


こんにちは。エンベデッドソリューション事業部の瀧澤と申します。
”文書などに添付されているロゴ画像が適切なフォーマット(サイズ、余白 etc)で使用されているかの確認を画像処理を使って出来ないか”、という問い合わせを社内にて受けました。
“特徴点抽出を行った画像認識を行ったらどうか”という回答をしましたが、私自身も聞きかじり程度の知識でしたので、実際に使用してみようと思い立ったのが本記事を投稿する経緯になります。
GUIベースでのテストアプリケーションを作り、考え方が正しかったか、アルゴリズムの精度はどこまで許容できるかという点で調査を行いましたので、結果を報告します。
画像上における、ある法則に基づいた特徴の点群になります。(例えば画素間のエッジなど)
この”ある法則”という点において幾つかのアルゴリズムが存在します。
- 検出したい画像(以下、query)と検索対象画像(以下、train)それぞれで特徴点を抽出する。
- query-train間で類似する特徴点を調べる。(マッチング)
- マッチング結果を元に画像の情報を求める。
1.、2.についてはOpenCVのAPIを使用して実現します。
3.については自前で計算を行い、結果を確認することとします。
また、3.で取り出す情報は下記の情報とします。
- 拡縮情報
- 回転情報
- アスペクト比
- Windows 10
- Microsoft Visual Studio Community 2015
- OpenCV 3.4.1
queryとして自作の”くれすこ”ロゴを使用します。
trainのバリエーションについては後半にて説明させて頂きます。

抽出アルゴリズムにはOpenCVに搭載されているAKAZEを使用します。
OpenCVには他にも幾つか使用出来るアルゴリズムがあるのですが、事前に調べた結果、ロバスト性の高いと謳われているこちらを使うことにしました。
OpenCVではFeature2Dクラスを共通のIFクラスとして各アルゴリズムの実装が行われており、下記のように操作します。
| cv::Mat image = cv::imread("file path"); // 画像 |
| std::vector〈cv::KeyPoint〉 keypoint; // 特徴点群 |
| cv::Mat descriptor; // 特徴記述子 |
| cv::Ptr〈cv::Feature2D〉 feature = cv::AKAZE::create(); // 抽出パラメータを変更する場合は、引数を追加する |
