


突然ですが、今日12/16は大イベントがありますね!そう、クラブワールドカップの決勝戦です!
FIFA(国際サッカー連盟)が主催するサッカーの大会で、ヨーロッパ、アジア、オセアニア、北中米カリブ、南米、アフリカの各大陸チャンピオンと開催国代表の計7チームが集まる、世界最強のクラブを決める大会です。
昨年は日本で開催され、開催国代表である鹿島アントラーズ柴崎選手(当時)がスペインの強豪レアルマドリード相手に大活躍して話題になりました。
今年はアジアチャンピオンとして浦和レッズが出場しましたし、北中米カリブ代表パチューカに所属する本田圭佑選手も出場しました。
どちらも決勝まで進むことはできませんでしたが、熱い戦いを見せてくれましたね。
来年は(国別の)ワールドカップもありますし、サッカーがとても盛り上がっているなあと感じます。
そこで、今日は日本代表のベストイレブンをIT技術的な(特に私の専門の自然言語処理の)観点から導き出したいと思います!
- FIFAの選定した2017年のベストイレブン(下表)を、2017年時点の各ポジションの世界最高の選手だとする。
- Wikipediaの記事で学習したword2vecを用い、各選手に最も近い意味で使われている日本人選手を日本におけるそのポジションの最高の選手として、ベストイレブンとする。
| 選手名 | ポジション | 国籍 | 所属クラブ |
| リオネル・メッシ | FW | アルゼンチン | FCバルセロナ |
| クリスティアーノ・ロナウド | FW | ポルトガル | レアルマドリード |
| ネイマール | FW | ブラジル | FCバルセロナ⇒ パリ・サンジェルマン |
| ルカ・モドリッチ | MF | クロアチア | レアルマドリード |
| トニ・クロース | MF | ドイツ | レアルマドリード |
| アンドレス・イニエスタ | MF | スペイン | FCバルセロナ |
| マルセロ | DF | ブラジル | レアルマドリード |
| ダニエウ・アウヴェス | DF | ブラジル | ユベントス⇒ パリ・サンジェルマン |
| セルヒオ・ラモス | DF | スペイン | レアルマドリード |
| レオナルド・ボヌッチ | DF | イタリア | ユベントス⇒ ACミラン |
| ジャンルイジ・ブッフォン | GK | イタリア | ユベントス |
| OS | Windows 10 Enterprise |
| 元ネタ | Wikipediaの記事 |
| 開発言語 | Python3.6 |
| ライブラリ・ツール | wp2txt、gensim(word2vec)、MeCab |
学習済みのword2vecモデルを使おうとも考えたのですが、これは選手名が”姓”と”名”に分かれて単語登録されており、うまく個人を特定できませんでした。
なので、今回は選手名をフルネームで登録した、サッカー選手に特化したword2vecモデルを自前で作成することにします。
- Wikipedia記事情報をテキスト化し、記事単位に分解
- サッカー選手に特化したword2vecモデル作成
- ベストイレブンの選手と、日本人選手の類似度を比較し、最も近い1名を選出
まずは、Wikipediaの記事を学習に使える形に整形し、サッカー選手の記事だけを抽出します。
ここからWikipedia記事のダンプデータをダウンロードし、wp2txtを使用してxml形式からテキストに変換します。
wp2txtの使い方はこちらを参考にさせていただきました。(マシンパワーの問題でここだけUbuntuサーバーで作業しています。)
このままだと、1つのファイルに複数の記事が記載されている状態なので、
扱いやすさのために記事単位にファイルを分割します。
wp2txtでテキスト化した記事の例を以下に示しますが、記事タイトルが [[ TITLE ]] という形になっています。
このタイトルをファイル名として、単純に頭からサーチして出力先を切り替えながらファイル出力をしていきました。
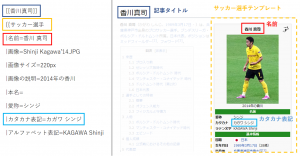
[[香川真司]]
{{サッカー選手
|名前=香川 真司
|画像=Shinji Kagawa’14.JPG
|画像サイズ=220px
|画像の説明=2014年の香川
|本名=
|愛称=シンジ
|カタカナ表記=カガワ シンジ
|アルファベット表記=KAGAWA Shinji
( — 以下略 — )
ここで気を付けたいポイントが3つあります。
①Windowsでファイル名に使えない文字が現れる
タイトルに”/”や”|”などの禁則文字が使われている場合があるので、それらをすべて”_”に置換しました
②添付されている画像ファイルなども[[ ]]で囲われている
画像ファイルの場合、多くが1行の途中で現れるため、 [[ ]] だけで完結する行をタイトルとすればほとんどが弾けるのですが、稀に1行すべて画像ファイル名で埋まっている場合があったのでもう少し手当てが必要です。
ピックアップで確認したところ、画像ファイルの場合は “|thumb|”(サムネイル?)という文字列が入るようです。これを除外条件とすることでタイトルのみを判別することができるようになりました。
