


技術研究所 (技研) のまつけんです。
リモートワークが増えたことで、会社に領収書やレシートの写真を提出することが多くなりました。紙のレシートを、スキャナやスマホで電子化する (画像ファイルにする) と、不必要に高精細な画像になってしまうことが多いように感じます。そこで、今回は、レシートの写真を自動で、文字が判読できる範囲内で縮小する (解像度を落とす) Pythonプログラムを作成してみました。機械学習などは使わず、OpenCVとNumPyだけで画像処理によって実現しています。
手許にあるレシートをスマホで撮影したものを用います (個人名や支店名などはモザイク処理しています)。左が処理前 (1703×3279ピクセル、925キロバイト)、右が処理後 (224×431ピクセル、40キロバイト) です:
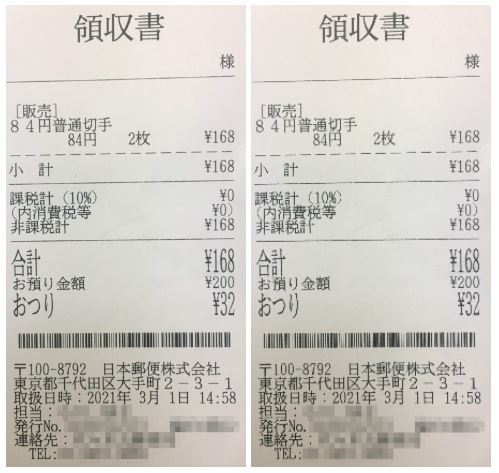
拡大すると、解像度が落ちていることを確認できます:

まず、映っている文字のサイズを調べる必要があります。この部分については、Qiitaに「OpenCVをPythonで文字の場所をレシートから取得する」という記事がありましたので、こちらをほぼそのまま使いたいと思います。検出結果は以下の通りとなります:

文字を緑色の長方形で囲う処理が行われますが、行間が狭いためか、複数行にわたる長方形も描画されています。
文字サイズを推定するには、描画された長方形の高さの最頻値を調べれば良さそうです。長方形の座標は rect = cv2.boundingRect(contour) の部分で求めていますので、これをlistに保存するよう改造します。具体的には、以下のように rects = [] と rects.append(rect) を追加するだけです:
| rects = [] # 追加: 空のlistをつくる |
| if len(contours) > 0: |
| for i, contour in enumerate(contours): |
| rect = cv2.boundingRect(contour) |
| if rect[2] < 10 or rect[3] < 10: |
| continue |
| rects.append(rect) # 追加: listに登録する |
| area = cv2.contourArea(contour) |
| if area < min_area: |
| continue |
| cv2.rectangle(tmp, (rect[0], rect[1]), (rect[0]+rect[2], rect[1]+rect[3]), (0, 255, 0), 2) |
ループ終了後に、rectsから高さだけを取り出し、表示してみます:
| heights = np.array(sorted([h for _, _, h, _ in rects])) |
| print(heights) |
結果は、
| [ 14 14 15 15 15 15 15 15 15 17 19 22 27 34 |
| 35 35 35 36 36 36 36 37 37 39 40 40 42 42 |
| 45 45 49 49 50 51 53 54 55 58 71 71 75 75 |
| 75 75 76 76 76 76 76 76 77 77 78 84 84 88 |
| 93 97 97 98 99 99 99 100 100 100 101 101 101 102 |
| 103 107 121 138 146 153 154 156 156 186 191 196 199 204 |
| 208 209 211 213 334 356 578 613 676 840 1301 1588 1600 1625] |
となります。どうやら、75~80 (ピクセル) くらいが最頻のようです。よって、最も多い文字サイズは75程度ではないかと予想されます。誤差を考慮すると、このまま最頻値を求めるのではなく、5くらいの値で割ってから最頻値を求めた方が良さそうです。
| n = 5 |
| heights_n = (np.array(heights) / n).astype('i') |
| keys = sorted(list(set(heights_n))) |
| cnts = [len(np.where(heights_n == k)[0]) for k in keys] |
| size0 = keys[np.argmax(cnts)] * n |
| print(size0) |
この結果は75となるので、75 ~79 (ピクセル) が最頻と求まりました。続いて、条件にあう長方形の高さの平均値を求めます:
| heights = heights[np.where(size0 <= heights)] |
| heights = heights[np.where(heights < size0 + 5)] |
| size0 = np.mean(heights) |
| print(size0) |
厳密には、長方形の幅で重みづけをして平均するなどの方法が考えられますが、今回はシンプルに平均を計算しました。結果は、76.0でしたので、これを「最も多い文字サイズ」とします。
縮小後の文字サイズを指定し、倍率を計算します。今回は、10 (ピクセル) としました:
| size1 = 10 |
| m = size1 / size0 |
| print(m) |
この結果は、約0.13なので、元の13%に縮小すると丁度良いということになります。cv2.resize() で縮小し、cv2.imwrite() で書き出せば完成です:
| h, w = img.shape[: -1] |
| img1 = cv2.resize(img_org, (int(w * m), int(h * m))) |
| cv2.imwrite('out.jpg', img1) |
如何でしょうか? 文字を検出し、文字サイズを推定して、縮小率を計算し、縮小するという処理で、自動的に縮小することが出来ました。他のアプローチとしては、フーリエ変換を使って空間周波数を割り出すことで、最適な縮小率を求めるということも考えられますので、いずれ機会があれば、試した上で紹介したいと思います。