| feature->detectAndCompute(image, cv::noArray(), keypoint, descriptor); // 特徴点の抽出と記述を行う |
また、抽出した特徴点をグラフィカルに表示するために元画像に重畳するAPIも用意されています。
| cv::Mat dst; |
| cv::drawKeypoints( |
| image, // 入力画像 |
| keypoint, // 特徴点 |
| dst, // 出力画像 |
| cv::Scalar::all(-1), // 色 -1の場合は各ポイントごとにランダムに色が選ばれる |
| cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS // 描画のオプション DRAW_RICH_KEYPOINTSを選んだ場合は、キーポイントのサイズと方向が描画される |
| ); |
では早速queryを使って特徴点抽出を行ってみます。
下記のような結果となりました。様々な色の〇が重畳されていますがこちらが特徴点になります。
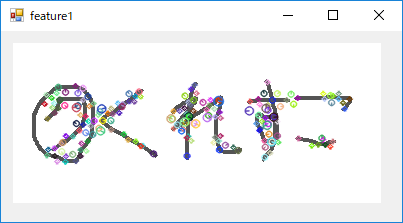
下記はkeypoint変数の中身を展開したものです。
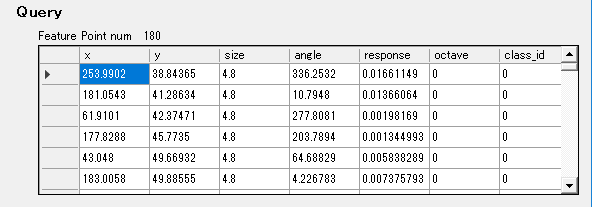
