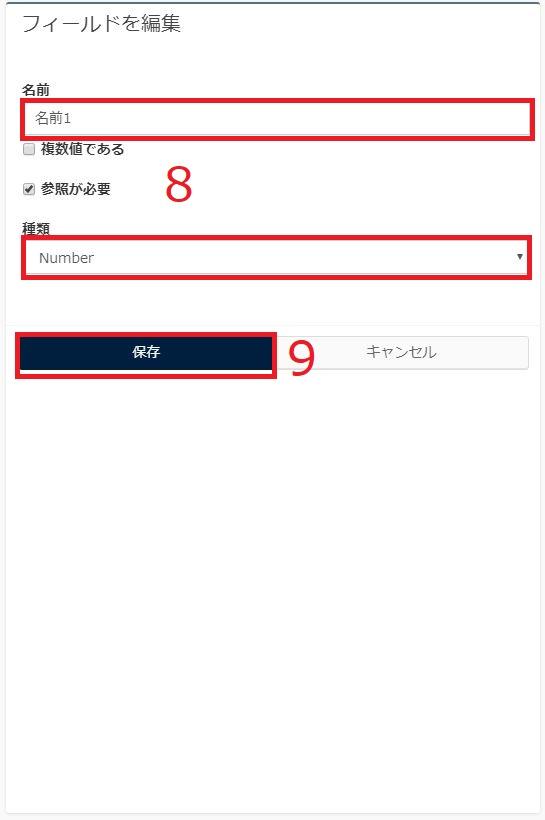
8.右側に「フィールドを編集」が現れるので、フィールド名を入力、種類を選択
種類とは、抽出したい項目がどのような値なのかを指定するものです。
テキスト形式であればText、数字形式であればNumber、
日付形式であればDateのように設定してください。
9.保存ボタンをクリック
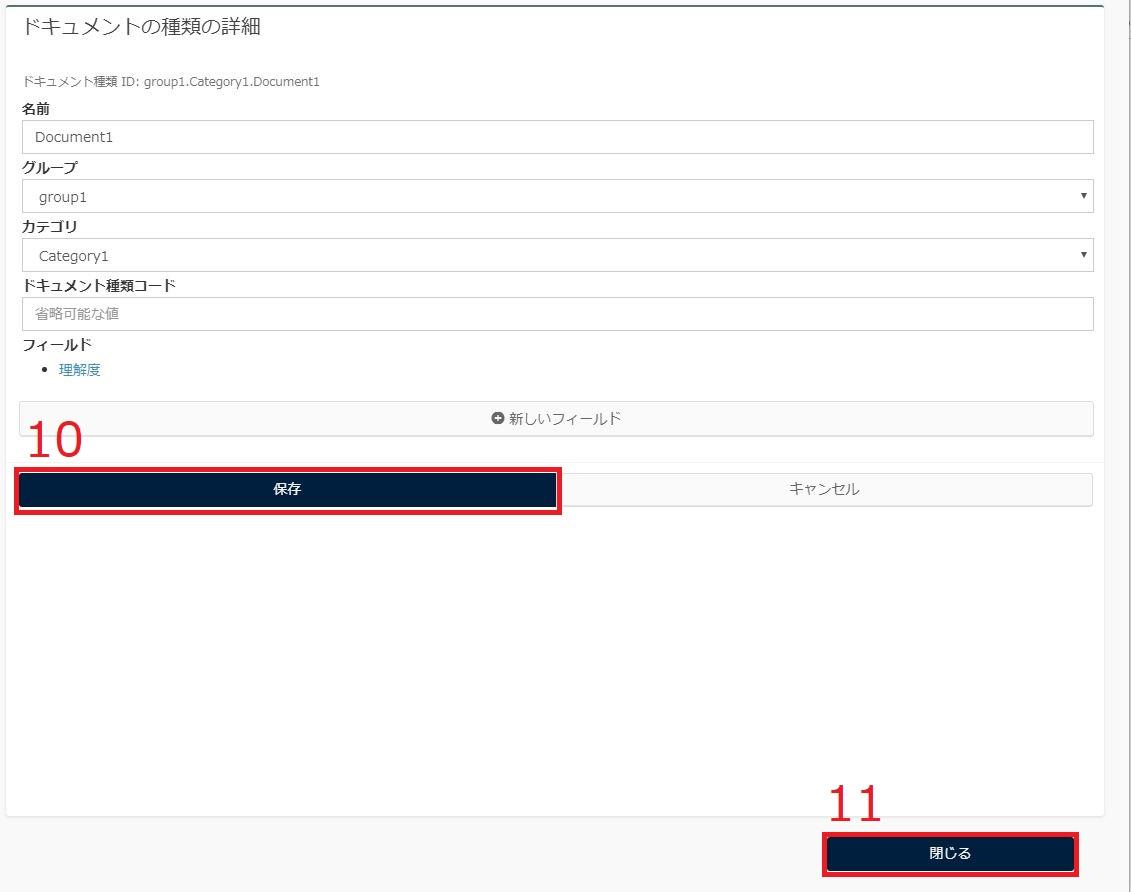
10.フィールドをすべて入力し終わったら、
「ドキュメントの種類の詳細」の「保存」をクリック
11.「閉じる」をクリック
ここまで実施すると、「taxonomy.json」の内容が自動的に更新されます。
タクソノミーの設定が完了したので、作成したタクソノミーを読み込みましょう。
その前に、ワークフロー作成の準備をします。
Main.xamlを開き、シーケンスアクティビティを配置しておきましょう。
さて、ここからDocument Understandingのアクティビティを使っていきます!
