


初めまして。データアナリティクスチームの飯村北海です。
唐突ですが、データ分析を行う上ではいくつか欠かせない手法やツールがありますが、ETLツールのTalendについて記事を書きたいと思います。
皆さんはETLツールという言葉を聞いたことはありますか。ELT(Every Little Thing)ではありません(ちょっと年がバレますね)。ETLとはExtract, Transform, Loadの頭文字をまとめたもので、それぞれの3つの機能を備えているツール(ソフトウェア)のことを指します。
ETLをご存じない方にとって、最初に気になるのはETLとは何をしてくれるものなのか?というところだと思います。Wikipediaによると、ETLのExtract / Transform / Loadとはそれぞれ次のような作業を定義しています。
- Extract – 外部の情報源からデータを抽出
- Transform – 抽出したデータをビジネスでの必要に応じて変換・加工
- Load – 最終的ターゲット(すなわちデータウェアハウス)に変換・加工済みのデータをロード
目的に応じて様々なデータソースからデータを集め、加工し、特定のDBに流し込むわけですが、例として小売店のシステムで考えてみましょう。
(以下は実際にあるシステムを説明してたものではありません)
売上データを利用して地域毎の売れ筋商品を分析をしたいと思ったとします。日々の売上のデータはそれぞれの店舗のPOSレジから集まります。これはおそらく一元化されたDBに記録されていると思いますが集約されているだけで、毎週、毎月など売上データを定期的にレポーティングするために使われているだけです。
店舗で販売している商品は売上とは別のDBに登録されている(はずな)ので売上DBと商品DBからデータを抽出(Extract)する必要があります。
抽出したそれぞれのデータはDBの必要なカラムだけを抽出し、BIツールなどで必要なフォーマットに変換(Transform)します。その後、参照用のDBにデータを登録(Load)していきます。
この参照用のDBのことはデータマートと呼ぶこともあります。
ガートナーの2016年のマジッククアドラントレポートによると、2016年のデータ統合ツール(Data Integration Tool)の分野では下記の製品が挙げられています(各社名のリンクはそれぞれのベンダーが主張しているサービスだったり会社HPのURLです)。
ここではタイトルにもあるように、2006年にフランスで創業し、2016年にNASDAQに上場したTalendについてご紹介します。
Talendの特徴を少し箇条書きにしてみました。
- EclipseをベースにしたGUIツールで、Javaのアプリケーションとして実行される。
- 開発環境である「Talend Open Studio(通称TOS)」シリーズをOSSとしてリリースしている。
- コミュニティが活発でコンポーネント(機能)が900以上(2016年時点)にもなっている。
- Jarファイルを実行するbat(Win用)やsh(Linux)を自動出力してくれる。
- フランス語で「才能」の意味(英語だとtalent)。
そんな特徴を持つTalendですが、今回は郵便番号のCSVデータと位置座標のCSVデータをマージするjobをサンプルアプリケーションとして作成してみたいと思います。
