


今年のアドベントカレンダーでは、AWS X-Ray の紹介をします。
実際にアプリケーションを動かしながら、X-Ray の活用方法を見ていきたいと思います。
AWS X-Ray は、アプリケーション(以下アプリ)の分析やデバックを行うことができる AWS のサービスです。特徴は、アプリ全体の動きをトレースすることができる点で、ユーザのリクエストに対してエンドツーエンドでの分析が可能です。
似たようなサービスに Amazon CloudWatch があります。CloudWatch は各 AWS サービスのログの管理やリソースのメトリクス監視を通じて、アプリの動きを個々の単位で見ることができます。
一方で X-Ray は、アプリをサービスマップと呼ばれるグラフから全体のパフォーマンスを捉えることができ、各リソースのレイテンシーの検出や障害の発生率の特定など、アプリを 「診る」 ことができます。
今回は、以下の構成からなるアプリに X-Ray を組み込んだ場合の動きを見ていきます。
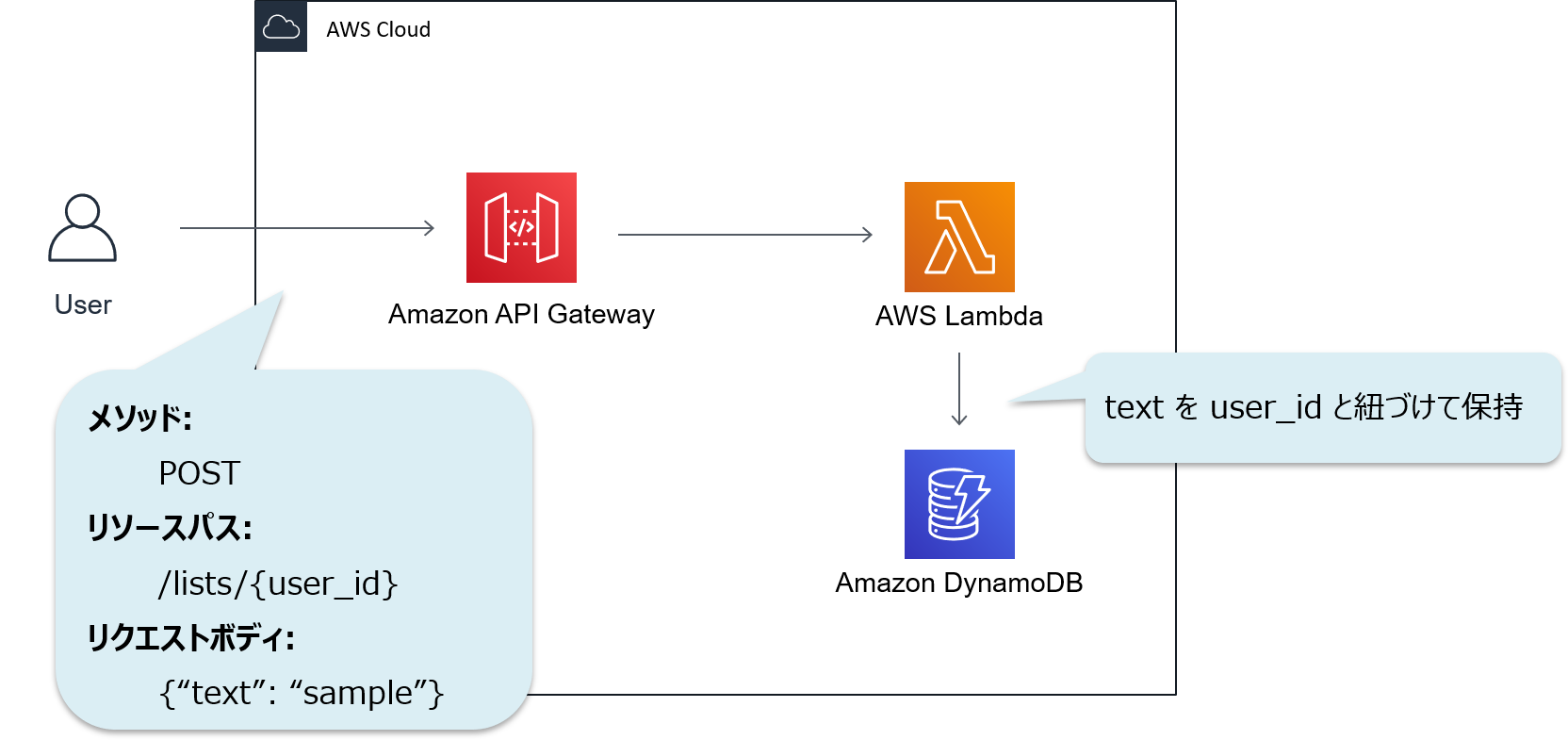
Amazon API Gateway, Amazon DynamoDB, AWS Lambda で構成されるサーバレスアプリケーションの一般的な構成です。
- 言語
- Python 3.8
- AWS CloudFormation
- AWS SAM
アプリのソースコードは以下にあります。以降の説明は、以下のアプリに沿って行います。
API Gateway および Lambda でX-Rayを有効にするには、以下の内容を記述します。
| Globals: |
| Function: |
| Timeout: 10 |
| Tracing: Active # LambdaでのX-Ray有効化 |
| Api: |
| TracingEnabled: True # API GatewayでのX-Ray有効化 |