ワクワクしますね(#^^#)
- アクティビティパネルで「IntelligentOCR」と検索する
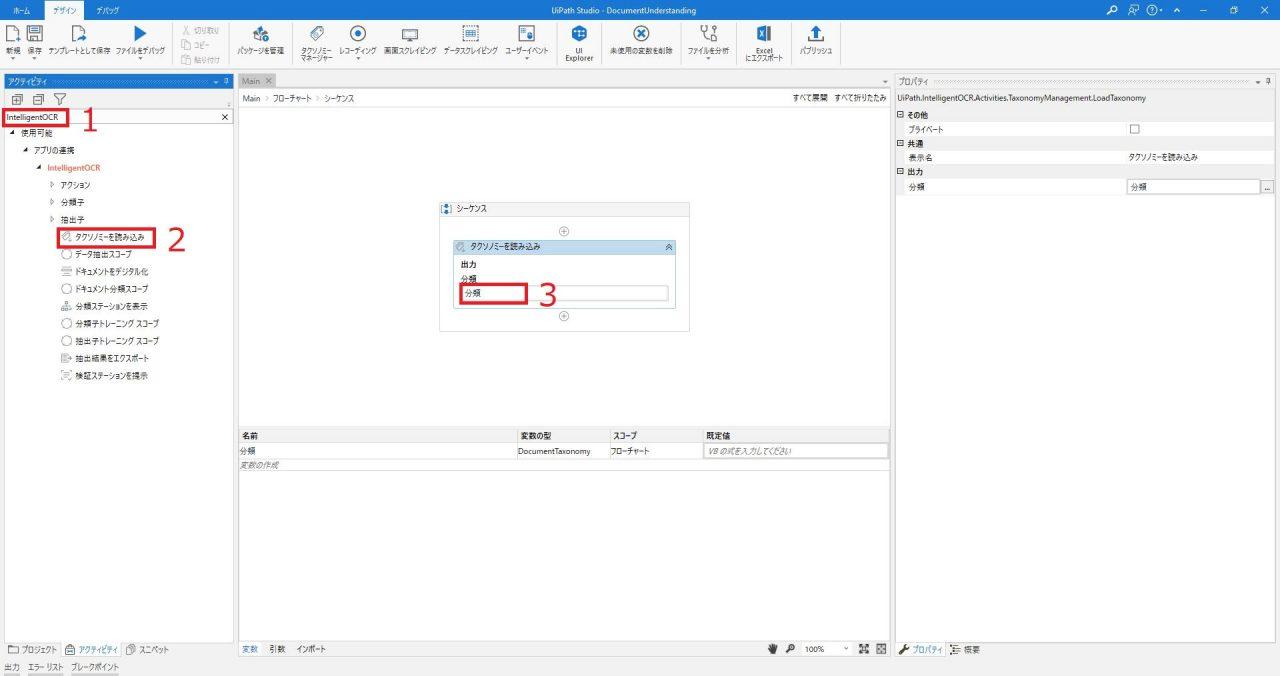
Document Understandingに使用できるアクティビティたちが現れます…! - 「タクソノミーを読み込み」アクティビティを追加
(Mainフローにドラッグアンドドロップ あるいは アクティビティをダブルクリック)
このアクティビティは、「taxonomy.json」を読み込むことができるアクティビティです。 - 読み込んだタクソノミーを出力する変数を作成し、指定する。
「分類」に変数を指定します。
(「分類」の入力フォーム箇所をクリックし、
右クリック→「変数の作成」 あるいは、Ctrlを押しながらk ボタンを押すと、
出力される型に合った変数を作成することができます。)
指定する変数はDocumentTaxonomy型となっています。
PDFやWord、その他のファイルをUiPathが読み取れるようにデジタル化します。
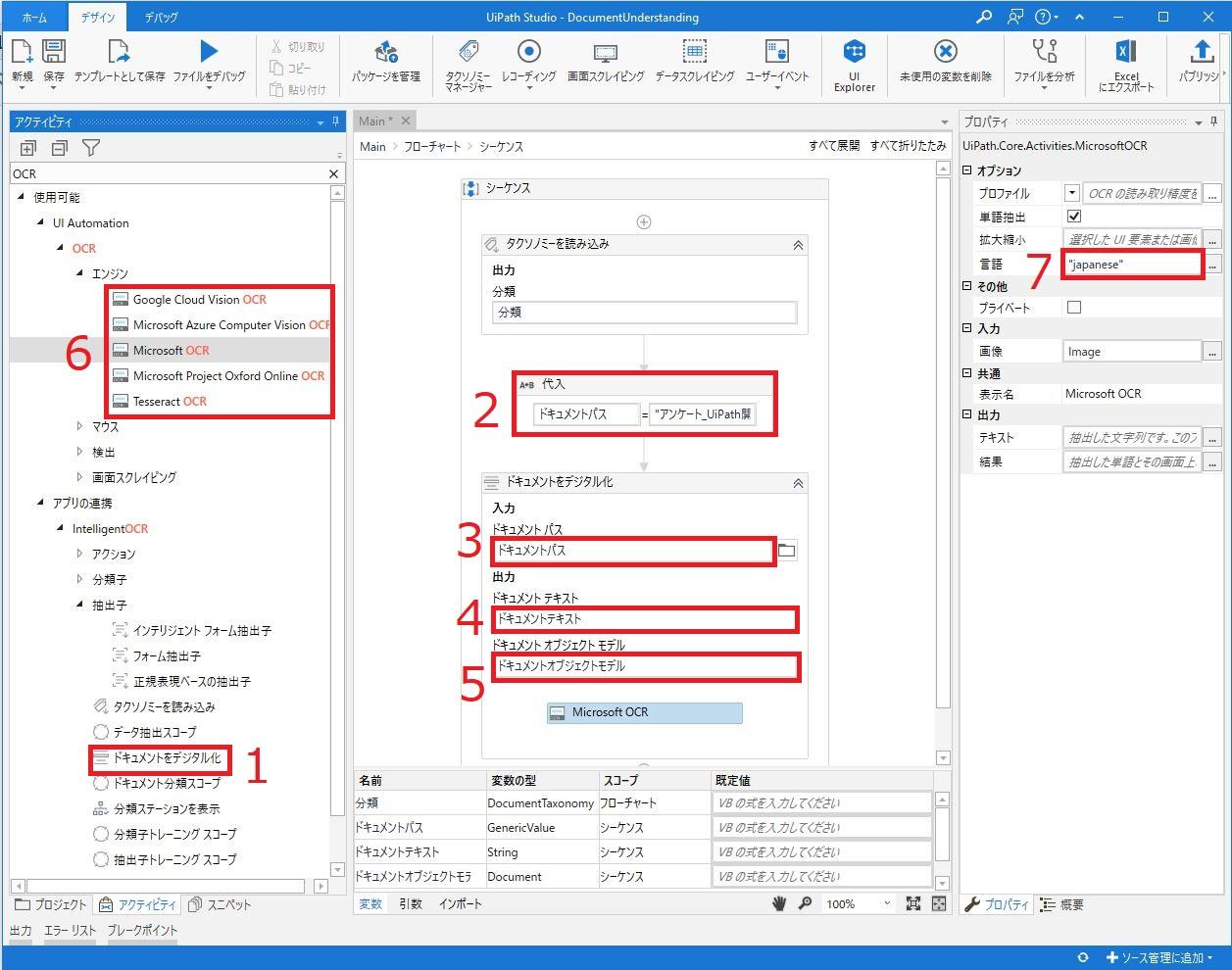
- 「ドキュメントをデジタル化」アクティビティを追加
- その上に「代入」アクティビティを追加
文章を抽出したいドキュメント(回答が記入されているもの)のパスを右辺に入れ、
変数を作成し、左辺に入れる - 「ドキュメントパス」に上記で作成した変数を指定
※ 文章を抽出したいドキュメントのパスは後ほど、再度使用するため、
変数を作成し、使いまわしやすいようにしています。 - 変数を作成し、「ドキュメントテキスト」に指定
こちらには、読取対象ファイルのOCR読取の結果が格納されます。
指定する変数はString型となっています。 - 変数を作成し、「ドキュメントオブジェクトモデル」に指定
こちらは、ドキュメント内容の位置等の情報が出力されます。
指定する変数はDocument型となっています。 - OCR読み取りに使用するエンジンを指定
アクティビティパネルで「OCR」と検索すると、
「OCR」→「エンジン」内に使用できるOCRエンジンが現れるのでいずれかを選択し、
「ドキュメントをデジタル化」アクティビティでOCRエンジンを指定します。 - 言語を日本語に指定
プロパティパネルの「オプション」→「言語」で
「”japanese”」と指定します。
いよいよ、ドキュメントからデータを抽出していきます!