郵便番号データと位置座標データをマージして郵便番号から位置座標がわかるデータを作ります。
郵便番号データは日本郵政のこちらのデータ、ではなく諸事情により住所.jpのこちらのデータを使い、また、位置座標データは国土交通省の位置参照情報ダウンロードサービスを利用します。いずれもサンプルということで東京都のみに限定します。
どちらのCSVファイルも以下の定義になっています。
| 列名 | 例 |
|---|---|
| 住所CD | 108602500 |
| 都道府県CD | 13 |
| 市区町村CD | 13103 |
| 町域CD | 131030009 |
| 郵便番号 | 108-6025 |
| 事業所フラグ | 0 |
| 廃止フラグ | 0 |
| 都道府県 | 東京都 |
| 都道府県カナ | トウキョウト |
| 市区町村 | 港区区 |
| 市区町村カナ | ミナトク |
| 町域 | 港南 |
| 町域カナ | コウナン |
| 町域補足 | |
| 京都通り名 | |
| 字丁目 | |
| 字丁目カナ | |
| 補足 | |
| 事業所名 | 品川インターシティA棟 25階 |
| 事業所名カナ | シナガワインターシティAトウ 25カイ |
| 事業所住所 | |
| 新住所CD |
| 列名 | 例 |
|---|---|
| 都道府県コード | 13 |
| 都道府県名 | 東京都 |
| 市区町村コード | 13103 |
| 市区町村名 | 港区 |
| 大字町丁目コード | 131030006002 |
| 大字町丁目名 | 港南二丁目 |
| 緯度 | 35.627386 |
| 経度 | 139.742668 |
| 原典資料コード | 1 |
| 大字・字・丁目区分コード | 3 |
この2つのcsvファイルをマージして以下のファイルを作りたいと思います。
| 郵便番号 | 都道府県名 | 市区町村名 | 大字・町丁目名 | 緯度 | 経度 |
| 108-6025 | 東京都 | 港区 | 港南二丁目 | 35.627386 | 139.742668 |
さてインストールですが、前述のようにTalendはEclipseベースのアプリケーションなので、前提として開発端末上でJavaのSDKが動作するようにしなければなりません。こちらの説明は割愛します。
こちらのTalendオフィシャル(日本語)のサイトからTalned Open Sutido (TOS) の Data Integration (データ統合)のソフトウェアをダウンロードします。この記事を書いている時点でのバージョンは6.3です。
クリックするとポップアップダウンロードするのでブラウザによってはちょっと工夫が必要かもしれません。また、ファイルサイズが大きい(350MBを超える)ので気長に待ちましょう。
Windows、Mac、Linuxどの環境でも動作するようにアプリケーションが置いてありますので、「.exe」なり「.app」なりを実行すれば起動します。

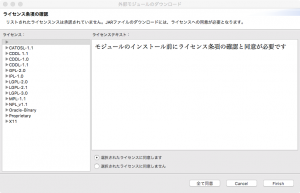
ライセンスをよく読んで同意します。
workspaceを訪ねる画面の代わりにプロジェクトを指定する画面が出てくるので新しいプロジェクトを作り、終了を押します。「終了」とありますが、気にせずクリックしてください。
