


この記事は 『CRESCO Advent Calendar 2017』 1日目の記事です。
AIに対する過度な期待値を下げつつ、AIの精度向上に励んでいるウエサマこと井上 (祐)です。
本記事では、クラウド型音声認識サービスの認識精度について記述します。

音声認識は人の能力を超える!?
音声認識の評価手法としてSWITCHBOARDデータセットを用いた、評価が代表的な手法となります。
このSWITCHBOARDデータセットは、電話にて交わされた2,400を超える英語による会話が含まれており、このデータセットに対する音声認識の誤り率5.5%が現在(2017/11月時点)の最高到達点となります。
逆に言うとほぼ95%は正解という事ですので、こう考えると人の聞き間違いの方が多いかもしれません。
(参考:”マイクロソフトの音声認識システム、「人と同等」レベルに到達“(ZDNet Japan 2017/8/24))
さて、このSWITCHBOARDですが、実装の違う音声認識の性能評価を行うには、こうした尺度が有効となりますが、実際の運用では同等の性能を発揮する事はありません。
運用する環境のノイズや話者の滑舌や言い回し、専門用語、日本語の特徴となるモーラリズムなど様々な要因が認識精度の低下を引き起こしているため、SWITCHBOARDで示された認識精度には到底到達しない現実があります。
本記事では、こうした尺度ではなく実際の音声コーパスを用いて、代表的なクラウド型音声認識サービスを比較してみたいと思います。
料金、スペック、機能などカタログ値的なものは、それぞれの製品サイトや他のサイトに譲ることとし、下記の3サービスをざっくり比較してみます。
(1)IBM Watson Speech to Text (以下、Watson)
(2)Google Cloud Speech API (以下、Google)
(3)Microsoft Bing Speech API (以下、Bing)

評価基準
音声認識されたテキストが正解テキストに対して、どのくらい正解、誤りがあるかをカウントを行う。尚、認識誤りは”置換誤り”、”脱落誤り”、”挿入誤り”と分類します。
下図にそのイメージを示します。(アルファベットが単語と思ってください)
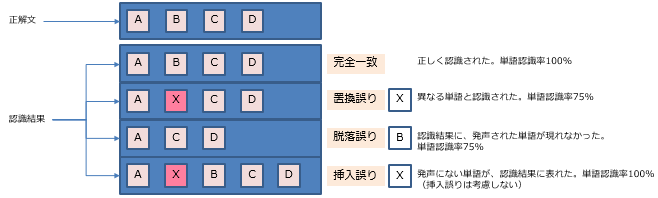
語認識率、単語正解率の2つを求め音声認識サービスを比較します。
①「単語認識率(Correct)」
音声認識された単語が、正しく認識されているか評価を行う。
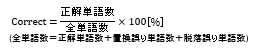
②「単語正解率(Accuracy)」
認識結果の確からしさの評価を行う。