③Windowsでファイル名に使えない文書名がある
私は初めて出会ったので若干詰まったのですが、いわゆる”予約デバイス名“というものです。
どうしてもそのままファイル名に使うことはできないので、完全一致する文書に関しては、最後に”_”を付与することでこれを回避しました。
## [[ ... ]] のみの行を記事タイトルとして取得
mo = re.match(r'\[\[.*\]\]$', line)
## 出力ファイル名設定(記事タイトル.txt)
if mo is not None:
## 行頭行末の[[]] の削除と、禁則文字(/ \ : * ? " < > |)置換
outTitle_tmp = re.sub(r'[\[|\]|\n]', '', re.sub(r'[\/|\\|\:|\*|\?|\"|\<|\>|\|\ ]', '_', line))
# |thumb| が入っているものは画像なので何もしない
# (上で | を _ に置換しているので _thumb_)
mo = re.search(r'_thumb_', outTitle_tmp)
if mo is None:
# 予約デバイス名の時は、最後に_をつける
mo = re.match(r'[AUX$|CON$|NUL$|PRN$|CLOCK\$$|COM[0-9]$|LPT[0-9]$]', outTitle)
if mo is not None:
outTitle_tmp = outTitle_tmp + '_'
outTitle = OUTPUTDIR + outTitle_tmp + '.txt'
## ファイル書き出し
こうして記事単位に分割したファイルの中で、サッカー選手テンプレートが適用されている記事をサッカー選手のものとして、モデル作成に使用します。
word2vecのモデル作成には、単語単位にパースした分かち書き状態のテキストが必要になるので、MeCabを利用して分かち書きを行います。
ここで、デフォルトの状態では、上述した選手名が姓と名で分割されてしまうという問題がでてきます。
これを回避するため、選手のフルネームをMeCabに辞書登録する必要があります。
今回必要な情報は”名前”と”読み”なので、これもWikipediaから抽出します。
登録する名前はテンプレート上の”名前”(設定されていない場合は記事タイトル)を、読みとしては”カタカナ表記”(設定されていない場合はMeCabにかけた読み情報)の部分を使用します。
| 香川真司,,,6058,名詞,固有名詞,人名,一般,*,*,かがわしんじ,カガワシンジ,カガワシンジ |
| 馬場悠,,,6058,名詞,固有名詞,人名,一般,*,*,ばばゆたか,ババユタカ,ババユタカ |
| 馬場悠企,,,6058,名詞,固有名詞,人名,一般,*,*,ばんばゆうき,バンバユウキ,バンバユウキ |
ここでざっと眺めていて気が付いたのですが、マスコットキャラがサッカー選手として登録されてたり…
(しかも、ふろん”た”が読めなかった模様)
| しかお,,,6058,名詞,固有名詞,人名,一般,*,*,しかお,シカオ,シカオ |
| ふろん太,,,6058,名詞,固有名詞,人名,一般,*,*,ふろんふとし,フロンフトシ,フロンフトシ |
| 東京ドロンパ,,,6058,名詞,固有名詞,人名,一般,*,*,とうきょうどろんぱ,トウキョウドロンパ,トウキョウドロンパ |
漫画のキャラがサッカー選手として登録されてたり…
| 大空翼,,,6058,名詞,固有名詞,人名,一般,*,*,おおぞらつばさ,オオゾラツバサ,オオゾラツバサ |
| 岬太郎,,,6058,名詞,固有名詞,人名,一般,*,*,みさきたろう,ミサキタロウ,ミサキタロウ |
| 若林源三,,,6058,名詞,固有名詞,人名,一般,*,*,わかばやしげんぞう,ワカバヤシゲンゾウ,ワカバヤシゲンゾウ |
してました。
ちょっと不思議な感じですが、記事として存在しますしご愛敬ということで。。。
さて、選手名の辞書登録も済んだところで、本来の目的であるword2vecのモデル作成に入っていきます。
とはいっても、さきほど辞書登録したMeCabで対象の文書を分かち書きしながら1ファイルにまとめて、word2vecに渡すだけです。
| ## 対象文書の分かち書き |
| ## 元記事ファイル |
| # このフォルダにサッカー選手の記事だけが保管されている |
| INPUTFILES = glob.glob('./dataset/jawiki_footballer/*.txt') |
| # 学習用テキスト |
| LEARNINGFILE = 'learning.txt' |
| # 学習後のモデル |
| MODELFILE = 'wiki_word.model' |
| parser = MeCab.Tagger("-Owakati") |
| with open(LEARNINGFILE, mode='a', encoding='UTF-8') as fw: |
| for inputFile in INPUTFILES: |