こういうページが出てきます。Talendのマニュアルなど使い方が(英語ですが)参照できます。
続けて追加でインストールするフィーチャーの追加をします。
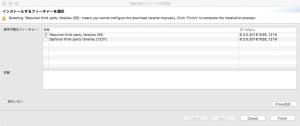
フィーチャーを追加するにはライセンスのすべて同意をクリックします。
さて、起動するとEclipseベース、とはいうものの、ちょっと異なるインターフェースが出てきます。
バージョン6.3から初期画面でクイックツアーがあるようです。邪険にせずにざっと見ておくと良いと思います。
では、さっそく作っていきましょう。
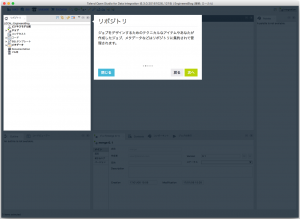
ツアーを見た後はだいたいこのような画面になっていると思います。
※クイックツアーの時に出てきているデモのジョブは閉じています。
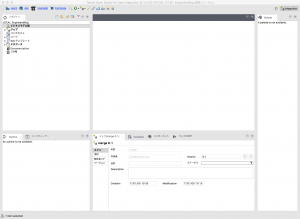
リポジトリでジョブを作り、真ん中の作業エリア(デザインワークスペース)でinputとoutputをGUIで作っていく、という流れです。
まずはinputとして先に挙げた2つのファイルの定義をしておきましょう。
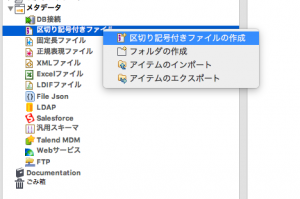
左のリポジトリからメタデータを展開し、「区切り記号付きファイル」の
コンテキストメニューから「区切り記号付きファイルの作成」を選択します。
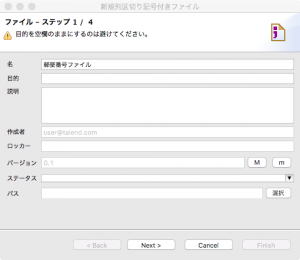
このようなウィザードが出てくるので進めていきます。ステップ1/4ではメタデータの名前を指定します。
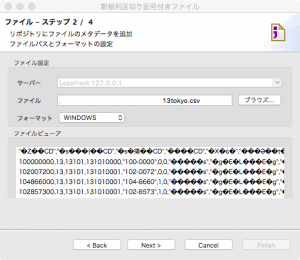
ステップ2/4ではcsvのファイルを指定します。
ステップ3/4ではメタエータの設定をします。
エンコーディングは「Shift-JIS」や「UTF-8」など適切に選んでください。ここでは「Shift-JIS」にしておきます。
フィールドセパレータのデフォルトはセミコロンなので、カンマに変えます。
ロウセパレータはそのままで大丈夫です。
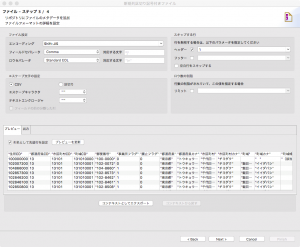
下部のプレビュータブの「列名として先頭行を設定」にチェックを入れて「プレビューを更新」ボタンを押すといい感じで判別してくれます。
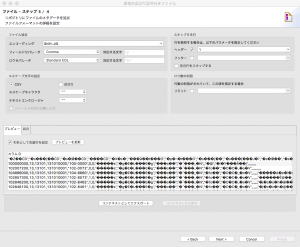
この通り。
ステップ4/4ではスキーマの設定をします。使うカラムの名称をわかりやすく指定します。
キーの設定やタイプ、長さなどもここで設定ができます。
名称はmetadataからzipに変えました。
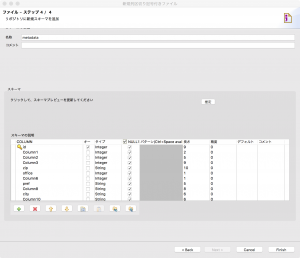
finishを押して、もう一つ、同様に緯度経度のファイルも設定しておきます。
そうするとこのように設定が2つ増えています。
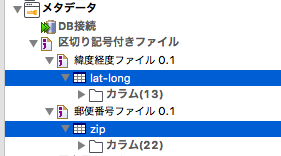
ジョブを作ります。
ジョブもリポジトリから同様にコンテキストメニューで作れます。
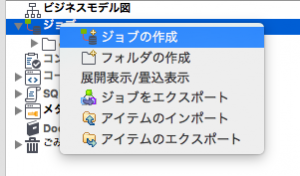
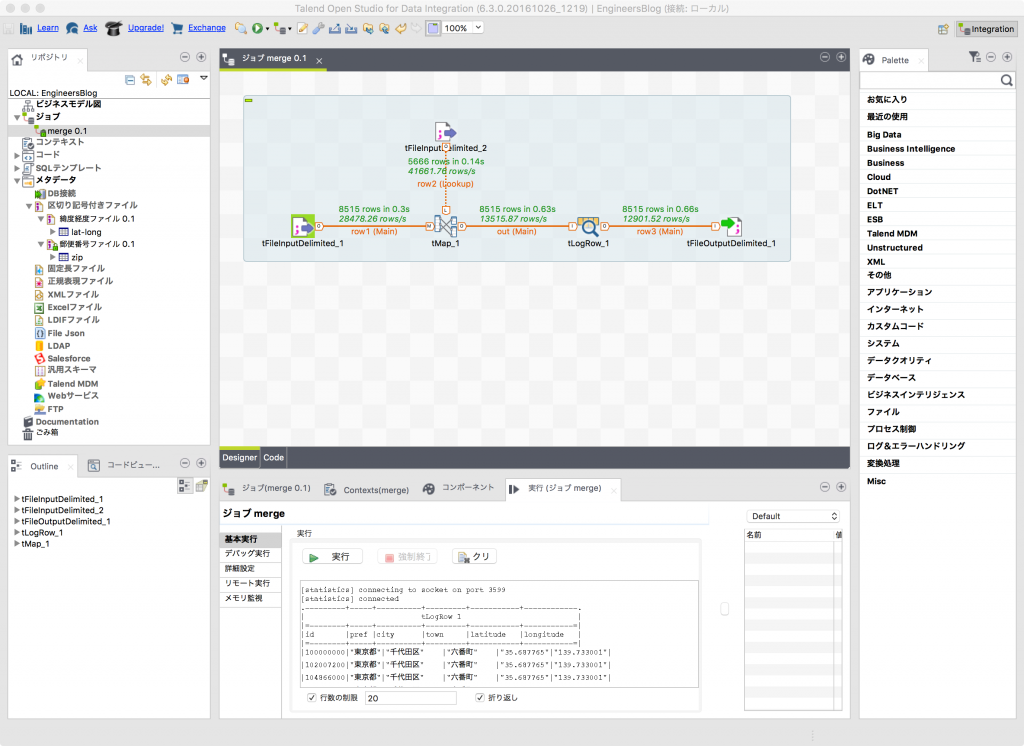