実際の評価は音声認識の利用目的に応じて、評価項目や基準を決定します。
ここであげた基準は、会議議事録の書き起こしや字幕、日報と行った分野向けの基準で、かなり厳しい設定になっています。
本来は実際の業務で使われている音声データを使うのですが、ここでは研究目的での利用を前提とした
音声コーパスを利用しました。
今回使っている音声コーパス
・国立国語研究所コーパス開発センター
日本語話し言葉コーパス(サンプルデータ)
音声データはサンプリングレート 16,000、モノラル、フォーマットはWatsonとAzureはwav、Googleはflacにそれぞれ変換しています。
今回2種類の音声データを使い実施した評価結果を示します。
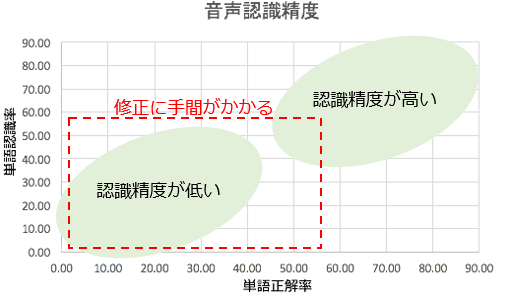
棒グラフはそれぞれのサービスにおける認識誤りの傾向を示し、もう一つのグラフは音声認識精度を示します。
このグラフから精度の良し悪しの他に、修正への手間が多くかかるのか、少なくて済むのかが読み取れます。
では、2種類の音声データを使い評価してみましょう。
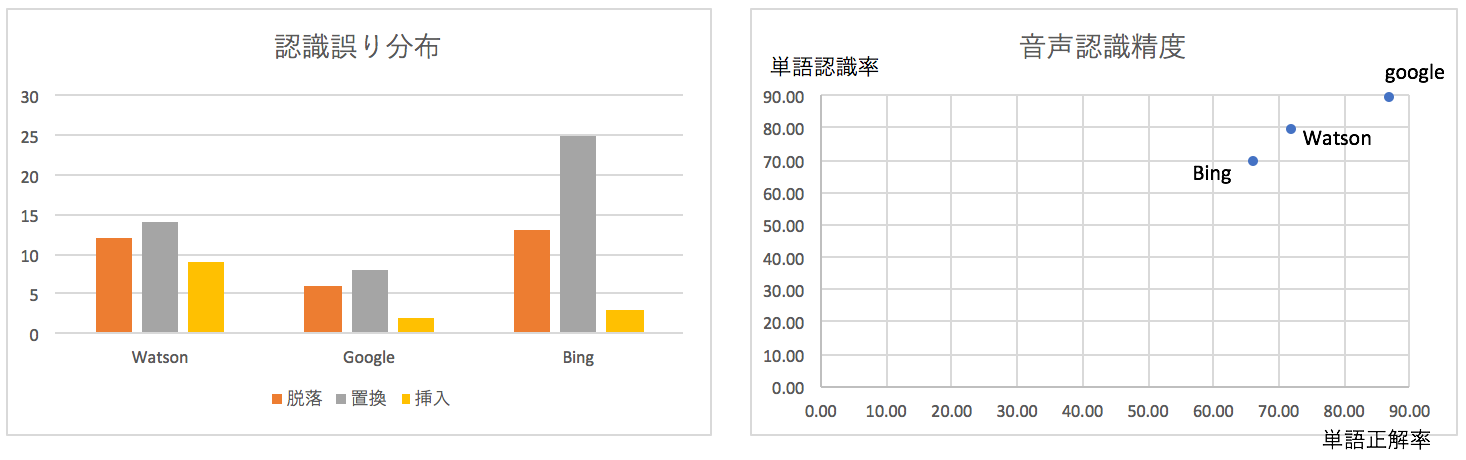
【認識精度の順位】
先に結論からあげますがGoogleは、頭一つ飛び抜けた感じの高い認識精度となりました。