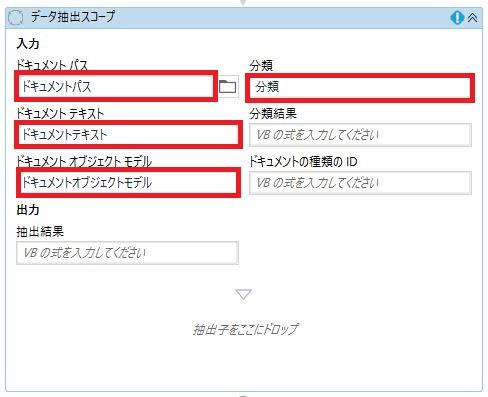
- 「データ抽出スコープ」を追加する
- 「3. タクソノミーを読み込む」「4. ドキュメントをデジタル化する」で作成した変数を以下に指定
ドキュメントパス
ドキュメントテキスト
ドキュメントオブジェクトモデル
分類
3.タクソノミーマネージャーを開き、対象のドキュメントの種類をクリックする
「ドキュメントの詳細の種類」において存在する、「ドキュメント種類ID」の項目をコピーする
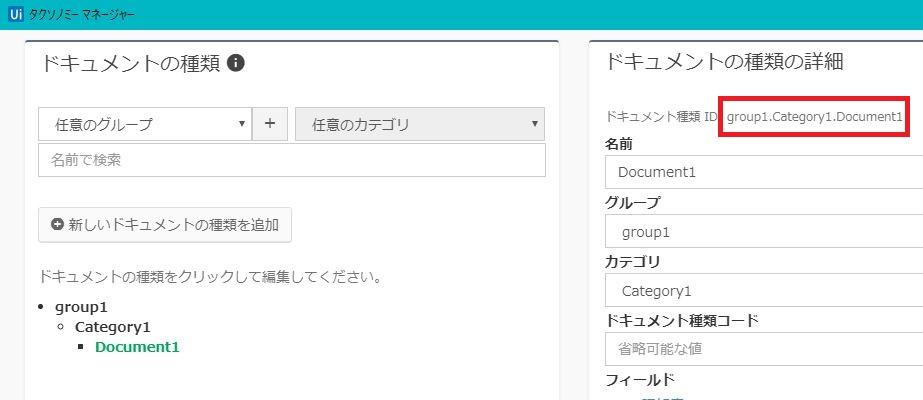
4.「ドキュメントの種類のID」に上記の「ドキュメント種類ID」を指定する
(ダブルクォーテーションを付与することを忘れずに!)
5.変数を作成し、「抽出結果」に指定
こちらは、ドキュメントから抽出した結果が出力されます。
指定する変数はExtractionResult型となっています。
6.抽出子の指定(複数指定可)
IntelligentOCRの「抽出子」にあるアクティビティを選んで配置する。
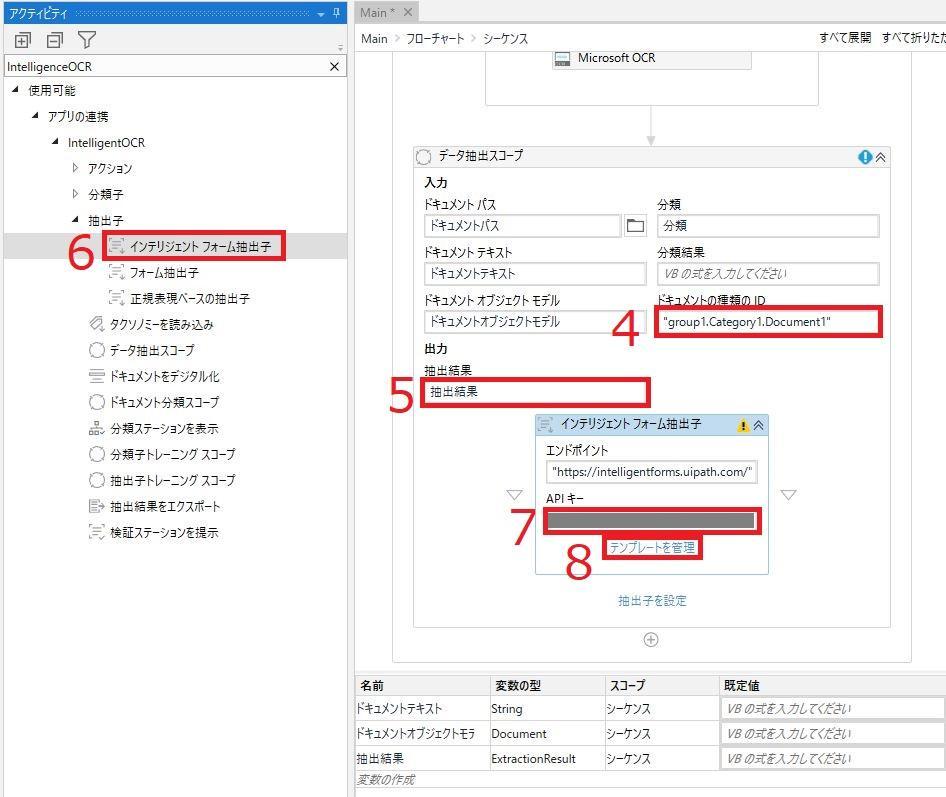
手書きの固定フォーム用の抽出子。
固定テンプレートを持つドキュメント用のデータ抽出子。
PDFの活字のみの場合等に向いている。
正規表現を使用して文字を抽出したい場合に用いる。
7.「APIキー」を入力
一旦、Orchestratorに情報を送る際にAPIキーを使用します。
APIキーの取得方法は以下となります。CloudPlatformの「管理者」タブ
→ライセンス
→その他のサービス
→Document Understanding「新しく生成」
→「APIキーをコピー」
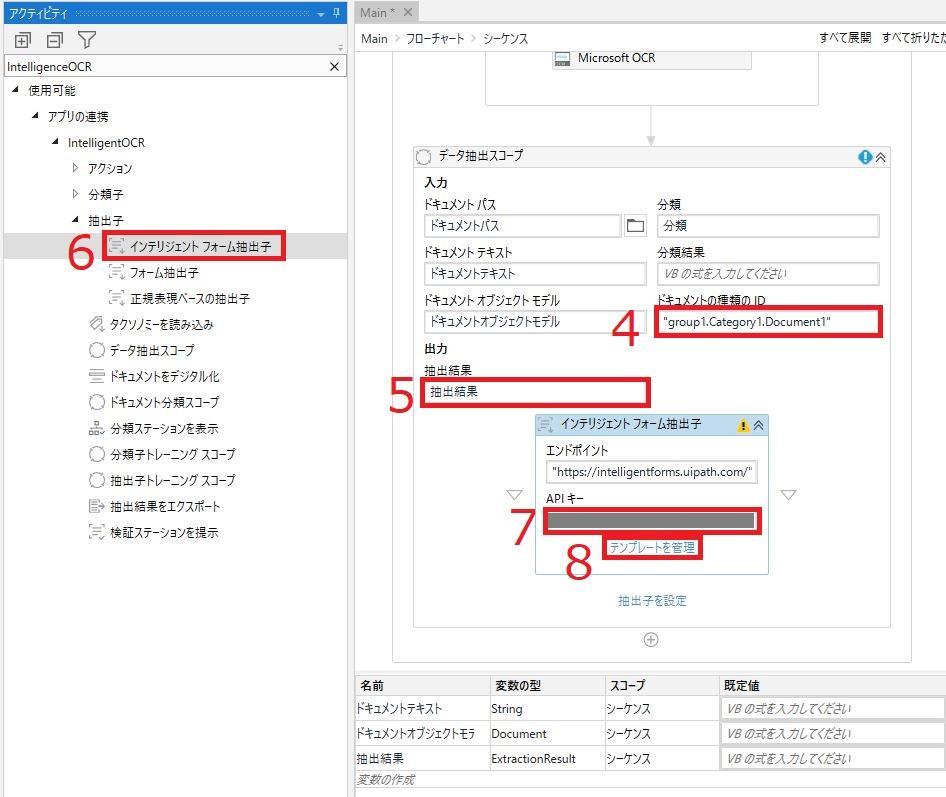