ジョブの名前はmergeにしました。作成後はこのような画面になり、デザインワークスペースでコンポーネントを追加できるようになります。
input/outputとprocessのコンポーネントを追加していきましょう。
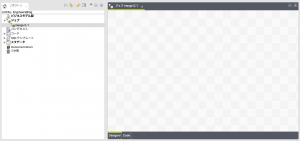
キャンバスのようなところをクリックしておもむろにキーボードで「tfileinputdelimited」と入力していくと、候補が現れます。
これはTalendがinputの型の候補を自動であげてくれるようになっています。
名前のルールがだいたい決まっていて、最初のtはTalendのtだと思いますが、区切られた(delimited)ファイルインプットという型を指定したと考えてください。
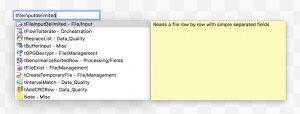
右側のパレットから検索してドラッグ&ドロップで追加する事もできます。
画面はtmapと入力してtMapのコンポーネントが出てきています。
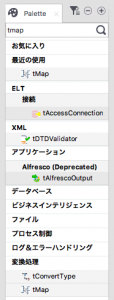
2つのcsvファイルのinputのコンポーネントとtMapのコンポーネントを追加したところです。
tMapは入力1と入力2をマージするルールを定義するものだと思ってください。
tFileInputDelimited_1のアイコンが選択状態になっていますが、この状態になると下部のコンポーネントでプロパティが表示されるようになっています。
ここで先ほど定義したメタデータを指定できるようになります。
これは初期状態は「プロパティタイプ」が「組み込み」か「リポジトリ」かを選べるようになっていて、「…」をクリックするとメタファイルを指定できるようになっています。
それぞれ2つのcsvファイルを指定しておいてください。
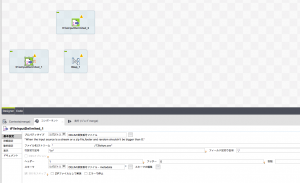
input要素とprocess要素を接続します。
トリガーとなる方のアイコンからコンテキストメニューを出して、tMapにつなげます。
「ロウ」->「Main」を選択するとマウスにtFileInputDelimitedから線が伸びるので、tMapでクリックします。
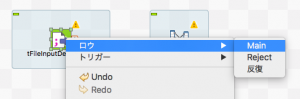
そうすると次のような画面になります。
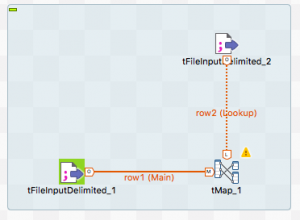
下の方にrow1(Main)と表示された線が引かれます。
画面上ではtFileInputDelimitedからもLookupさせるように線を延ばしています。
こちらはアイコンをクリックして五角形に白丸があるところからドラッグ&ドロップでtMapの方へつなげています。
右側の部分はoutputのコンポーネントを追加しました。
最終的にはtFileOutputDelimitedでファイル出力しますが、
デバッグ用にtLogRowも作っておきましょう。
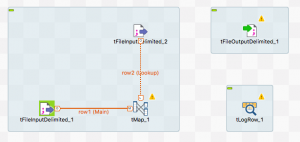
tLogRowにつなげます。
繋げるときに出力名を聞かれますが「out」にしています。
※tFileOutputDelimitedの方は少し上の方に位置をずらしました。
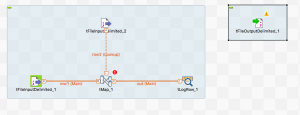