Google、Watson、Bing
【評価結果】
| 音声データ | 学会講演音声のサンプル *音が出ます 約35秒、125単語 | ||||||
| 音声認識サービス | 正解 | 誤り | 単語認識率 | 単語正解率 | |||
| 脱落 | 置換 | 挿入 | (Correct) | (Accuracy) | |||
| 1 | Watson | 99 | 12 | 14 | 9 | 79.20 | 72.00 |
| 2 | 111 | 6 | 8 | 2 | 88.80 | 87.20 | |
| 3 | Bing | 86 | 13 | 25 | 3 | 69.35 | 66.40 |
【認識結果】
正解テキストと各サービスの認識結果を示します。
| テキストの概要 | 認識結果 |
| 音声書き起こし正解データ | パラ 言語 情報 という こと な ん です が 簡単 に 最初 に 復習 を し て おき たい と 思い ます まあ あの こう やっ て 話し て おり ます と それ は もちろん あの 言語 的 情報 を 伝える という こと が 一つ の 重要 な 目的 で なん で あり ます が 同時に パラ 言語 情報 そして 非 言語 情報 が 伝わっ て おり ます まっ この 三 分 法 は 藤崎 先生 による もの でし て パラ 言語 情報 という の は 要は 意図 的 に 制御 できる 話者 が ちゃんと コントロール し て 出し てる ん だ けども 言語 情報 と 違っ て 連続 的 に 変化 する から カテゴライズ する こと が やや 難しい そういった 状況 で あり ます |
| Watson認識結果 | ええ パラベン ご 情報 と いう こと なん です が 簡単 に 最初 に 復讐 を し て おき たい と 思い ます まあ 戸建て 話し て おり ます と それ は もちろん 言語 的 情報 を 伝える という こと が 一つ の 重要 な 目的 あり ます が 同時 に 他の 言語 情報 そして 非 言語 情報 が 伝わっ て あり ます が この 3 分 法 藤崎 に よる もの でし で これ ご 情報 と いう の は 様は 意図 的 に それ が できる は 車 が ちゃんと コントロール し て 出し てる ん だ けども 言語 情報 と 違っ て 連続 的 に 変化 する 方 ご覧 いい ず する こと が やや 難しい そういった とこ で あり ます |
| Google認識結果 | パラ 言語 情報 という こと な ん です が 簡単 に 最初 に 復讐 を し て おき たい と 思い ます まあ あの こう やっ て 話し て おり ます と それ は もちろん あの 言語 的 情報 を 伝える という こと の 重要 な なん で あり ます が 同時に 腹 言語 情報 そして 非 言語 情報 が 伝わっ てる スマ この 散 文 方 は 藤崎 先生 による もの でし て パラ 言語 情報 という の は 弱 さ の 意図 的 に 作業 できる 場所 が ちゃんと コントロール し て 出し てる ん だ けども 言語 情報 と 違っ て 連続 的 に 変化 する から カテゴライズ する こと が やや 難しい そういった 状況 で あり ます |
| Bing認識結果 | やっぱ 言語 情報 と言う こと な ん です が 簡単 に 最初 に 復習 を し て おき たい と 思い ます まあ あの う 超え たら 花し て おり ます と 空 もちろん がの 言語 的 情報 を 伝える という こと が 一つ の 重要 な 目的 に 何 だ あり ます が どうして に 多言語 情報 そして 非 言語 情報 が 伝わっ た の 三本 保久 による もの でし てん の 情報 と言う の は 用は 有 の 意図 的 に する の が ちゃんと コントロール し てる ん だ けども 言語 情報 と 違っ て 連続 的 に 変化 する から 愛する こと が 難し それ は どこ で あり ます |
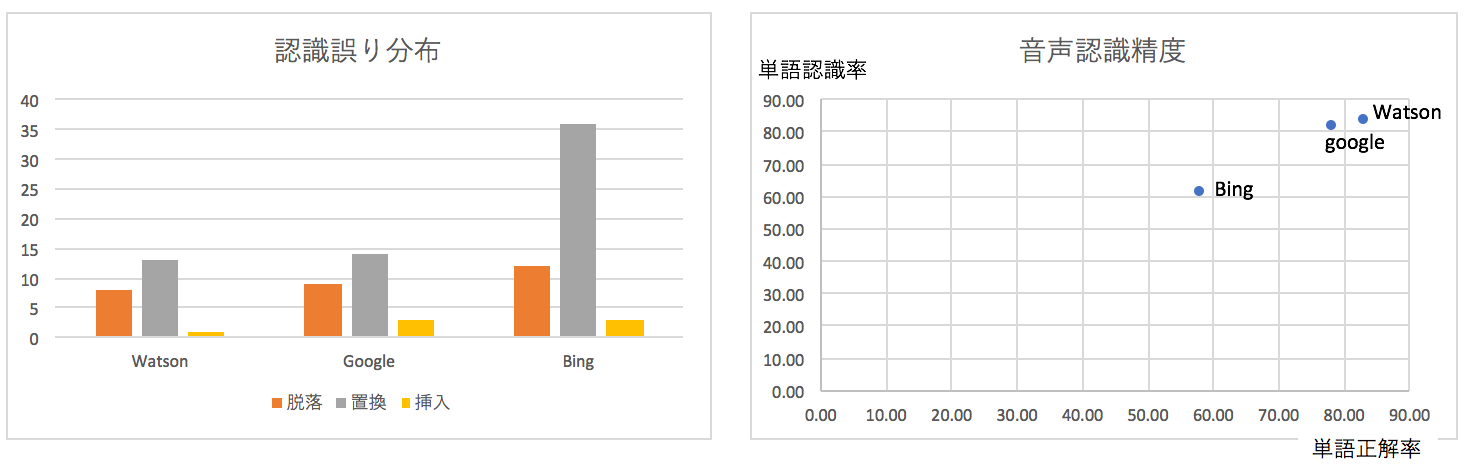
【認識精度の順位】
Watsonが認識率80%を超えてきております。Googleも十分な精度に達していると思います。

