


こんにちは、福原です。
今回はクレスコエンジニアブログの記事一覧をスクレイピングして
各記事の「タイトル、URL、カテゴリ、日付」をCSVファイルに出力してみました。
その際に、Pythonの開発環境を用意してくれるGoogle Colaboratoryを使ってみたので
インストール方法などを簡単に紹介していきます。
目次
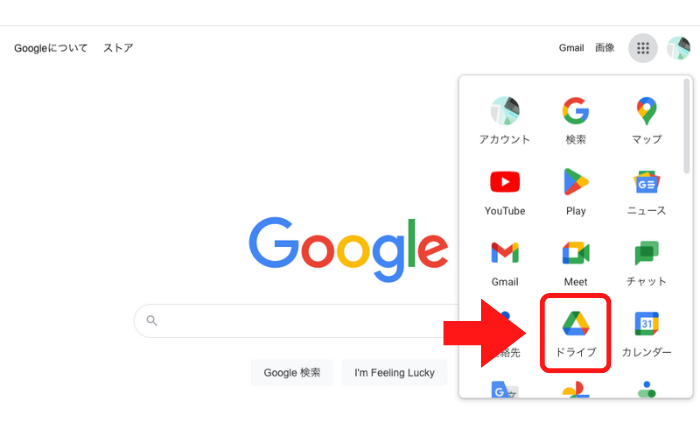
Googleトップページからメニューアイコンをクリックし、
ドライブをクリック
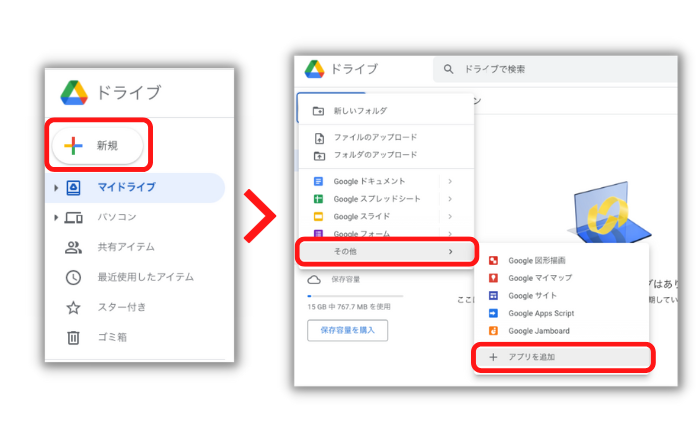
新規ボタンをクリック
その他→アプリを追加をクリック
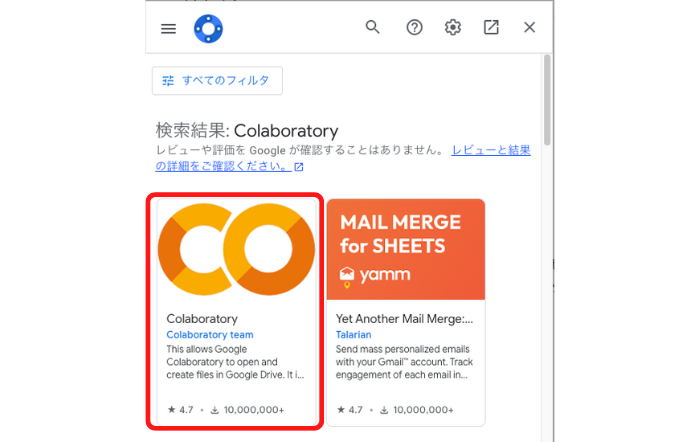
「Colaboratory」を選択した後、インストールボタンで完了!
これで初期設定は完了です!
