


こんにちは、技術研究所のウエサマです。
このエントリーは”Azure Machine Learningでナンバーズ予測”の後編となります。
前編はこちら⇒Azure Machine Learningでナンバーズ予測(前編)
チュートリアル部分の記事が長くなるため、先に”まとめ”と”予想実績”について記載します。
試してみたい方は、後半のチュートリアルをご覧ください。

まとめ
Azure Machine Learning(以下、Azure ML)は、機械学習に必要なモジュールをドラッグ&ドロップにより配置し、モジュール間をマウスで結んでいくだけという非常に簡単なユーザインターフェースで開発が行えた。できあがった成果物もワンクリックでWebサービス化でき、外部からの呼び出しサンプルも生成するため生産性の高いツールと思います。

Azure Machine Learningで予測モデルを作成
予め用意されている線形回帰を使用したが、別のアルゴリズムを利用する事も可能、もし用意されていない場合は自身で開発する事も可能。

作成したモデルをWebサービスとして公開
公開したWebサービスを呼出すためのサンプルプログラムの生成も行ってくれるため、アプリへの組込みが行いやすい。

題材はナンバーズ3の予測とした
・身近でお手軽、まんがいち当たると嬉しい^o^
・過去の当選番号データがネットから入手可能
・月~金開催のため、試す機会が多い

予測値の偏り問題への対処
前編で欠点とした下記の問題への対処となります。
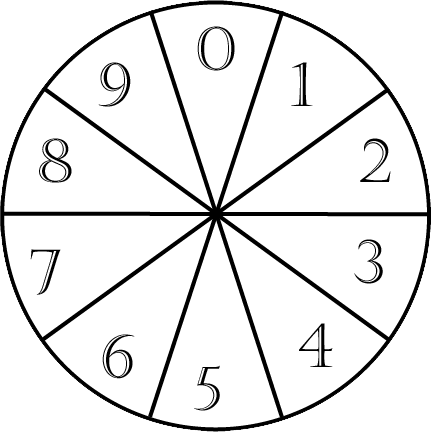
例えば、最新の出目が5の場合に差分の予測が「-5~4」の場合は、次の出目を算出できますが、この範囲外の差分が予測された場合に出目の算出ができない事態となります。この点は改良が必要ですね。(下表の灰色部分が予測できない範囲)

単純に下図に示すルーレットにて範囲を超えても出目が予測できるよう考慮することとした。
この時点で既に予測と言いがいたが・・・数字は3桁捻出しなくてはいけないし・・・
上記の例ですと、出目が5で差分が-6だった場合は、ルーレットを左回りたどり次回の出目予測は9とします。差分が5だった場合は右回りとし予測する出目は0とします。

予測の実績
学習データを使った予測評価の時点で、すでに当たらないのは分かっていましたが話しを進めます。
結論から言うと、ぜんぜん当たりません・・・そこは予想通り(笑)
| 項目 | 内容 |
| 開催回(1/7~ 1/15) | 4312回 ~ 4319回 (8回) |
| 対象 | ナンバーズ3 |
| 勝敗 | 0勝8負 |
| 百の位の的中回数 | 3回/8回 |
| 十の位の的中回数 | 2回/8回 |
| 一の位の的中回数 | 1回/8回 |
予測と抽選番号
| 回 | 予想番号 | 抽選番号 | |||||
| 4312 | 0 | 0 | 3 | → | 6 | 0 | 3 |
| 4313 | 7 | 4 | 1 | → | 7 | 9 | 7 |
| 4314 | 9 | 4 | 9 | → | 7 | 8 | 7 |
| 4315 | 9 | 2 | 9 | → | 9 | 4 | 6 |
| 4316 | 3 | 4 | 7 | → | 0 | 8 | 1 |
| 4317 | 6 | 2 | 8 | → | 7 | 2 | 7 |
| 4318 | 9 | 9 | 9 | → | 9 | 9 | 2 |
| 4319 | 3 | 4 | 9 | → | 2 | 8 | 3 |
やっぱり、当たりませんね(笑)
予測に使うモデルやデータ項目を変えるなどして、しばらく実験してみようと思います。
では、後半はチュートリアルにて作り方を説明します。

チュートリアルのゴール
ここでは、百の位を予測するモデル開発についてチュートリアルを記載します。十の位、一の位は同じ手順で開発ができますので省略します。
尚、本チュートリアルのゴールは下記とします。
・Azure MLでナンバーズ3を題材に予測をやってみる(当たれば、なお良し)
・百の位を予測するモデルを作る
・開発したモデルをWebサービスとして公開する

チュートリアルの流れ
チュートリアルのおおまかな流れは下記となります。
- ワークスペースの作成
- 学習データの登録
- モデルの作成、評価
- Webサービスとして公開
では、順に説明します。