8.「テンプレートを管理」をクリック
9.テンプレートマネージャーが開かれる
10.「テンプレートを作成」をクリック
11.「ドキュメントの種類」を選択
「タクソノミーマネージャー」で作成した、対象のファイル種類を選択
12.「テンプレート名」に入力
テンプレートに名前を付ける
13.「テンプレート ドキュメント」を選択
結果の記入されていない、テンプレートのドキュメントを読み込む。
テンプレートが無い場合は入力済みのドキュメントでもよいが、
テンプレートのドキュメントを読み込んだ方が精度が向上する。
14.「言語」を選択
「jp」と記載
(バージョンによっては選択するタイプになっているので、その場合には日本語を選択する。)
15.「OCRを強制適用」を選択
読み込み対象テンプレートのファイルが手書きと決まっている場合等、
16.「設定」をクリック
17.OCRを適用させたい場合、チェックを入れる。
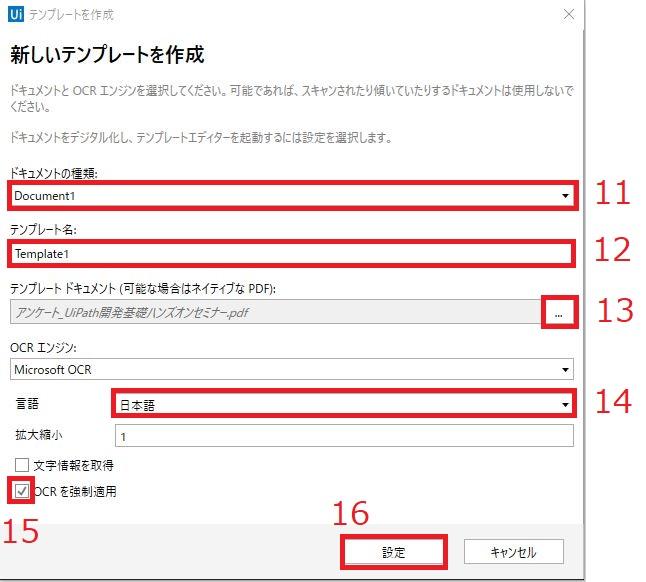
18.ドキュメントがデジタル化される
19.手順等の説明が表示されるため、「OK」をクリック
20.「テンプレートマネージャー」が表示される
21.「ページ1の一致情報」があれば、文字を指定し、「+」ボタンをクリック
対象ページ固有文字(他ページと共通の部分でない箇所)を指定する。
複数条件を指定するためには、
Ctrlを押下しながら対象文字(赤枠で認識されたものが使用できる)を複数(5つ以上)クリックする。
ページが複数存在する際に、各ページを見分ける為に使用する。
文字列とその位置で判断している。

22.上記について、2ページ目以降も同様に指定
23.フィールド情報存在位置の指定
「タクソノミーマネージャー」で作成した、値が存在する箇所を囲い、