| with open(inputFile, mode='r', encoding='UTF-8') as fr: |
| for line in reader: |
| # 分かち書きして、ファイル出力 |
| fw.writelines(parser.parse(line)) |
| print("Parse Complete") |
| ## word2vec モデル作成 |
| data = word2vec.Text8Corpus(LEARNINGFILE) |
| # ベクトルの次元数100, 反復学習回数10回 |
| model = word2vec.Word2Vec(data, size=100, iter=10) |
| model.save(MODELFILE) |
| print("Learning Complete") |
これまでの記事解析と同様にWikipediaの記事から日本国籍を持つ選手の一覧を作成(ここは割愛)して、類似度を比較していきます。
| # 学習済みモデル名定義 |
| MODELFILE = 'wiki_word.model' |
| # 学習済みモデル読み込み |
| if os.path.exists(MODELFILE): |
| model = word2vec.Word2Vec.load(MODELFILE) |
| print("Load Complete") |
| else: |
| print("Model file not found") |
| exit() |
| # ベストイレブンリスト |
| best11s = [ |
| 'リオネル・メッシ', |
| 'クリスティアーノ・ロナウド', |
| 'ネイマール', |
| 'ルカ・モドリッチ', |
| 'トニ・クロース', |
| 'アンドレス・イニエスタ', |
| 'ダニエウ・アウヴェス', |
| 'マルセロ', |
| 'セルヒオ・ラモス', |
| 'レオナルド・ボヌッチ', |
| 'ジャンルイジ・ブッフォン' |
| ] |
| # 日本人選手の一覧を読み込み |
| with open('footballerJPN.txt', mode='r', encoding='UTF-8') as fr: |
| reader = fr.readlines() |
| for best in best11s: |
| max_score = 0 |
| max_name = '' |
| for japanese in reader: |
| score = 0 |
| # 類似度比較 |
| score = model.similarity(best, japanese) |
| # 類似度が一番高ければ更新 |
| if score > max_score: |
| max_score = score |
| max_name = japanese |
| print("{}\t{}\t{}\n".format(best, max_name, max_score)) |
| 選手名 | ポジション | 日本人選手 | 類似度 | 所属クラブ |
| リオネル・メッシ | FW | 平山相太 | 73% | ベガルタ仙台 |
| クリスティアーノ・ロナウド | FW | 本田圭佑 | 73% | パチューカ(メキシコ) |
| ネイマール | FW | 本田圭佑 | 67% | パチューカ(メキシコ) |
| ルカ・モドリッチ | MF | 明神智和 | 67% | AC長野パルセイロ |
| トニ・クロース | MF | 富田晋伍 | 86% | ベガルタ仙台 |
| アンドレス・イニエスタ | MF | 梶山陽平 | 66% | FC東京 |
| ダニエウ・アウヴェス | DF | 森脇良太 | 69% | 浦和レッズ |
| マルセロ | DF | 森脇良太 | 68% | 浦和レッズ |
| セルヒオ・ラモス | DF | 細貝萌 | 70% | 柏レイソル |
| レオナルド・ボヌッチ | DF | 細川淳矢 | 68% | 水戸ホーリーホック |
| ジャンルイジ・ブッフォン | GK | 川口能活 | 71% | SC相模原 |
本田選手と森脇選手には分身の術を身に着けていただく必要がありそうです。。。
FW、DFともにサイドの選手が2回選出されています。記事上は左右のサイドにはあまり言及していないのかもしれませんね。
ちなみに、明神選手が39歳、川口選手が42歳、それ以外の選手は選手が31~33歳とベテランぞろいです。20代の選手は一人もいませんでした。
ベテランの方がエピソードが多くて記事が充実している、というのは理由の一つかもしれません。
いかがでしたでしょうか。
ちょっとお遊び的な企画になりましたが、これで少しでも自然言語処理(とサッカー)に興味を持っていただけたら幸いです。
余談ですが、モデル作成時のパラメータによって結果がかなり変わるので、色々と試してみると面白いかもしれません。
こちらで試した中で一番衝撃的だったのは、GKを含めた全ポジションが中田英寿選手という結果でした。。。