このように特徴点の中心となる座標情報等が格納されています。
sizeが特徴の大きさ(〇の大きさ)、angleが特徴の向き(〇の中の線の向き)になります。
query上では180個の特徴点が抽出できました。
先ほど抽出したqueryと同様に、train側の特徴点も抽出します。
まずはお試しという事で、大きめの白紙の中に同じサイズのロゴを張り付けた画像をtrainとして使用します。

特徴点を抽出します。

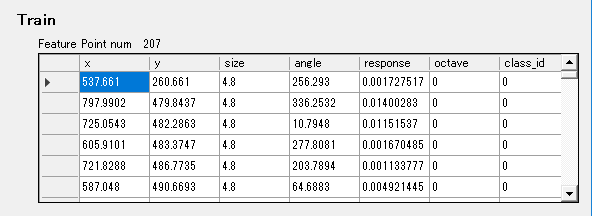
特徴点情報は下記になります。今回は207点の特徴抽出が行えました。
ではマッチングを行います。
マッチングアルゴリズムもOpenCVでは幾つか種類がありますが、今回は一番単純な総当たりマッチングにて行います。
使用方法は下記の通りです。
| std::vector〈cv::DMatch〉 matches; // マッチング結果出力先 |
| cv::BFMatcher matcher(cv::NORM_L2, true); // 第二引数をtrueにするとクロスチェックになる。falseの場合はquery->trainのみ |
| matcher.match(query_descriptors, train_descriptors, matches); // queryが元画像。trainが検索対象の画像 |