対象のフィールドの「+」ボタンを押下します。
この操作を必要なフィールド分だけ繰り返します。
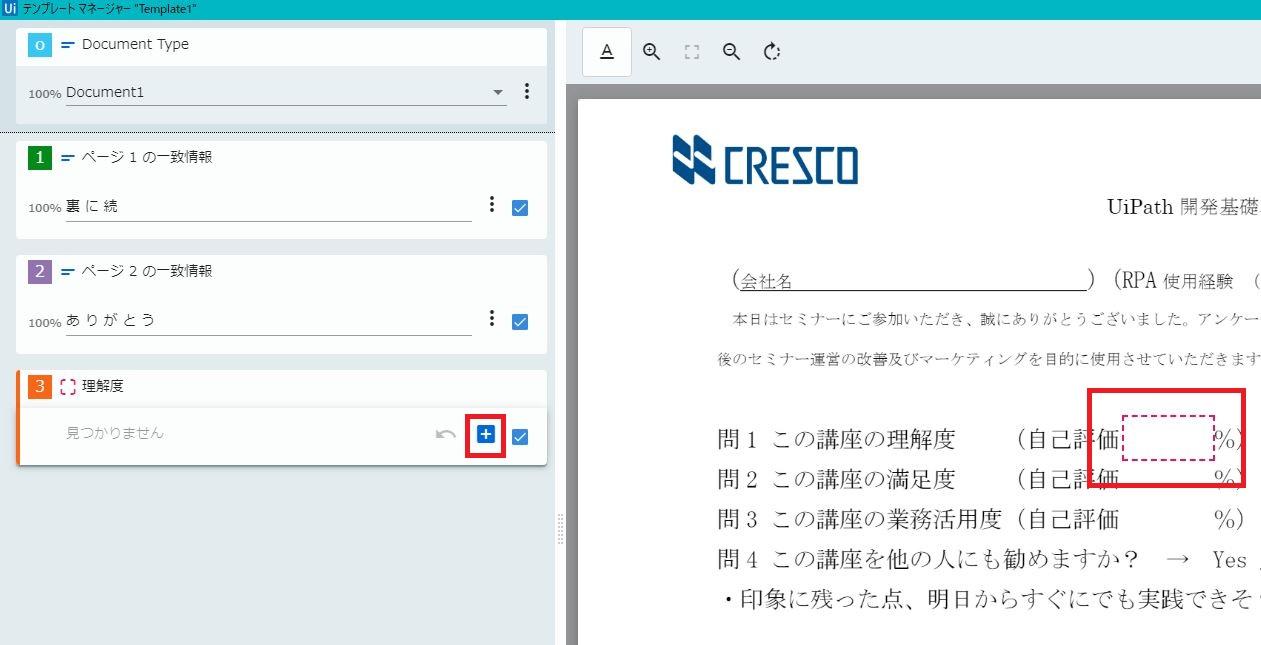
24.「保存」ボタンをクリック
25.ドキュメントの設定画面が現れる
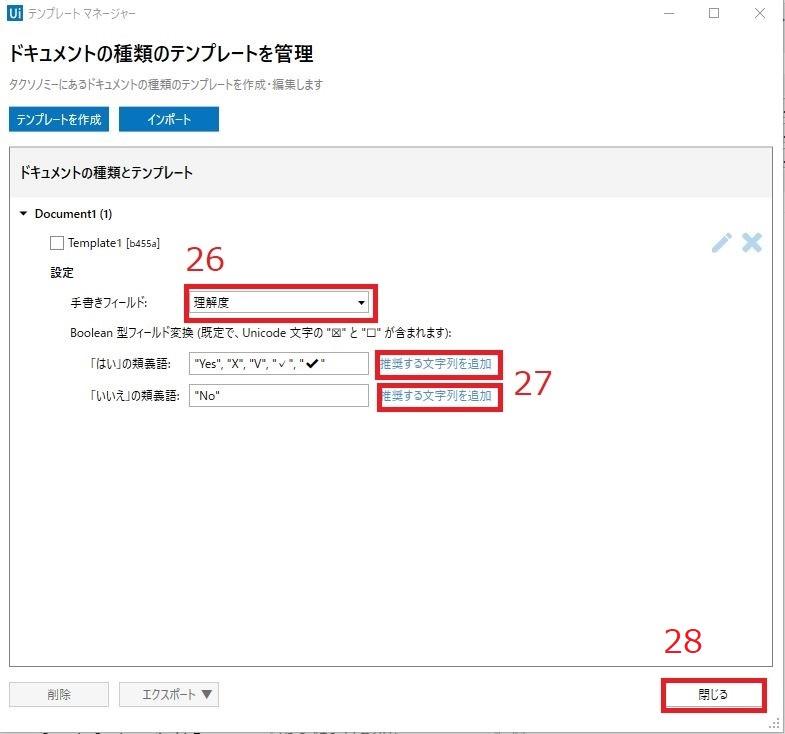
26.「手書きフィールド」を選択
手書きの箇所がある項目について、チェックボックスにチェックを入れる
※ Community Licenseの場合は1ドキュメントにつき5つまで使用できます
27.「Boolean型フィールド変換」を入力
回答表記のぶれを補正できる項目です。
「「はい」の類義語」、「「いいえ」の類義語」それぞれに対し、
「推奨する文字列を追加」をクリックすると、自動的に値が入ります。
フォームに記載された文字等を「はい」や「いいえ」として認識してくれるようになります。
追加も可能です。 例:黒塗りの四角(”■”)等
28.「保存」をクリック
バージョンによっては、「保存」がない場合もあります。
「閉じる」がある場合はクリックしてウィンドウを閉じます。
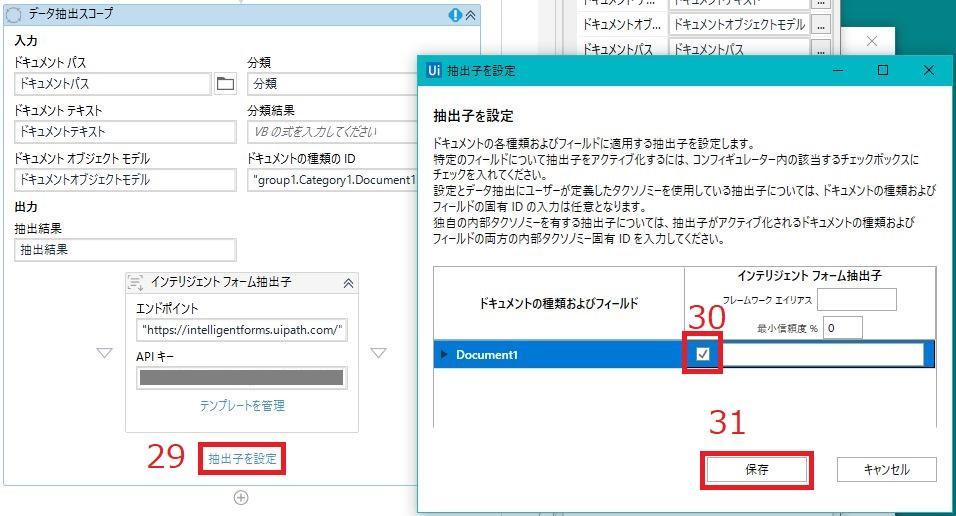
29.「抽出子を設定」をクリック
30.「抽出子を設定」ウィンドウが開くので、抽出に使用したい抽出子にチェックを入れる
抽出する項目ごとに、どの抽出子を使用するか設定できる項目です。
今回はインテリジェントフォーム抽出子のみ使用したので、全てインテリジェントフォーム抽出子にチェックを入れます。
31.「保存」をクリック
ロボットが抽出した内容について、人間が検証を行うアクティビティです。
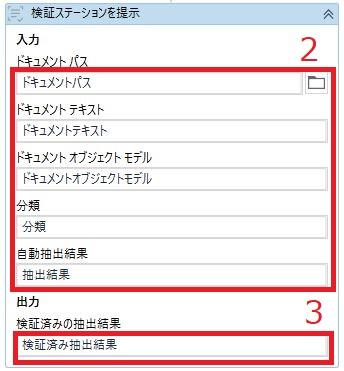