Lambda にはX-Rayへのアクセス権限を追加します。
| ManagedPolicyArns: |
| - 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess' |
| - 'arn:aws:iam::aws:policy/AWSXRayDaemonWriteAccess' # X-Ray の権限追加 |
X-Ray の計測はセグメントと呼ばれる単位で行われます。セグメントにはAWSリソースの名前やリクエストの情報が入ります。
X-Ray を有効化することで、API Gateway と Lambda のセグメントは自動的に作成されます。
ここで注意したいのが、Lambda のセグメントです。Lambda のセグメントは、Lambda サービスのセグメントと関数によって行われたセグメントの2つが自動的に作成されます。そのため、サービスマップ上で Lambda のノードが2つ表示されます。詳細は以下のリンクに記載があります。
DynamoDBのセグメントは、X-Ray SDK for Python を使用して AWS SDK にパッチを当てることで自動的に作成されます。以下のように patch_all() を呼び出すことで、X-Ray SDK が対応しているライブラリすべてにパッチを適用することができます。
| from aws_xray_sdk.core import patch_all |
| patch_all() |
対応しているライブラリの一覧は以下のリンクに記載があります。
Lambda 関数に割り当てられたセグメントをサブセグメントに分割することで、詳細な分析を行うことができます。
Lambda は X-Ray を有効にした時点で、Initialization、Invocation および Overhead のサブセグメントに分割されます。自前でサブセグメントを追加する場合は、Invocation の中に作成することができます。