また、こちらもマッチング結果を画像に重畳するAPIが提供されています。
| cv::Mat dst; // 出力画像 |
| cv::drawMatches(query_img, query_feature_points, train_img, train_feature_points, matches, dst); |
下記がマッチング結果になります。

左側にquery、右側にtrainを置き、両画像間でマッチした特徴点を線で結んでいます。
数が多いため見辛いですが、多くの特徴点がマッチし、また線の傾きが同じであることからほぼ正しくマッチングできていることがわかります。
下記は変数matchesを展開したものになります。
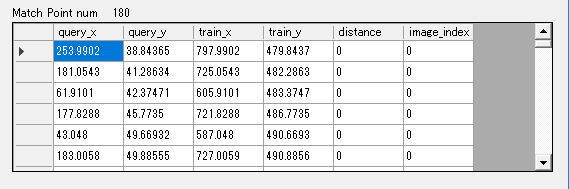
本来cv::DMatchにはquery、trainのkeypoints vectorのindexが入っているのですが、便宜上そのindexの指し示す特徴点のx,y座標を表示しています。
distanceがマッチングした際の類似度です。
低いほど良い結果となり、0は完全一致になります。
マッチングの出力としてquery-train間でマッチする特徴点の情報が得られました。
ここからはその点群を元にtrain上のロゴ画像の情報を取り出してみます。
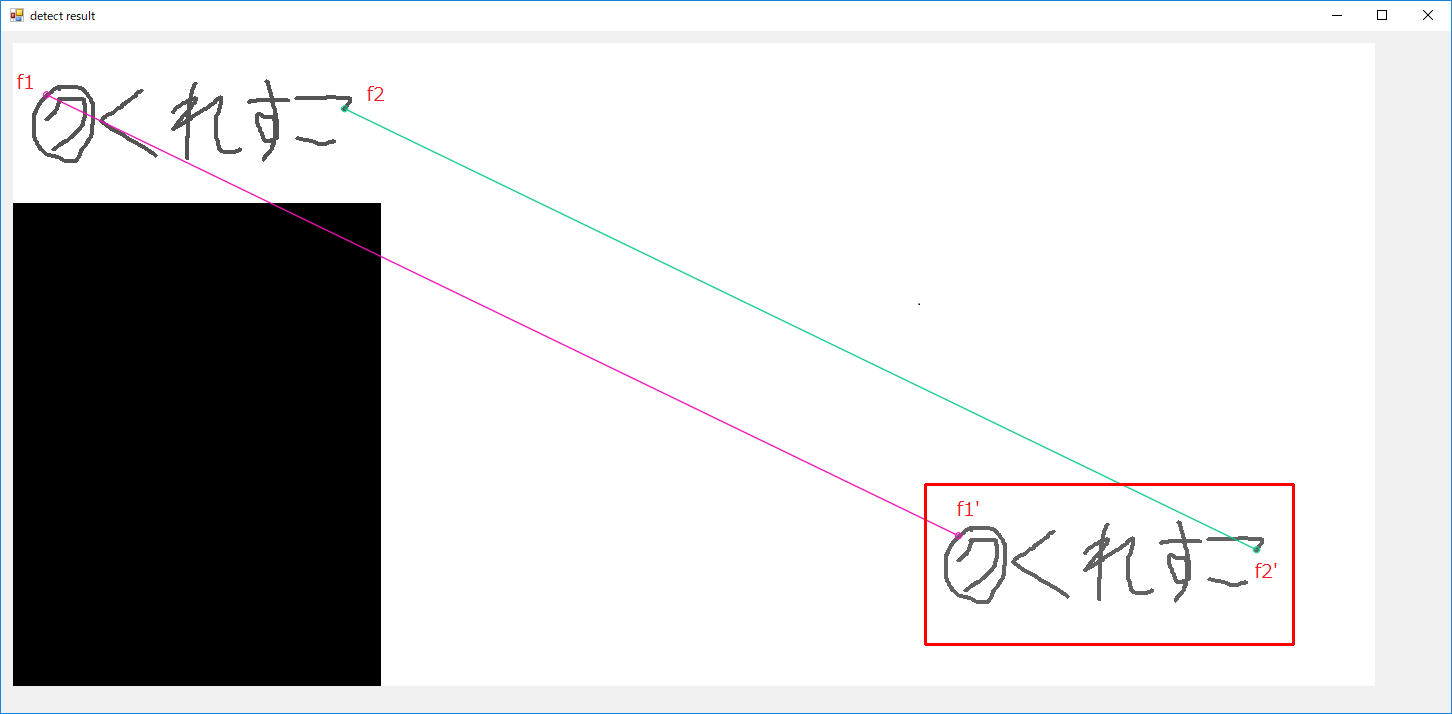
先ほどのマッチング結果から2点のみ抜き出しました。
この時queryの特徴点をf1、f2とし、trainの特徴点をf1’、f2’とします。
特徴点マッチングが正しく行えていると仮定すれば、f1-f2とf1′-f2’は相似の関係が成り立つと考えられますので、
両者の比較を行う事でtrain側の画像情報を取り出すことが出来ます。
今回取り出そうとしている情報の場合、下記の求め方を使います。
- f1(‘)とf2(‘)のベクトルの長さを比較し、拡縮
- ” ベクトルの向きを比較し、回転
- ” x:yの比率を比較し、アスペクト比
ここでいうベクトルとは任意の点間を結ぶ直線です。
片方の点の座標を原点として、
ベクトルの長さを求めるには、√(x^2+y^2)
ベクトルの向きを求めるには、atan(y/x)
をそれぞれ使います。
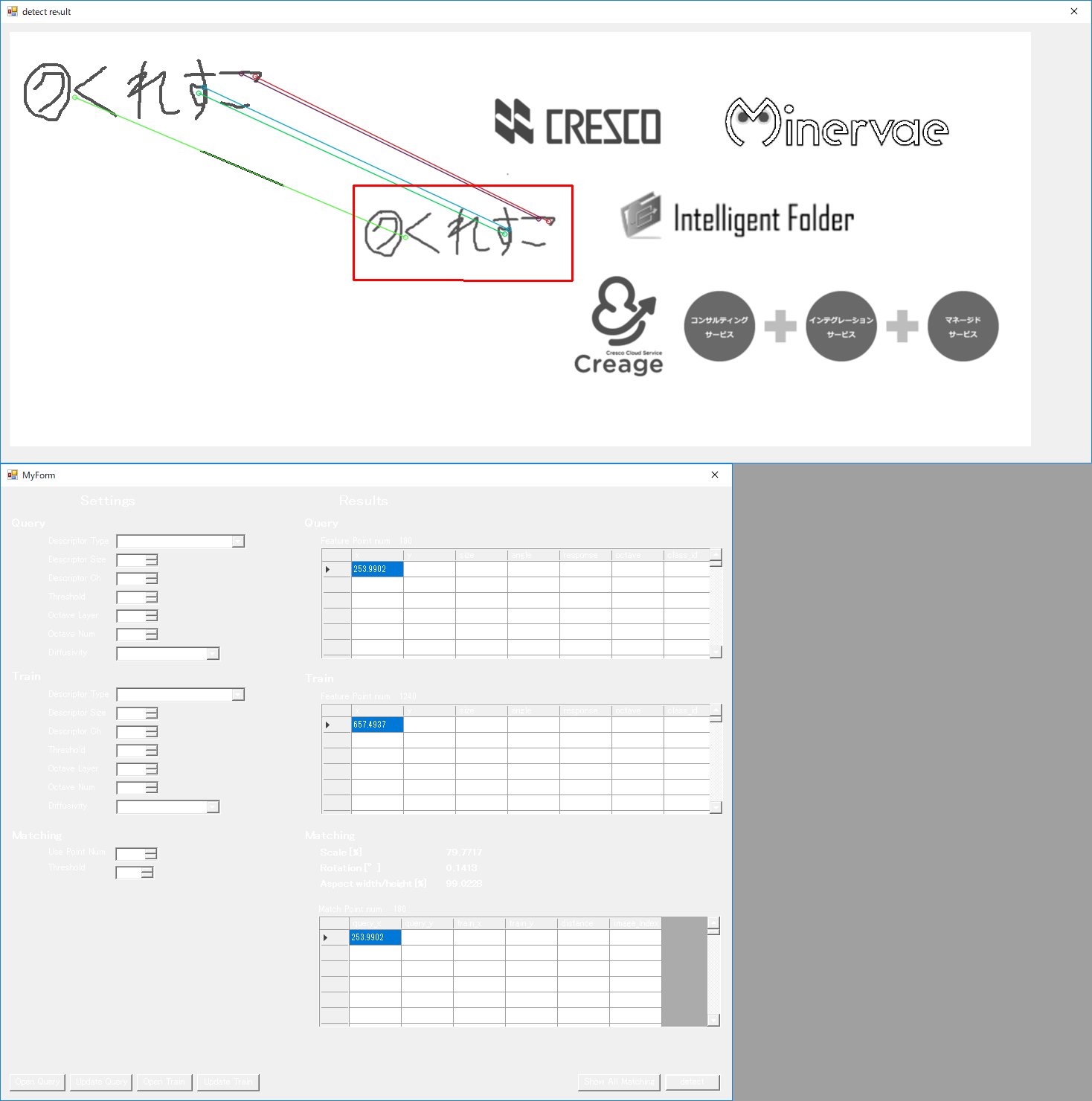
これまで説明してきた内容を実装したテストアプリを作成しました。
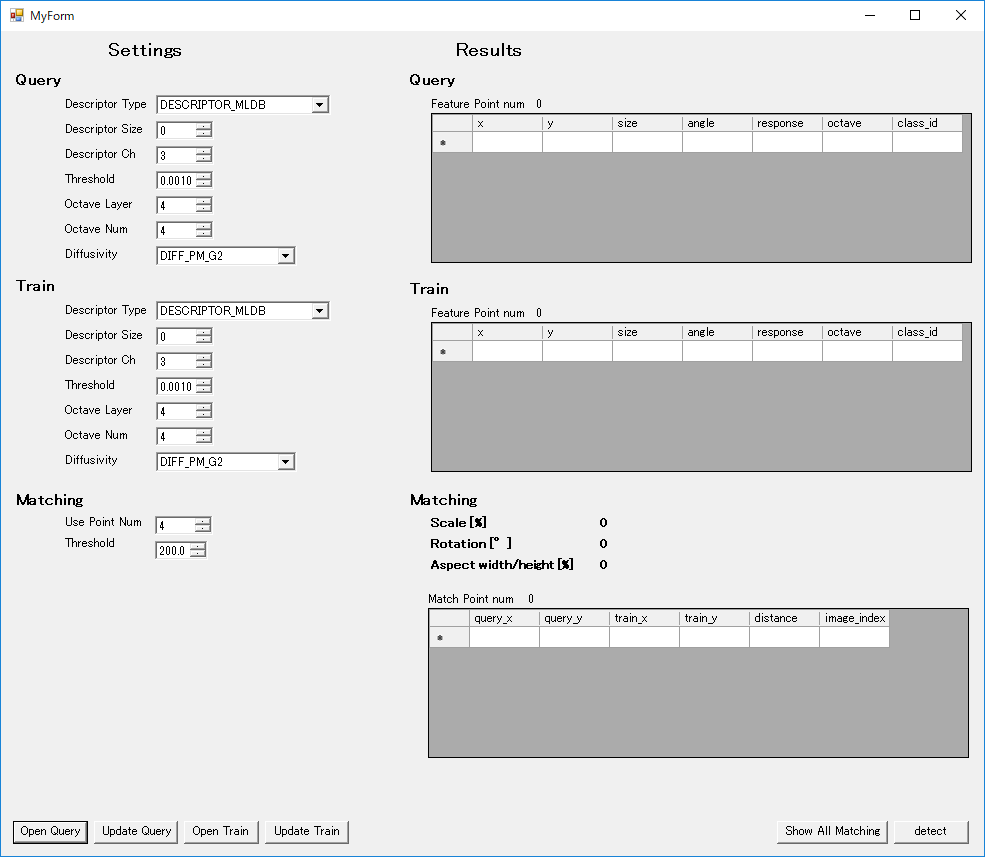