- 「検証ステーションを提示」アクティビティを追加
- 「3. タクソノミーを読み込む」「4. ドキュメントをデジタル化する」「5. データを抽出する」で作成した変数を以下に指定
ドキュメントパス
ドキュメントテキスト
ドキュメントオブジェクトモデル
分類
自動抽出結果(「データ抽出スコープ」の「抽出結果」が格納されている変数を指定) - 変数を作成し、「検証済みの抽出結果」に指定
ロボットを実行すると、自動抽出結果が表示されるので、
その結果を人間が見て、人間が修正した抽出結果を出力する項目。
抽出結果をDataSet型に変換してくれるアクティビティです。
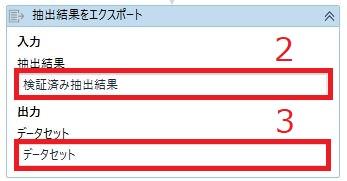
- 「抽出結果をエクスポート」アクティビティを追加
- 「検証済み抽出結果」に「6. 検証ステーションを提示」で出力した変数を指定
- 変数を作成し、「データセット」に指定
検証済み抽出結果をExcel等に出力する場合は、DataSetをDataTable型に変換する必要があります。
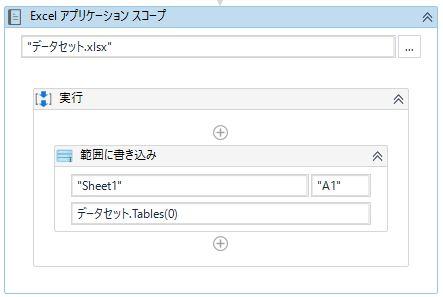
- 「代入」アクティビティで型変換
データセットはDataTableのリストに変換でき、
その中の1番目の結果を DataSet.Tables(0) にて変換できます。 - ファイル等に出力
Excelに出力する場合は、Excel Application Scope を用いて
「範囲に書き込み」アクティビティで出力します。
さて!これにて実装は完了です(^.^)
実行してみましょう。
実行すると、自動抽出結果が正しいか確認する、検証ステーションウィンドウが開かれます。
内容が正しければ「OK」を押下します。
のはずでしたが!
