


この記事は 『CRESCO Advent Calendar 2018』 1日目の記事です。
テクニカルエバンジェリストをやってます井上 (祐)です。
本記事では、敵対的生成ネットワーク(GAN:Generative Adversal Network)によって生成された画像を使いWatsonの画像認識(Visual Recognition)が騙されるか試してみます。

人工知能(AI)が“描いた”作品、約4800万円で落札
米競売大手クリスティーズ(Christie’s)のオークションで10月25日、AIが描いた作品がオークションに出品(世界初)され、予想落札価格の43倍となる43万2500ドル(約4800万円)で落札され話題となりました。 《 Edmond De Belamy(エドモンド・ベラミーの肖像)》と題されたこの作品は、パリを拠点とするアーティストや研究者らのグループ「Obvious」が開発したAIによって生成された画像です (Cf. AIが“描いた”作品、約4800万円で落札。予想落札価格の43倍 / 美術手帖)。

敵対的生成ネットワーク(GAN)の概要
今回の出来事は、AIが苦手とされていた創作分野の壁をひとつ超えた事例と言って良いかと思います。 制作に使われたAIは画像生成モデルの敵対的生成ネットワーク(GAN)で、14世紀から20世紀までに制作された肖像画1万5000点のデータを使ったとのこと。
GANに関しては日経ソフトウェア11月号(9/22発刊)、2019年1月号(11/24発刊)の2号に渡り解説とプログラムを執筆したので、そちらを参照してもらえればと思います。
ここでは簡単に触れておきます。
GANは画像を生成する生成モデル(Generator)と、入力された画像が本物か、生成モデルが生成した偽物の画像かを判別する識別モデル(Discriminator)の2つを互いに学習させて、リアルな画像生成を行うというものです。
例えるなら、偽札を作る偽造者とそれを見破る警察の関係に似ています。偽造者は警察に見破られないよう偽札を作りますが、警察はこれを見破ります。そして今度は見破られないようにと偽札を作りなおします。これを警察が見破って・・・という事を繰り返し、やがて偽物が本物と見分けがつかなくなるほどの精度になるというものです。
このGANについてヤン・ルカン氏(FacebookのAI研究所所長)は、“機械学習において、この10年間でもっとも面白いアイディア”と言っています。
Generator、Discriminatorの2つのニューラルネットワークから構成されるGAN
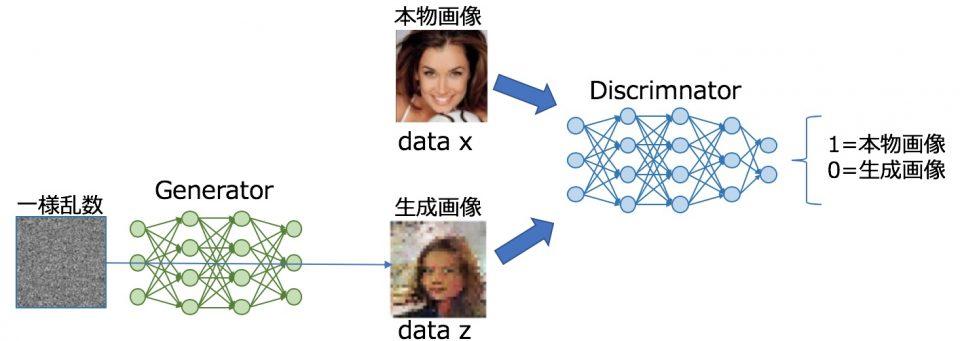

画像生成の流れ
ニューラルネットの学習はDiscriminator、Generatorの順に行います。
Discriminatorは画像を入力し、それが本物の画像か生成された偽物の画像か識別します。
学習データとして本物画像とラベル’本物画像(1)’、生成画像とラベル’偽物画像(0)’を与え、これを正しく見分けられるよう学習します。
Generatorは一様乱数を入力し、画像の生成を行います。
生成した画像をDiscriminatorに入力し、生成画像つまり偽物を’本物画像(1)’と間違わせるよう学習します。このためGeneratorは、Discriminatorが生成画像を本物と見分けられなかった誤差を小さくするよう学習します。他のネットワークの誤差を学習に使うところが、面白いところです。
さて、落札された肖像画の右下に署名のようなものが書かれていますが、良くみると数式が記されています (Cf. AI絵画、大手オークションで初の落札 予想額の40倍超)。
これ、GANの価値関数となります。(下記は論文より)
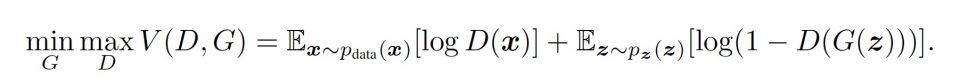
価値関数からDiscriminatorは本物画像、生成画像を正しく分類する確率を最大化しようとします。これは右辺第1項の本物画像に対する識別結果が1を示すよう学習します。生成画像が正しく偽物と識別ができれば右辺第2項のD(G(z)))が小さくなりますが、右辺のlog(1-D(G(z)))によって値が大きくなります。
一方でGeneratorは生成画像が偽物と識別されたくないためD(G(z)))が大きくなるよう学習し、結果的に右辺のlog(1-D(G(z)))が小さくなります。
このような動作から学習当初はGeneratorの精度が低く、Discriminatorによって偽物と見破られてしまい、価値関数の値が大きくなります。Generatorは値を小さくするよう学習を行うため、D(G(z))が大きくなるよう画像の生成を行う事となります。