以下が、自前のサブセグメント(カスタムセグメント)のコードの抜粋になります。
@xray_recorder.capture("parse_event") のデコレータを関数に指定することで、その関数に関わる処理をサブセグメントにすることができます。"parse_event" はサブセグメントの名前です。
| @xray_recorder.capture('parse_event') |
| def parse_event(event): |
| body = json.loads(event["body"]) |
| path_params = event["pathParameters"] |
DynamoDB にかかわるサブセグメントは、AWS SDK の put_item 関数側で作成されるため、デコレータの記載はいりません。
| def put_todo(user_id, text): |
| dynamo_db = boto3.resource("dynamodb") |
| table = dynamo_db.Table(RESOURCE_PREFIX + "-table") |
| table.put_item( |
| Item={ |
| "UserID": user_id, |
| "CreateDate": datetime.utcnow().isoformat(), |
| "text": text |
| } |
| ) |
作成されたAPIにリクエストを投げるとサービスマップが作成されます。
各リクエストは、サンプリングルールに従ってトレースとして保存されます。
サンプリングルールは、プログラム上で特に指定しない限りはデフォルト設定が適用されます。
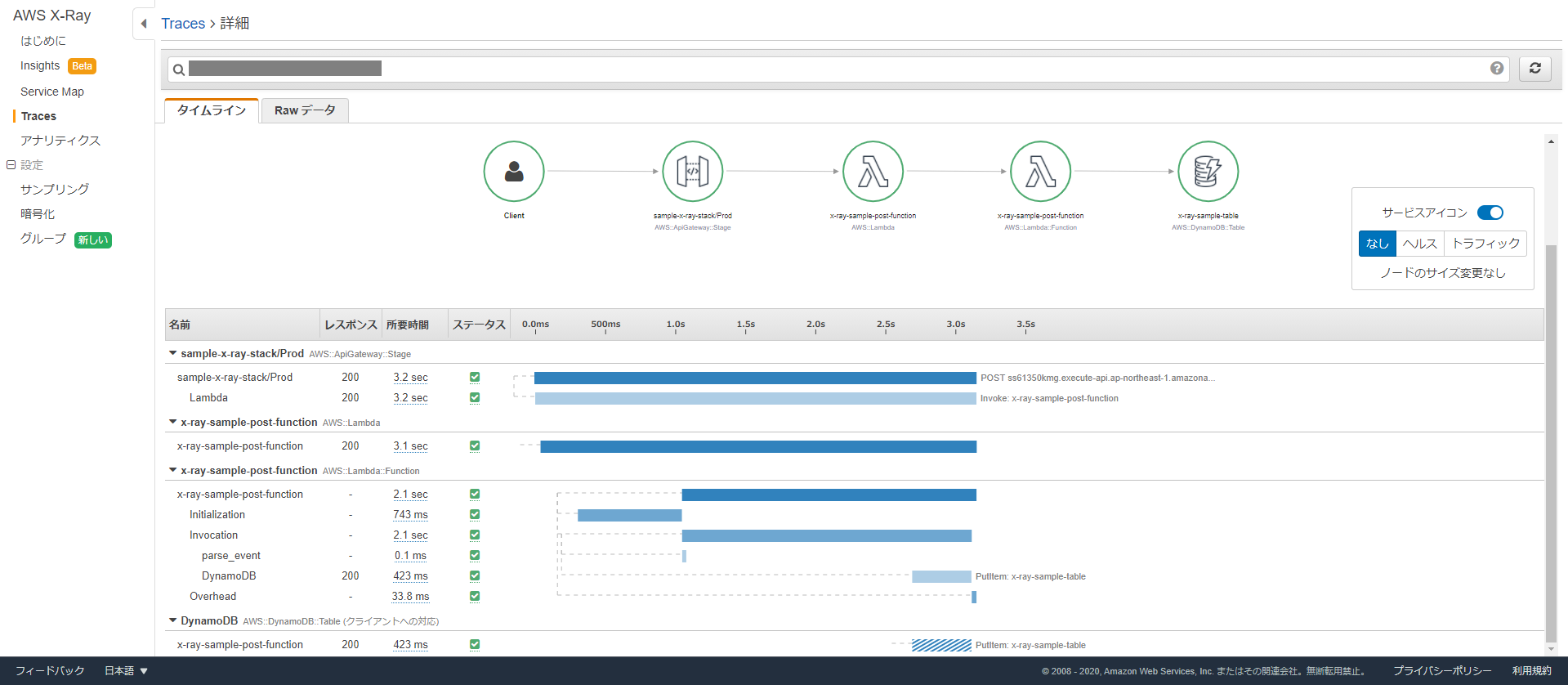
セグメント一つ一つのサービスマップのノードに対応します。(今回はclientを除く4つ)