Googleドライブの画面から新規ファイルを作成していきます
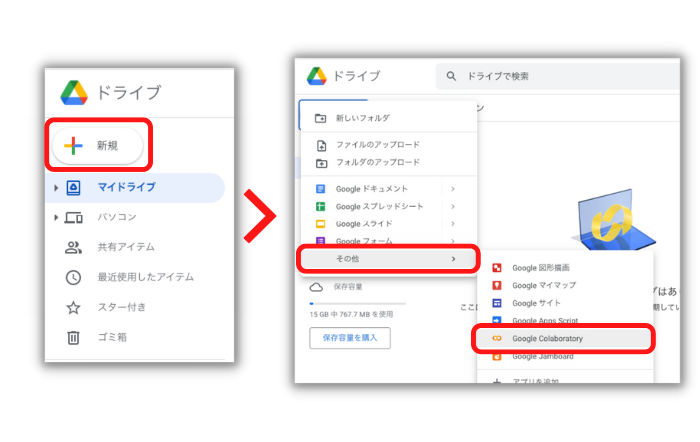
新規ボタンをクリック
その他→Google Colaboratoryをクリック
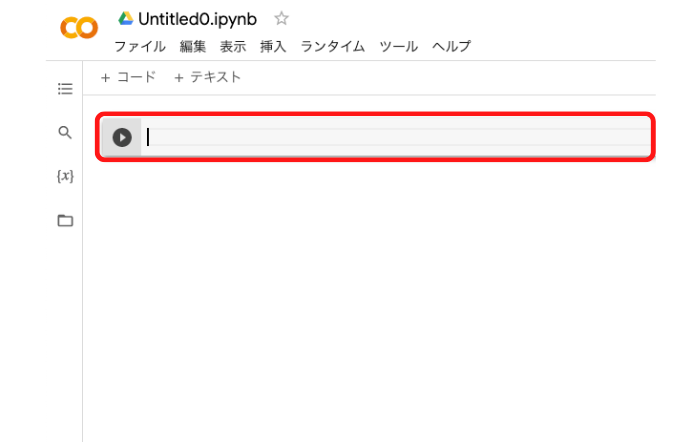
「Untitled0.ipynb」ファイルが表示されます
画像の赤枠にPythonコードを書いていきます
実際にブログ記事の情報を取得していきます
今回使用するライブラリは以下2つです
- BeautifulSoup = スクレイピング用
- Requests = WEB ページのダウンロード用
まずはRequestsでエンジニアブログトップページのhtmlをダウンロードします。
| from bs4 import BeautifulSoup as bs4 |
| import requests |
| # 情報を取得したい URL を指定する |
| url = 'https://○○○○/' |
| # Requests で URL 先の html を取得する |
| res = requests.get(url) |
次にBeautifulSoupでブログ記事一覧を取得します
開発者ツールで、どのクラスを取得するか確認します
| soup = bs4(res.content, "html.parser") |
| article_list = soup.find("div", {'class' : 'post-loop-wrap'}) |
さらに、find_allメソッドを使い、ブログ記事一覧をリストに分けます
| article_info_list = article_list.find_all('article') |
次に各記事からタイトル、URL、カテゴリ、日付を取得します
| # 結果用のリストを作成する |
| result = [['title', 'url', 'category', 'date']] |
| # 各記事の情報を取得して、リストに格納する |
| for article_info in article_info_list: |
| title = article_info.find('h2').text # タイトル |
| url = article_info.find('a').get('href') # URL |
| category = article_info.find('li', attrs={ 'class': 'cat' }).text # カテゴリ |
| date = article_info.find('li').get('datetime') # 日付 |
| result.append([title, url, category, date]) |
最後に情報をCSVファイルに保存します
| import csv |
| with open('article_info.csv', 'w', encoding="utf-8") as file: |
| writer = csv.writer(file, lineterminator='\n') |
| writer.writerows(result) |
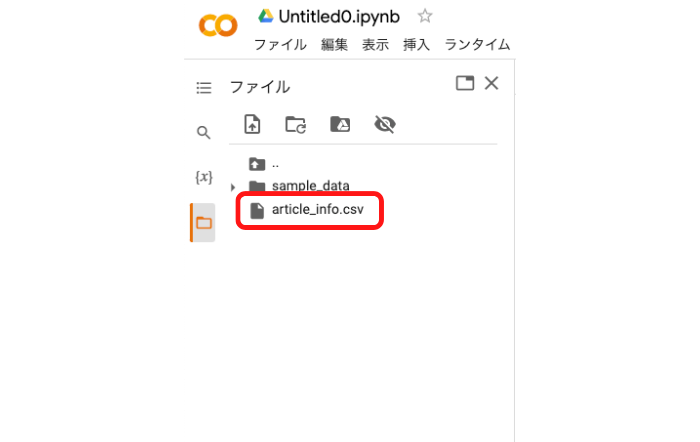
左のファイルからCSVファイルを開くことができます
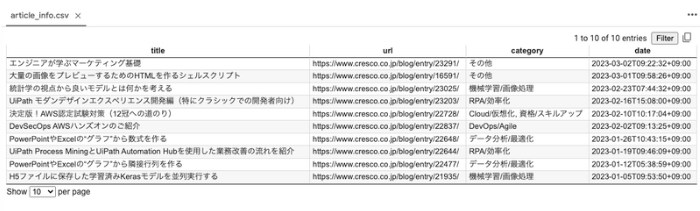
タイトル、URL、カテゴリ、日付が取得できました!
今回はGoogle Colaboratoryを使って、スクレイピングをやってみました。
初学者にとって環境構築を避けることができるのは
とても魅力的なメリットだと感じました。
Googleアカウントを持っているだけで、簡単にWEBスクレイピングができたので、
もし興味がある方は、ぜひ使ってみてください!