画面左上:特徴点を抽出する際のAKAZEのパラメータ(表示されているのはデフォルト値)
画面左下:Maching及び情報取り出し時のパラメータ(Use Point Num:抽出に使用する点の数、Threshold:使用するdistanceの最大値)
画面右:諸々の結果
また、マッチング結果表示の際にtrain上のロゴ画像を赤四角でくくるように出力しています。
こちらを使ってテストを行っていきます。
まずは等倍、且つ回転なしのテストを行います。
白背景にロゴ
各種ロゴ
文書上のロゴ
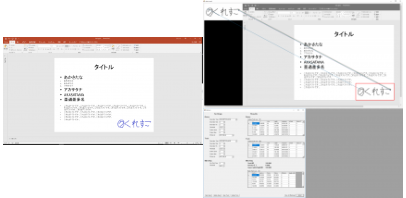
寸分の狂いなく検出できていますね。素晴らしい。
ここからはロバスト性の確認に移ります。まずは回転をかけてみます。
各種ロゴ(上から順に30,45,60,90°の回転)
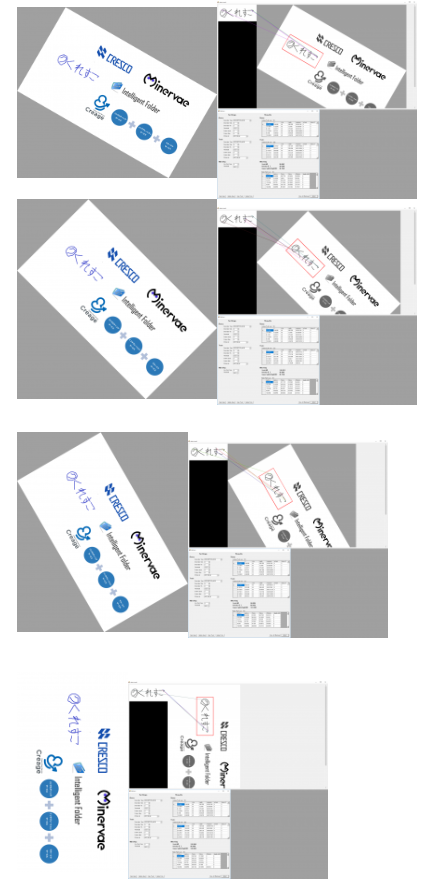
こちらも問題なしです。
但し、回転をかけた時点でdistanceが0でマッチングした点は無くなりました。(画像上で使っているのは80 ~ 120のdistance)
次は縮尺です。
各種ロゴ(上から順に50,80,90,110,120,150%の縮尺)
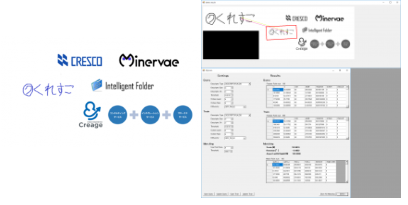