Watson、Google、Bing
【評価結果】
| 音声データ | 一般的な「スピーチ」の音声*音が出ます 開始から約 60秒間、123単語 | ||||||
| 音声認識サービス | 正解 | 誤り | 単語認識率 | 単語正解率 | |||
| 脱落 | 置換 | 挿入 | (Correct) | (Accuracy) | |||
| 1 | Watson | 104 | 8 | 13 | 1 | 83.20 | 83.06 |
| 2 | 100 | 9 | 14 | 3 | 81.30 | 78.23 | |
| 3 | Bing | 75 | 12 | 36 | 3 | 60.98 | 58.06 |
【認識結果】
| テキストの概要 | 認識結果 |
| 音声書き起こし正解データ | それから 最後 に 司法 判断 裁判 の 結果 です ね それ に対する 不信 という もの も 感じ た 記憶 が あり ます それ は どういう こと か って いう と まぁ 先 ほど 言い まし た よう に その 先生 方 対応 さ れ た 先生 方 は 一 人 ぐらい 例外 が あっ た よう な 気 が し ます けども みんな おしなべて 有罪 判決 を 受け た それ は まぁ しょうが ない でしょ う で 送っ た 側 です ね 親 が どう で あっ て も 一 人 も 責任 を 問わ れ なかっ た それ が 非常 に 僕 は 不思議 な 気 が し まし た ね あのー 今 で も まし た ね あのー 今 で も |
| Watson認識結果 | それから 最後 に 司法 販売 裁判 の 結果 です ね それ に対する 不信 という もの も 感じ た 記憶 が あり ます その 通り こと か って いう と D_マ 先 ほど 言い まし た よう に その 先生 方 対応 さ れ た んです 方 は 一 人 ぐらい 例外 が あっ た よう な 気 が し ます けども みんな おしなべて 有罪 判決 を 受け た で そのまま しょうが ない で 送っ た 後 です ね 親 は どう だった と 一 人 も 頃 責任 を 寝 取られ なかっ た それ が 非常 に 部下 不思議 な 気 が し ます ね D_アノー 今 で も |
| Google認識結果 | だから 最後 に 司法 判断 裁判 の 結果 です ね それ に対する 不信 という もの も 感じ た 記憶 が あり ます の 空 どういう こと か って 言う と は 先 ほど 言い まし た よう に 誘い 方 逮捕 さ れ た 先生 方 は 一 人 ぐらい で 甲斐 が あっ た よう な 気 が し ます けども みんな おしなべて 有罪 判決 を 受け た ドラマ しょうが ない でしょ 送っ た 側 です ね お家 は どこ だっ たった 一 人 も これ は 責任 を 寝取ら れ なかっ た それ が 非常 に 高価 不思議 な 気 が し まし た ね あなた も 実は 何で |
| Bing認識結果 | それから 最後 に 編者 司法 hannba 裁判 の 結果 です ね それ に対する 不審 という もの を 感じ た 記憶 が あり ます 空 飛ぶ こと が と 言う と お 酒 を どう 思い まし た よう に その 際 型 逮捕 さ れ た の 姿 は 一 人 ぐらい あっ た よう な 気 が し ます けども みんな を 調べ て いる 団結 送っ た それ は まあ しょうが ない 所 を 送っ た の です ね おや は どう だっ た 一 人 も これ は 責任 を 寝取ら れ なかっ た それ が 非常 に 僕 不思議 なき まし た ね あの う 今 も 実は なんで そんな の が よく わかん ないWatson認識結果にある”D_”は、言い澱みを示しています。 |

まとめ
今回2音声による評価のため、これだけでクラウド型音声認識の優劣をつける事はできませんが、
音声認識の精度は、これまでの経験上、概ねGoogle、Watson、Bingという感じになります。
Watson、Bingはカスタムモデルを作れるため学習次第で適切な認識精度まで上げていくことが可能となります。
今回の評価は、どちらかというと良い認識率が得られています。
これは利用した音声コーパスの品質が非常に良く、逆に言うとこのくらいの認識精度でなんら不思議な事はありません。
ですが、実際のビジネスシーンにおける認識精度は60%台がスタートになるかと思います。
これをいかに80%台に引き上げるか、ここに多くのノウハウが必要となります。
音声認識を何に使うのかによっても、精度向上の進め方が変わってきますが概ね下記の5点がポイントになります。
(1)適切な評価基準を設定する
(2)学習データによりコーパスを整備する
(3)辞書を整備する
(4)話者をトレーニングする
(5)発話環境を整備する
スマートスピーカも登場し、音声を用いたインターフェースはより自然なものになっていくのではないかと思います。ともすれば、独り言を言っているようで恥ずかしい感じもしますが、そういう時代では無いですね。
音声認識については引き続き、学習効果や話者分離など調べたいこともたくさんありますので、成果が得られたらエンジニアブログに残して行きたいと思います。
では、明日以降も続く『CRESCO Advent Calendar 2017』 お楽しみに。