セグメント、サブセグメントごとに計測された処理時間が、グラフで表示されます。
今回のアプリだと、クライアントからリクエストを受け取って返却するまでに3.2秒かかっており、
そのうちの大半処理が Lambda でかかっていることが一目で分かります。
今度は、あえてリクエストのパースに失敗する処理(空のリクエスト)を送った場合の動きを見てみます。
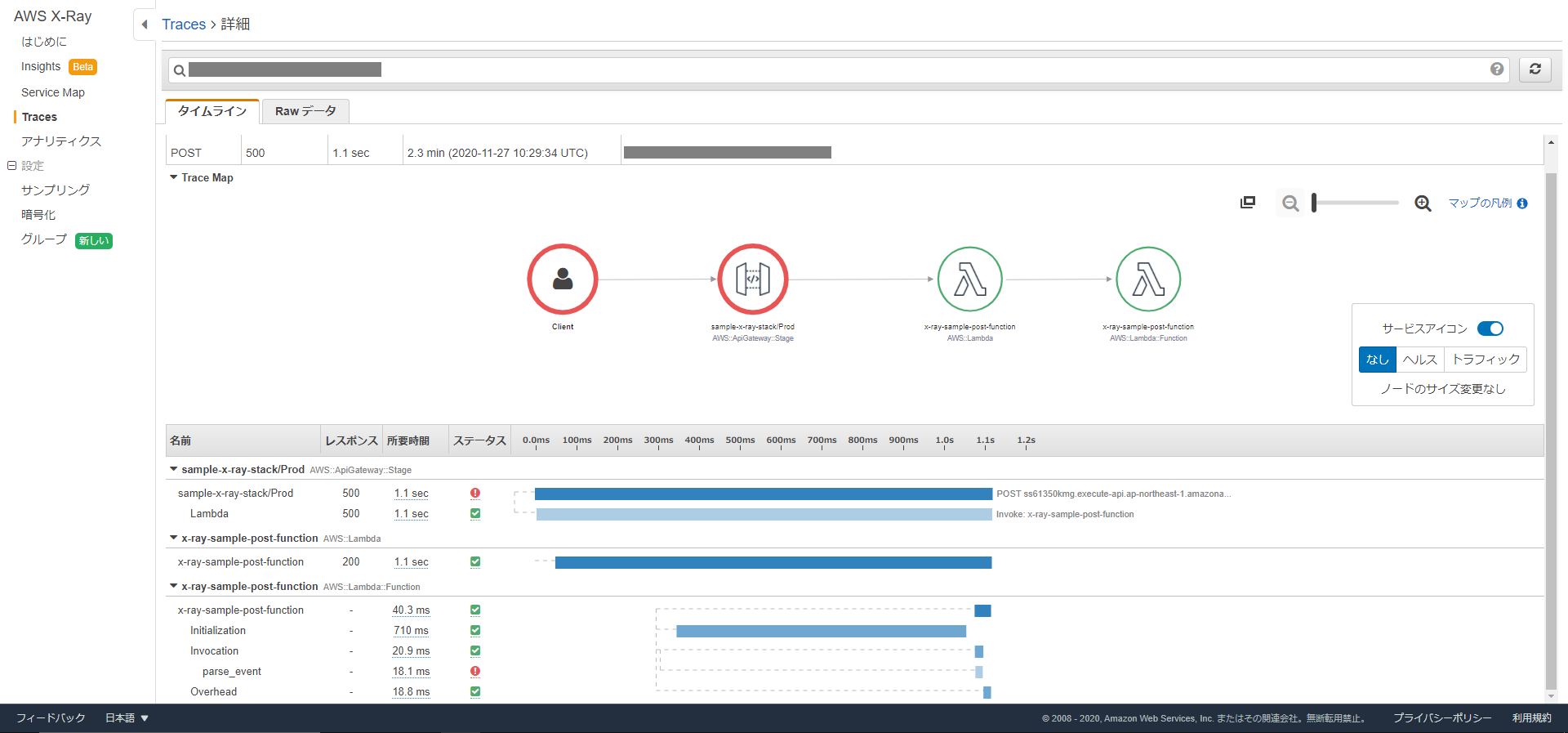
処理に失敗したセグメントが赤く表示されており、Lambda の parse_event のサブセグメントで失敗していることがすぐに確認できます。
上の例だとトレースは少ないですが、実際の環境だと多くのトレースがあります。多くのトレースから、例えば、ユーザ毎、リクエストの内容毎にトレースを分析したい場合は、注釈をつけることで簡単にフィルタをすることができます。
また、エラー発生時の詳細などを簡単にデバックするために、セグメントに詳細な情報をメタデータとして付与することができます。
以下のコードは、parse_eventセグメントに注釈とメタデータを付与するコードになります。
今回は、user_idを注釈、textをメタデータとして付与しています。
| @xray_recorder.capture('parse_event') |
| def parse_event(event): |
| body = json.loads(event["body"]) |
| path_params = event["pathParameters"] |
| if body is None or path_params is None: |
| raise Exception |
| text = body.get("text") or "No Text" |
| user_id = path_params.get("user_id") or "No User" |