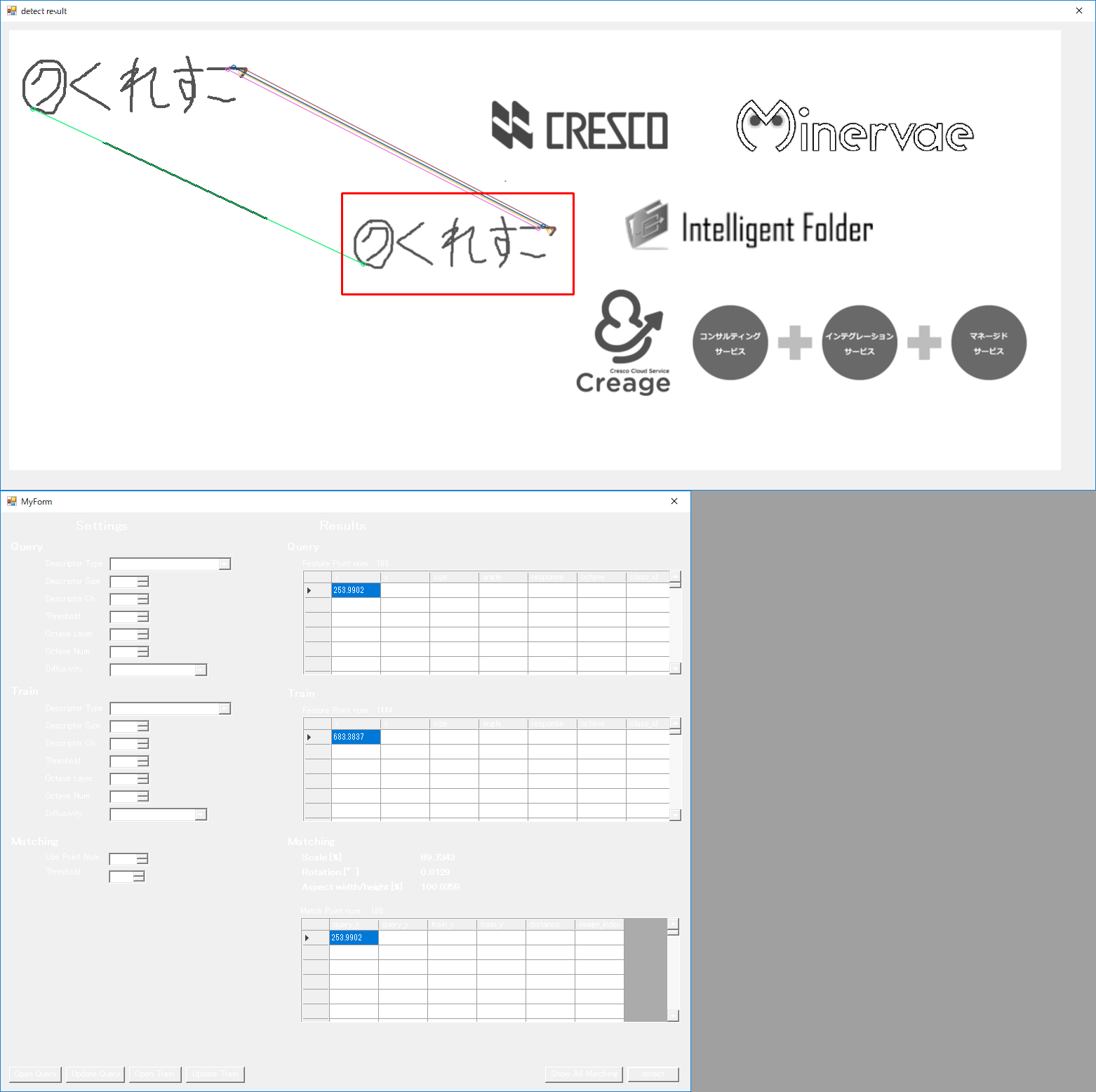

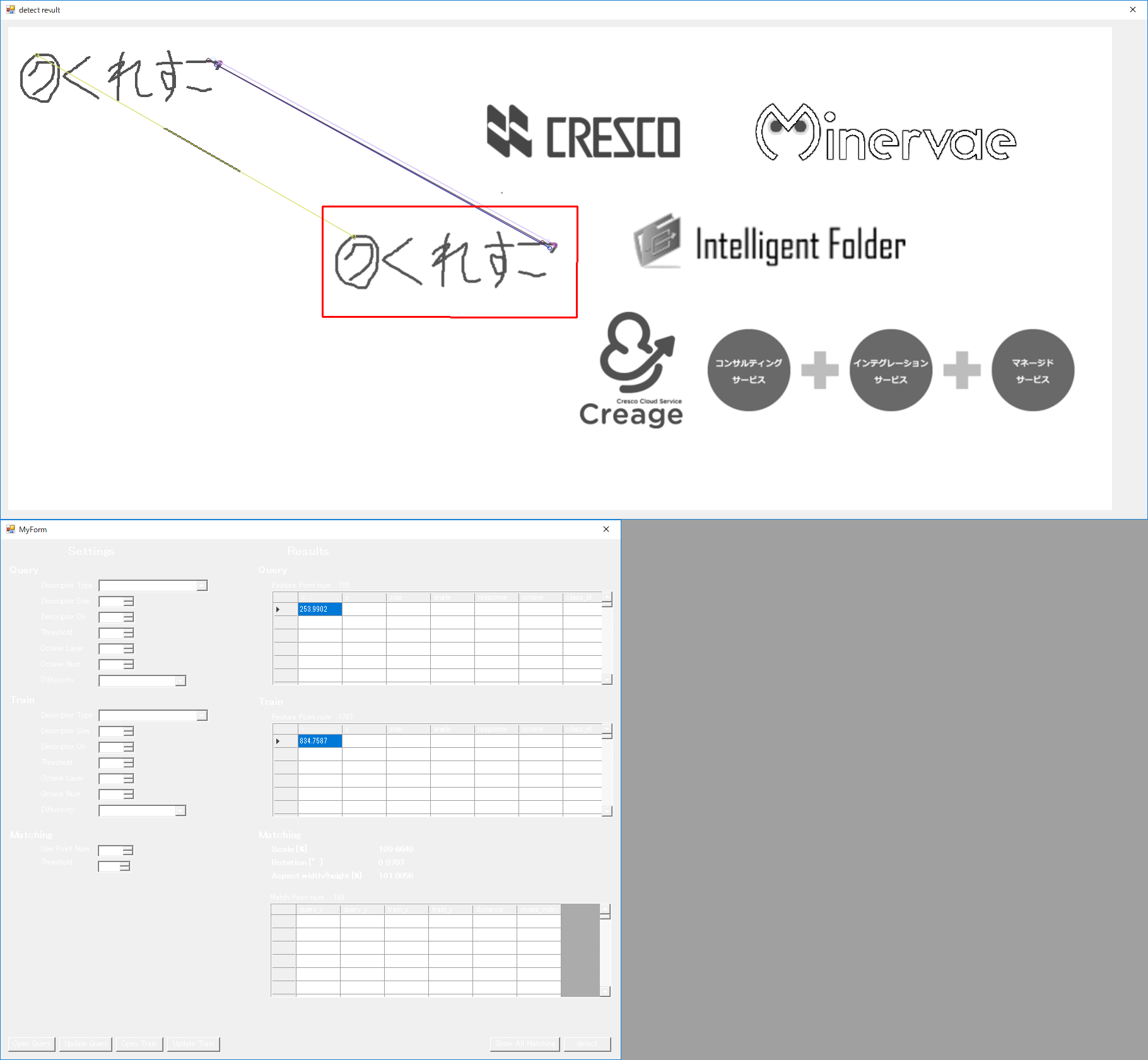

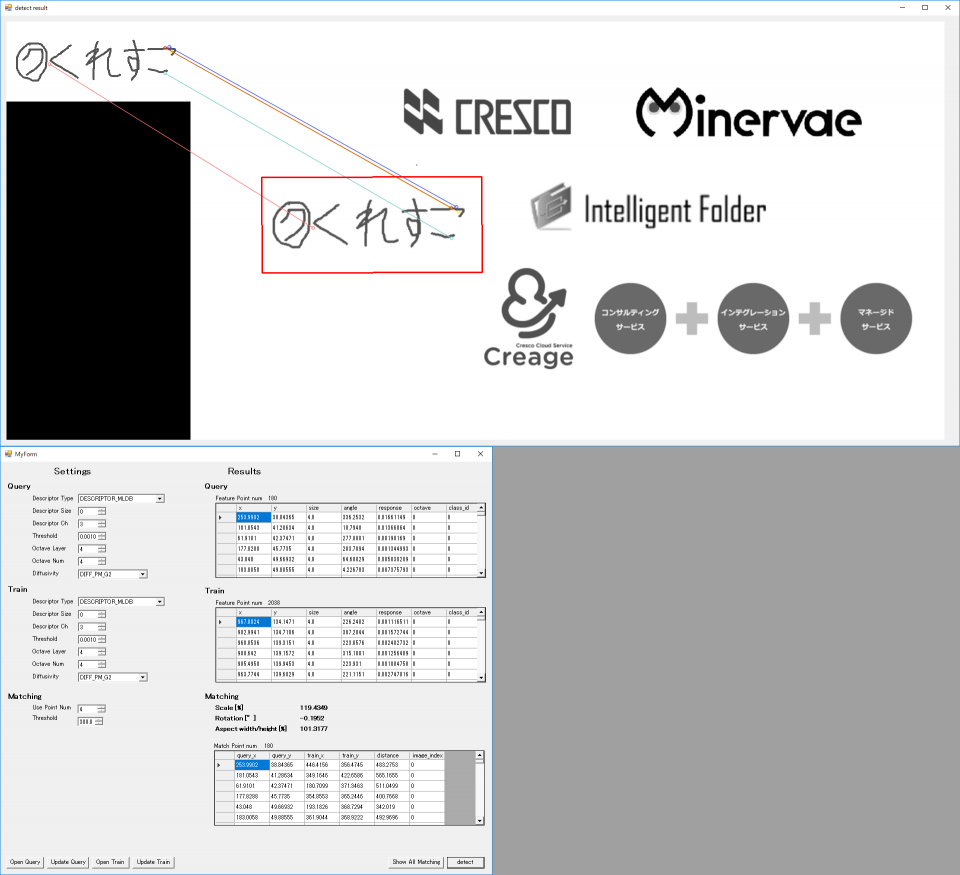

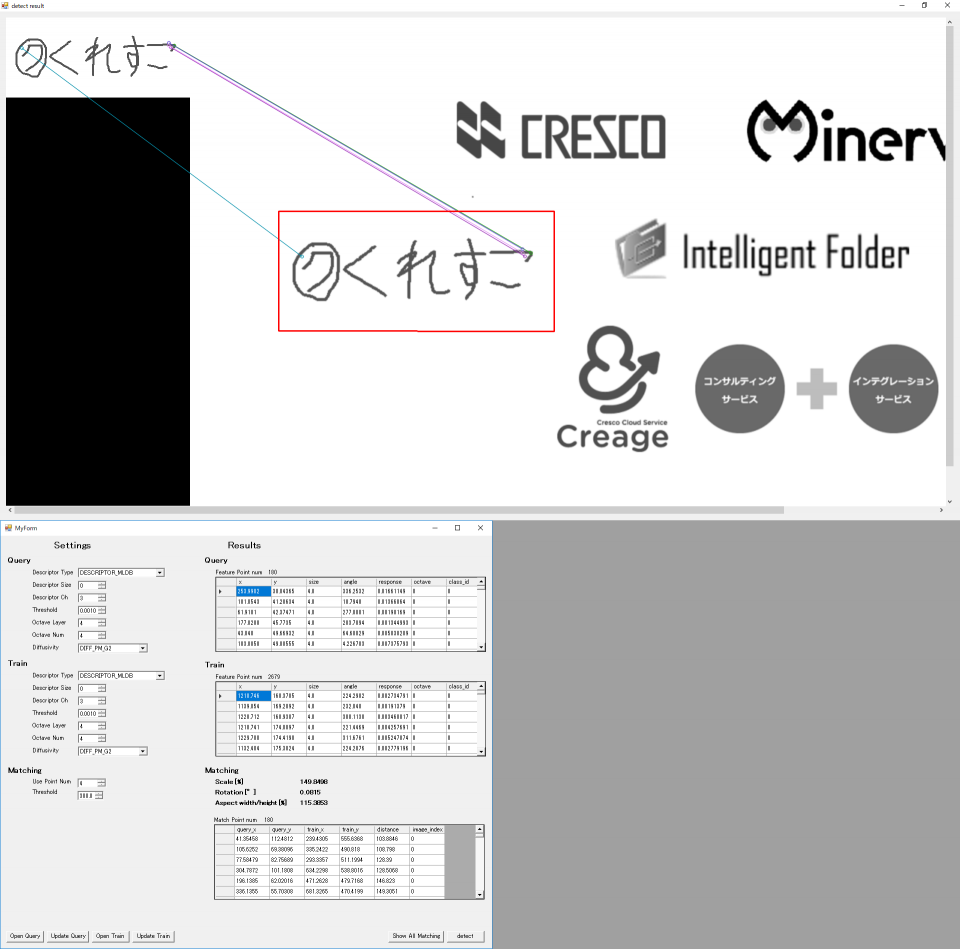
Thresholdを200にした状態だと、点群が見つからない状態になっていたので、300に上げています。
こちらも中々良好ですね。
さすがに50%は画素が潰れてしまっているのか、thresholdを300に上げても有効な特徴点は2点しか見つかりませんでした。
これ以上閾値を上げてしまうと誤検知まで含まれてしまうので、この辺りが限界だと思います。
以上が調査内容になります。
基本的にqueryと縮尺が固定であるならば問題なく認識できますね。
特に縮尺はもっと検出率が低いと予想していましたが、だいぶ健闘していたように見受けられます。
Deep Learningのような大掛かりな装置を用いなくても、これだけの精度で認識できた事に感動しました。
トライ&エラーもしやすいので、ある程度の制限がある画像認識においては使用に値するのではないでしょうか。
では、
長文にお付き合い頂きありがとうございました。