画像生成
今回、実装した画像生成モデルはDeep Convolutional Generative Adversarial Networks(DCGAN)と呼ばれるもので、画像識別でおなじみの畳み込みニューラルネットワーク(CNN)を実装しています。ただし、通常のCNNとは違いプーリング層がありません。他に工夫した点は、Batch Normalizationの適用、Generatorの出力層に活性化関数としてtanh、Discriminatorの全ての活性化関数にLeakyReLUを使用した点です。
今回、論文と違う点は生成する画像サイズを32×32としたのと、畳み込み層を1層少なくしています。(サイズを小さくし、更新パラメータを減らし計算を軽くしたため)
Generatorの構成
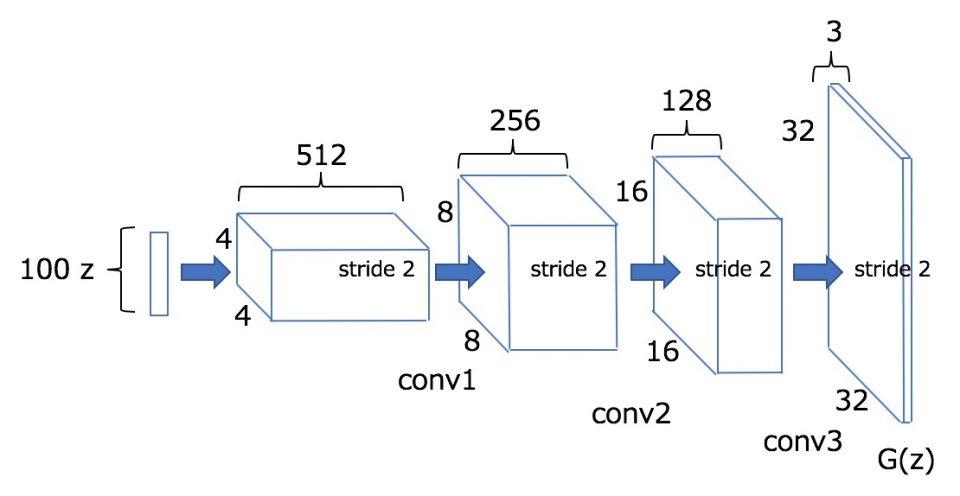

この画像は何でしょうか?
生成したい画像の本物画像はFlickr APIによってダウンロード(300枚/テーマ)を行い、その後KerasのImageDataGeneratorを使って画像を水増して、Discriminatorの学習画像(12,000枚/テーマ)とします。




どうでしょう、何が生成された分かりますか?
上から順にトマト、トイプードル、パンダ、名古屋城になります。

Watson騙される!?
画像をWatsonの画像認識(Visual Recognition)に入力し、意図した通りに識別するか確認します。
まずは、トマト画像から試してみます。 Watsonが判別した結果と確信度を画像の下に表記しました。王冠マークは、”騙せた!”と思うものに付けています。
左の2枚は、赤唐辛子の仲間だと思っていますね。左から3枚目はミニトマトだと思っています。学習データにはミニトマトも含まれていたので、それらしい画像が生成されています。一番右はトマトの料理と思っています。まぁ、概ね騙せているのではないかと。

今回、生成したなかで最も難しかったテーマです。人間からみても微妙で、Watsonから見てもトイプードルには見えなかったようです。ですが左の2枚は犬だと思ってます。

パンダは完全に騙されてます。右4枚は0.82〜0.96という高い確信度ですから、Watsonは相当自信をもってパンダだと思っています。

最後は名古屋城です。まぁまぁ雰囲気のある画像になっていると思います。切手のデザインにありそうな感じです。Watsonは名古屋城を知らないのかもしれませんが、建物だと思っています。


おわりに
AIが生成した画像はいかがでしたか?もっと高精細な画像生成も行えますが、今回は手軽に作った画像でWatsonの画像認識を試してみました。
このように一様乱数から画像を生成するGeneratorですが、実はリアルな画像を作ろうと頑張ってはいないんです。これぽっちも。
Generatorは、ただひたすらDiscriminatorから”イイネ”と言われたくて学習してます。(Discriminatorの損失を使って、Generatorの最適化しており生成画像そのものからは何も学んでません)
こうして”イイネ”をもらっていたら、リアルな画像が生成できたというものです。なので、学習中の損失関数の値を見ても画像がうまく作れているか実は分かりません。そのため学習途中で画像を出力させて確認します。
パンダの学習画像を集めている時は、かわいくって癒されますが、生成過程の画像は、恐ろしい別の生き物が生成されています。なので、動物の画像生成には、少々度胸が必要です(笑)。キリンの画像生成にもチャレンジしたのですが、やばい生物をたくさん生成してました(怖)
ちなみに、Discriminatorから毎回”イイネ”って言われるよう、平均的な画像(同じ画像)を生成することがあります。これはモード崩壊と言って、未だ原因や対策が解っていない現象です。(2018年11月に発表されたpacGANという方式にて対策が提案されていますので、今度試してみようと思います)
でも、この現象って、なんだかGeneratorがサボることを覚えたみいでチョット人間味を感じます。
では、1日目の記事は以上です。
明日以降も続く『CRESCO Advent Calendar 2018』 お楽しみに。
次はオークションに出品してみようかな・・・

