


この記事は 『 Cresco Advent Calendar 2017』 11日目の記事です。
OSS SIGへの道すがら…
<登場人物>
にしやん:関西出身、若手SE(1年目)、文中では「に」
やまさき:九州出身、若手SE(1年目)、文中では「や」
2人はクレスコ社内のOSS SIGに入っている。

SIGとは技術コミュニティの活動であり、
弊社内で特定の技術分野に興味がある人が集まって活動するものである。
オープンソースソフトウェアに興味を持っている人々が集まっているSIG。
オープンソースソフトウェアの中でも今期はSparkに焦点を当て、活動している。
や「今日はSIGかあ~~たのしみ。」
に「楽しみやね!でもやまさきこのまえ来てないな、話わかるかな?」
や「わからんなきっと(笑)教えて!」
に「んーーっと、まずはざっくりSparkって何ができるのか前々回のSIGから
おさらいしよっか!」
や「うん よろしくお願いします!」
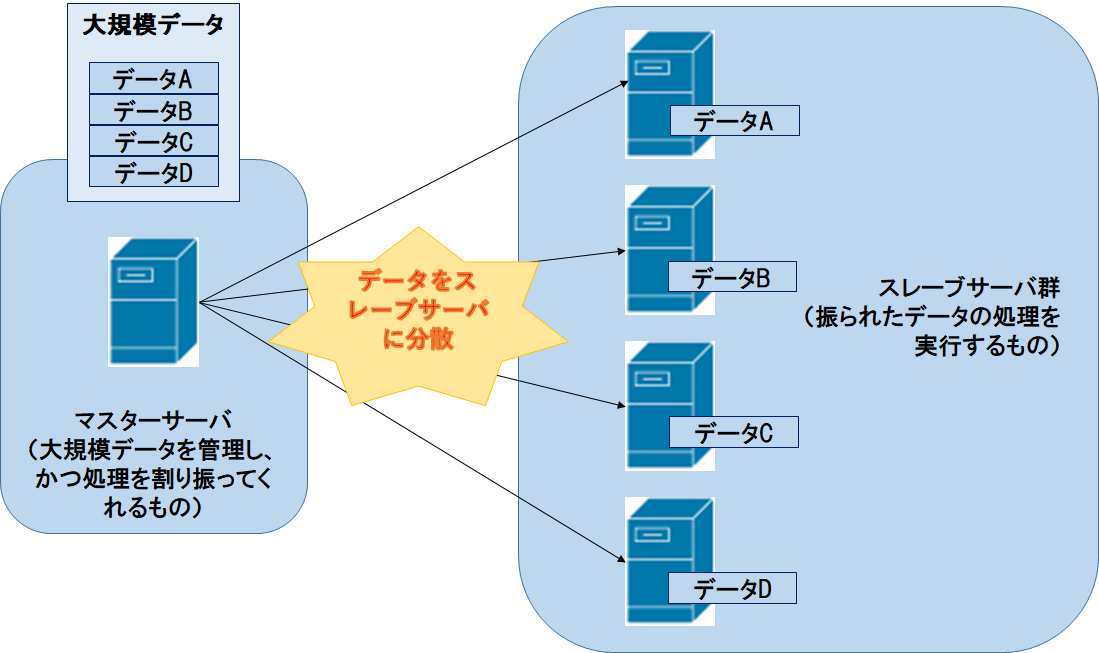
に「Sparkってのは並列分散処理によって、大量のデータを処理してくれんねん。」
や「うんうん思い出した! 並列分散処理って、確か大量のデータを複数サーバに分散して処理し て、実行結果はネットワークを通じて共有するんだよね? 」
に「そうそう!」
や「だよね、で、SparkはHadoopと違って、メモリ上にデータを保持できるから、細かいバッチ処理を繰り返し行えるんだったよね?」
に「そう!それによってニアリアルタイムでのデータ処理ができるようになってん。
めっちゃ覚えてるやん!」
や「えへへ、でもそっからSparkの詳しい話が分からない。」
に「前回はそこを学習したんよ。Sparkには[Spark SQL]、[Spark Streaming]、[MLlib]、[GraphX]
っていう、分散処理を扱いやすくしたエコシステムが提供されてるねん。」
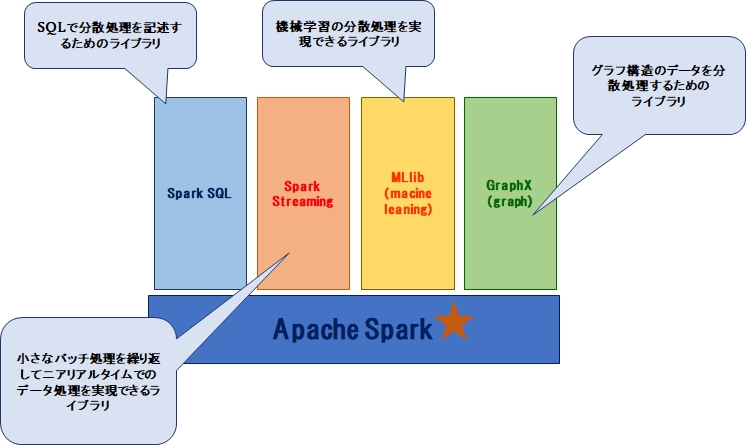
や「うんうん。それぞれのライブラリで出来る事が違うって事だよね?」
に「そういう事。さっき言ってた、ニアリアルタイム処理は、[Spark Streaming]で実現できるんよ。」
や「へぇー。なるほどね。」
に「[MLlib]っていうのは機械学習の時に、大量のデータをさばかせて分析させるときに使えるライ ブラリのことやで。」
や「ふんふん。機械学習にも使えるんだ!」
に「そうやねん。今後はこの[Spark Streaming]と[MLlib]を使ってデータ分析デモを作るんやで!」
や「そっかそっか。なるほど、ありがとう!」
にしやん&やまさきスペシャルインタビュー
~Sparkで出来たらうれしいことは?~
・にしやん
Twitterからの天気・イベント・交通情報などのデータを解析して、タクシーを必要としている人が多い場所を予測する。
これで、電話をしなくてもタクシーの配車ができる。
・やまさき
画像認識技術とSparkを繋げて面白いことしたい。害虫や害獣をリアルタイムで画像認識させて農作物を守る。そうすることで、農家の皆さんの不安を取り除きたい。機械学習を行うことで、精度がどんどん上がっていく。
3月末は社内の発表会で、デモをします。
頑張ります!!
以上、にしやまさきでした。ありがとうございました(^^)(^^)。
