


こんにちは、技術研究所のウエサマです。
技術研究所では、研究テーマのひとつとして機械学習をどのように事業へ適用していくか調査を行っており、各種の機械学習について主に使う側の視点で調査を行っております。
こうしたなか本年7月クレスコはWatsonを活用しpepperをはじめとするロボット、モバイル、パソコンに対応する様々なWatsonアプリケーション開発を行うことを、ソフトバンクと共にプレスリリースを行いました。
このエントリーでは記事を前後編に分け、機械学習を採用したIBM Watson APIのひとつであるNatural Language Classifierを取り上げます。公式サイトでは日本語はサポート外(執筆時点)となっておりますが、設定をちょこっと変更し日本語を扱ってみます。
前編では分類器の概要とトレーニングデータの準備までを記述します。後編では実際に分類器を作成し日本語でのクラス分けを試してみます。ただし、本来の単純なクラス分けだとつまらないため、なんとなく質問応答になるような使い方で遊んでみたいと思います。
Natural Language Classifier(以下、NLC)は短いテキストを与えると、予め定義されたクラスに分類してくれるというものです。これにより与えられた質問が、どの分野に対する質問なのか判別でき、別の処理へ誘導したり、返答を行うなどユーザからの一般的な質問に対してアプリケーションが適切なユーザ対応を行う際に本機能を利用できます。
現在、公開されているBluemix上のデモでは、天候に関する質問をすると、その質問が”気温”に関するものなのか”天気”に関するものなのか分類してくれます。
デモは下記の質問文とクラスをトレーニングデータとして与えます。(一部抜粋、デモでは50件用意されている)
| 質問文 | クラス |
| How hot is it today? | temperature |
| Is it hot outside? | temperature |
| Will it rain today? | conditions |
| How much snow are we expecting? | conditions |
公開されているNatural Language Classifier のデモ
http://natural-language-classifier-demo.mybluemix.net/
それでは、以下の質問を入力し分類結果を確認してみます。
質問入力:
| How hot is it today? |
出力結果:
| Natural Language Classifier is 98% confident that the question submitted is talking about ‘temperature’. Classification: temperature Confidence: 98% |
なるほど・・・トレーニングデータと同じ質問をすれば、ちゃんと分類できるのは当たり前ですね。でもこれだとルールベースで作ったのと変わらないじゃん。何か嬉しい事があるのだろか??と思ってしまいますが、実はトレーニングデータに含まれていない質問をしても正しく分類することができます。
では、ためしてみましょう。
質問入力:トレーニングデータに台風(typhoon)に関するデータは含まれていません。どうなるかな?
| How much typhoon do we expect? |
出力結果:
| Natural Language Classifier is 98% confident that the question submitted is talking about ‘conditions’. Classification: conditions Confidence: 98% |
おぉぉ、ちゃんと分類しています。しかもConfidenceは98%とかなり自信があるようです。このようにNLCの分類器は、トレーニングデータから関連がありそうな言葉を推測し分類が行えます。
おおよその動作が分かったところでクラスが答えを示すようなデータを作り、なんちゃって質問応答システムを作ってみようと思います。
トレーニングデータとして犬に関する様々な説明と、その説明が示す犬種をクラスとして与え、犬に関する質問を行うと犬種(クラス名)を答えるというものを作ってみます。

上記のように”寒さに強い犬は?”と質問すると”バーニーズ・マウンテン・ドッグ”と答える感じです。ちなみに バーニーズ・マウンテンドッグはスイスの山間部で過酷な気候に耐え得る牧畜犬ですので、これは正解となります。
では、なんちゃって質問応答システムを作りながらNLCの構成手順を確認したいと思います。まずは分類器を構成するためのステップについてです。
分類器の構成は下記の①~④のステップで構成します。
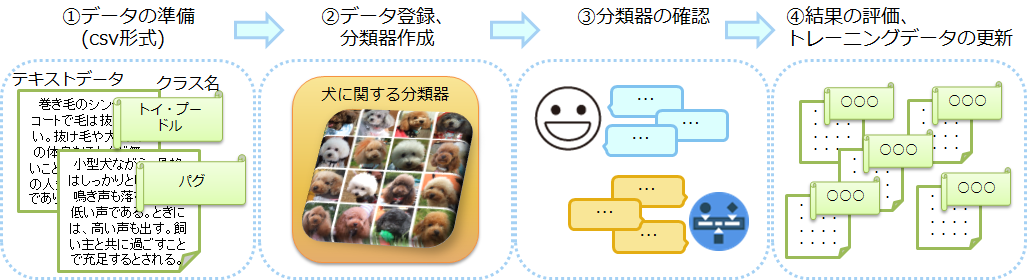
まずはトレーニングデータを準備します(①)。分類器の作成とトレーニングは、準備したCSVファイルをアップロードする事で行われます(②)。次に分類器の精度を確認し(③)、必要に応じて新たなトレーニングデータを与え精度を調整します(④)。現状、新たなトレーニングデータは差分をアップロードするのではなく、①にて作成したCSVファイルにトレーニングデータを追加し、いったん生成済の分類器を削除してからトレーニングを行います。尚、これらの作業は全てAPIを使い行います。
ちょっと注意が必要なのはトレーニングは4回/月まで無料枠ですので、満足の行く状態までトレーニングする場合は注意が必要です。より賢くするにはお金がかかるんですね。
データはCSV形式となり、1行2カラムから構成され1行1データとなります。
| カラム | 項目 | 内容 |
| 1 | 説明テキスト | 質問文とか説明文など設定。 (試すならWikiやネットから集めるのが良いでしょう) |
| 2 | クラス名 | 分類したいクラス名を指定します。 (今回は、犬種を指定) |
今回、犬種ごとに犬の特徴、歴史、性格、飼育に関する説明データを50犬種200件のデータを準備しました。

特徴は、かくがくしかじか・・・, トイ・プードル
歴史は、かくがくしかじか・・・, トイ・プードル
性格は、かくがくしかじか・・・, トイ・プードル
飼育は、かくがくしかじか・・・, トイ・プードル
尚、作成するデータにルールがありますので、注意事項や良いデータを作成するガイドラインはUsing your own data to trainドキュメントを参照してください。
簡単なサンプルデータを作り試すだけなら、最低限下記のルールを満たせば良いでしょう。本格的に実装する場合は、最新の情報を確認してください。
・文字コードはUTF-8
・1レコード1データとし2カラムで構成
・タブを含めない(エスケープして含められますが、面倒なのでスペースに変換)
・テキストは1,024文字まで
・レコードは5~15,000行の範囲とする
トイ・プードルの特徴として、Wikiに掲載された「特徴」に関する説明を収集し、トイプードルとクラスを割り当てておきます。
Wikiのトイ・プードル 「特徴」からトレーニングデータ(csv)を作成
| 巻き毛のシングルコートで毛は抜けにくい。抜け毛や犬特有の体臭もほとんど無いことが家庭犬としての人気の理由の一つであり、またその性質を受け継がせるために、他の犬種との交配による交雑犬や別犬種の作出も盛んである(プードル・ハイブリッド)。その一方で、非常に毛が絡みやすく、毛玉ができやすいため毎日のブラッシング、定期的なトリミングが欠かせない。, トイ・プードル |
上記のとおり、”質問文,クラス”ではなく”説明文,クラス(犬種)”というデータになっていますが、まぁNLCから見てその違いを意識する事は無いでしょう。
では、後編は準備したトレーニングデータを基にAPIを使い実際にNLCを構成し、なんちゃって質問応答をシステムを実装します。尚、試される方はBluemixのアカウントとデータの準備をお忘れなく。
つづく・・・