| segment = xray_recorder.current_subsegment() |
| # user_id を注釈としてセグメントに追加 |
| segment.put_annotation('user_id', user_id) |
| # text をメタデータとしてセグメントに追加 |
| segment.put_metadata('text', text) |
| return (user_id, text) |
注釈はトレースのフィルタに使用できますが、メタデータは使用することができません。
また、注釈はキーとそれに対応する値を50個までしか保持できませんが、メタデータは、任意のタイプの値を持つキーと値のペアを保持することができるため、より柔軟なデータをセグメントに与えることができます。
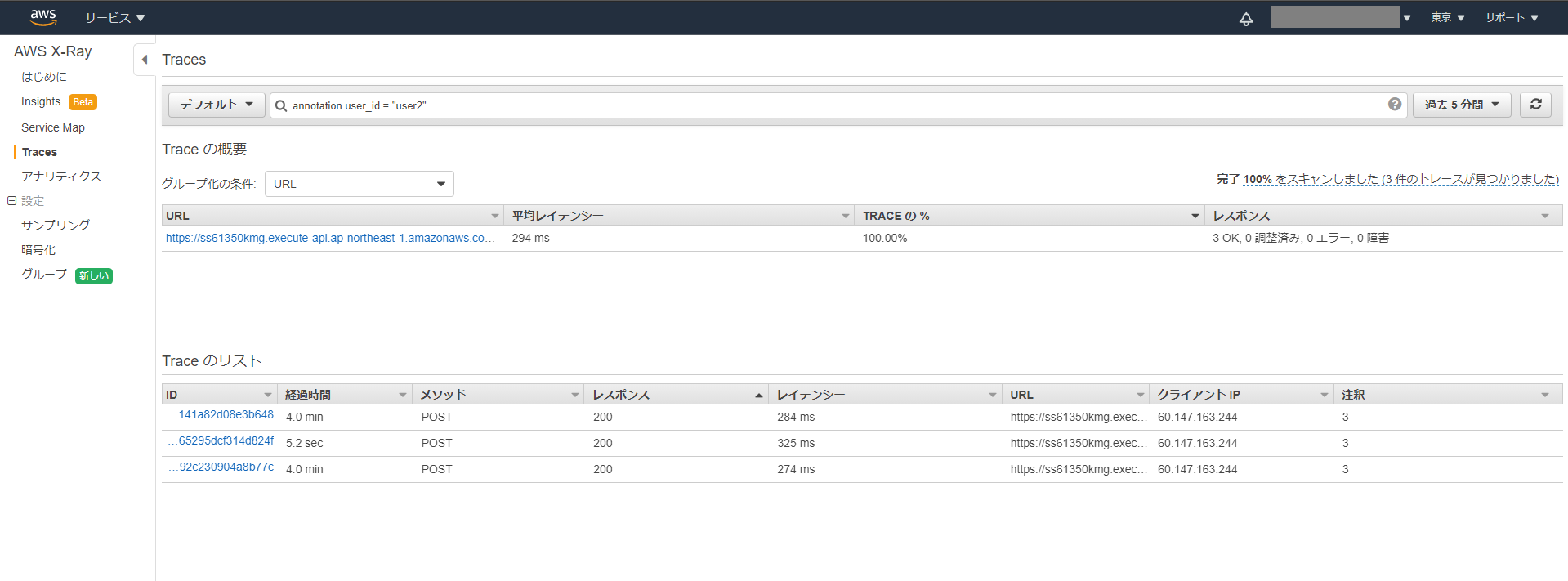
注釈を用いてトレースのフィルタを行う際は、annotation. = の形式でフィルタを行います。以下の例では、user_idが"user2"のトレースのみが表示されています。
メタデータは、セグメントの詳細画面から見ることができます。以下は、parse_eventサブセグメントのメタデータが表示されています。
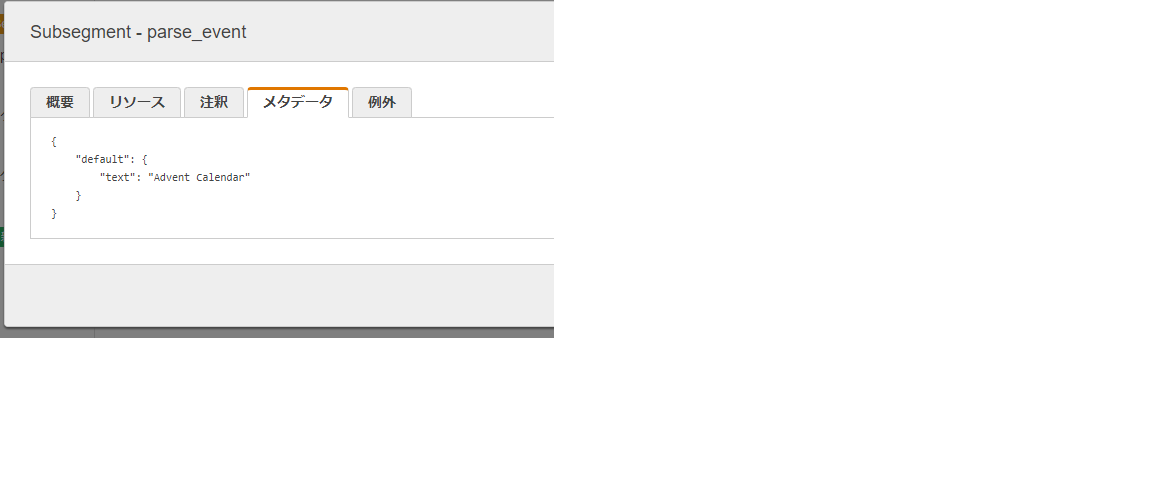
X-Ray を利用することで、アプリ全体のパフォーマンスを一目で確認することができます。
また、注釈やメタデータをセグメントに付与することで詳細な分析が可能です。
今回は Lambda の例を紹介しましたが、 EC2, Elastic Beanstalk, ECS など様々サービスとも簡単に連携できます。
また、CloudWatch の ServiceLens と呼ばれるサービスから X-Ray の情報も見ることができます。
CloudWatch でアプリを見るだけでなく、X-Rayを活用してアプリを診てみるのはいかがでしょうか。
以上です。