郵便番号ファイルと位置座標ファイルの2つのカラムのマッピングをしてみましょう。
tMapコンポーネントのアイコンをダブルクリックするとマッピングするためのウィンドウが新しく表示されます。
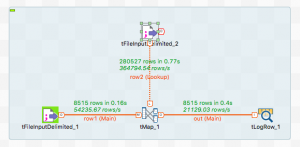
row1の方は郵便番号ファイル、row2の方は位置座標ファイルのものが参照されています。
先ほど説明しましたが、線の上にデザインワークスペースにrow1(Main)とrow2(Lookup)となっていることに注目してください。
ここでprefとcityがそれぞれ一致しているという前提でjoinの条件を作っていきます。
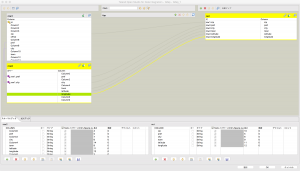
さて、これで一度実行してみましょう。
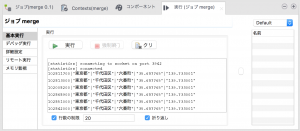
コンフィギュレーションタブ(翻訳ではコンフィグレーションタブとありましたが…)と呼ばれる下のエリアの「実行(ジョブ<ジョブ名>)」タブの「実行」をクリックすると始まります。
「行数の制限」にチェックをつけておくと指定した行数で出力を止めてくれるので見やすいと思います。
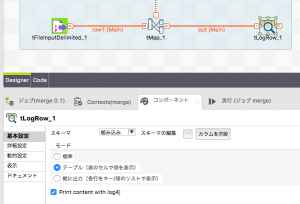
tLogRowの設定を説明し忘れていました。
「コンポーネント」タブから「基本設定」のモードをテーブルにしておくと見やすいと思います。
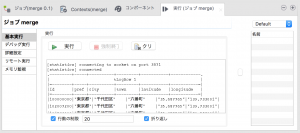
ちなみに実行後の統計情報がこちらに表示されます。
どのくらい時間がかかるかの参考になりますね。
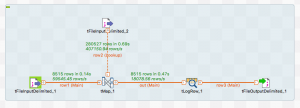
ログ出力だけではなく、ファイル出力も追加してみました。
tFileOutputDelimitedの設定は下記のようにしています。
基本設定ですが、ファイルの出力場所はデフォルトだとTOSのワークスペースにout.csvとして指定されるので任意の場所を指定します。
フィールド区切り記号はデフォルトだとセミコロン(”;”)なのでカンマ(”,”)に変えておきます。
また「ヘッダーを含む」のオプションにチェックをつけておきます。
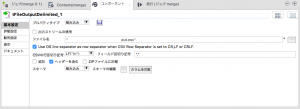
詳細設定では「CSVオプション」にチェックをしておきます。
エンコードは「CUSTOM」を選択し、「Shift-JIS」を入力します。
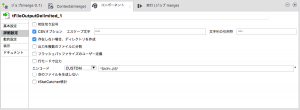
ファイルを出力するだけならこれだけでとりあえずはファイルが出てくるようになります。
と思うかもしれませんが、Talendを使うにあたり式フィルタや条件分岐など色々と調整するところがあります。それは後編でご説明したいと思います。
いかがでしたでしょうか?ETLツールの話を説明し、ETLツールの1つであるOSSのTalendの使い方について基本的な流れを説明しました。
私も全てのTalendの製品を使ったわけではないのですが、ETLツールを気軽に試してみるにはOSSで無償で使えるTalend製品を利用してみるのが良さそうです。
後編ではよく使いそうなコンポーネントも含めて説明をしていきたいと思います。