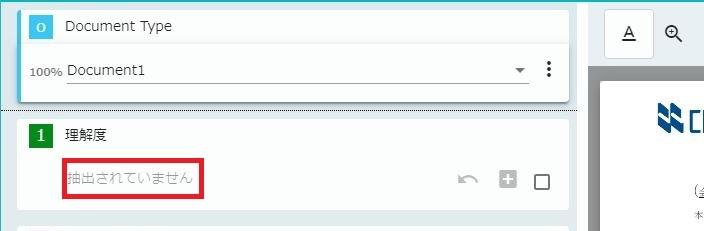
むむむ、今回はうまく読み込めていないようです・・・!
完全ではないロボットくん、たまにはこんなこともあります!!
ちょうどよい機会なので、うまく読み込めなかった場合の操作をお教えしましょう!
(前向きに捉える!笑)
- 対象の文字列にマウスを当てると、文字が点線の赤枠で囲まれるので、そこでクリック
- プラスボタンをクリック

3.指定した文字が入力される

4.必要なフィールド分行い、保存ボタンをクリック
どのような感じで出力されるか、見てみましょう。
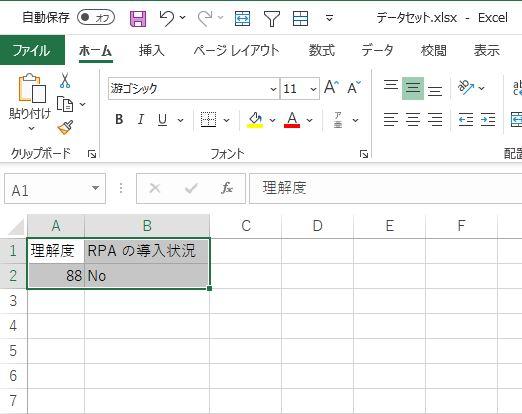
おおー、1ドキュメントから抽出した内容は、1行に書き出されるんですね(^^♪
このExcelを使って、1行ごとの繰り返し処理を行えば、後続の処理も自動化されますね!
また、今回作成した「代入」以降の一連の動作に対して繰り返し処理を行い、
フォルダに入っているファイル全てに対して処理を行う、等ができそうですね(^^)/
ロボットがドキュメントを分類してくれるアクティビティもあるようです!
ドキュメントがどのタクソノミーなのかを自動的に判断してくれるようです。
今回ボリュームが大きくなってしまったので詳しくはまた今度、にしたいと思います(^^)
他にも、分類子や抽出子をトレーニングできるアクティビティもあるみたいです。
気になったら調べてみてくださいね!
まず、
UiPath Document Understanding、すごい。
何がすごいって、
「OCR製品組み込みました、はいおわり」、ではなくて
結果に誤りがあればその都度人間が修正することができることとか、
学習させて精度を上げる機能があるところとか、
パッと見てどういった操作をすればよいかすぐわかるところとかです。本当に実装しやすいです。
精度に関しては、私の使用したテンプレートが良くなかったのか、ちょっとイマイチだったのですが、
参考にしたデモを見ると、手書きでもしっかり認識されています!
アンケートの作り方に関しては、
回答を記入してもらう枠を明確に指定する、
Excelで作成する(今回はWordで作成したので精度が低かった?)
等、人間の方でも少し努力が必要かもしれませんね。
このあたりについては、他のOCR製品を組み込んだ時にも努力しなくてはならないところではあるので、
うまく使えばコストカットにつながるのでは・・・?とも感じました。
精度については少し研究してみようと思います!
ロボットくんと会話しているようで、私もたのしいです )^o^(
以上、やまさきあのお送りする
紙書類が多くてRPA化に困ってるあなたにおすすめの「UiPath Document Understanding」の使い方 でした!
最後まで読んでいただき、ありがとうございました!!