ワークスペースの作成
モデルの構築、学習データの登録を行う作業スペースの準備を行います。

管理ポータルにログイン
https://manage.windowsazure.com

ワークスペースの作成
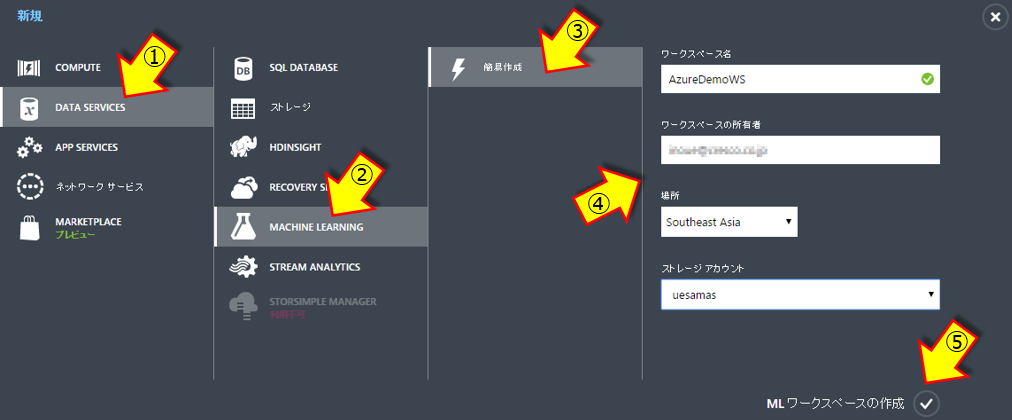
画面左下にある「+」をクリック

“DATA SERVICES”、”MACHINE LEARNING”、”簡易作成”を順に選択。
右側の入力項目を埋めてチェックをクリックします。
・ワークスペース名はユニークな名称
・場所は”Southeast Asia”を指定(他を指定すると場所の制約エラーとなる)
やっと前準備が終わり、ここから予測モデルを構築する楽しい作業となります。
ワークスペースは毎回作る必要はありませんので、上記にて作成したワークスペースに対し、いろいろな機械学習モデル、複数の学習データを載せ機械学習を試してみると良いと思います。

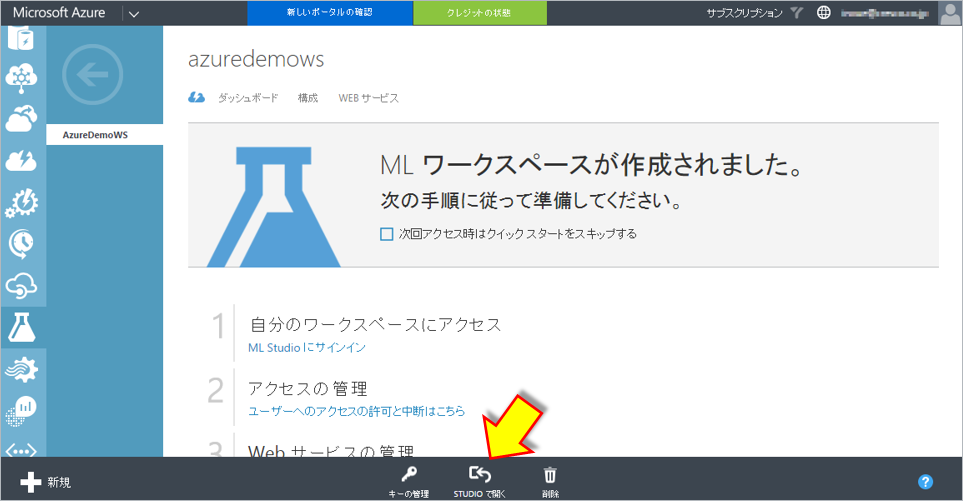
ML Studioを起動
予測モデルや学習データの登録はML Studioを使って行います。
まずは、作成したワークスペースを選択します。

画面下にある”STUDIOで開く”をクリックします。

学習データの登録
用意した学習データは下記となります。
過去の当選番号データをネットから入手し、扱いやすいよう加工しておきます。
前編の記事では過去50件を対象としていましたが、全件を対象としました。

データの概要
| 項番 | 項目 | 説明 |
| 1 | 対象 | ナンバーズ3、2015/1/15までの全データ4,318回 |
| 2 | 形式 | CSV形式 |
| 3 | 文字コード | UTF-8 |
| 4 | ヘッダーレコード | 有 |

ファイルフォーマット
| カラム | 項目名 | 内容 |
| 1 | 回数 | 開催回数 |
| 2 | 当選番号 | 3桁の当選番号 |
| 3 | 第1数字 | 当選番号の百の位 |
| 4 | 第1数字差分 | 前回当選番号(百の位)との差異 |
| 5 | 第2数字 | 当選番号の十の位 |
| 6 | 第2数字差分 | 前回当選番号(十の位)との差異 |
| 7 | 第3数字 | 当選番号の一の位 |
| 8 | 第3数字差分 | 前回当選番号(一の位)との差異 |

データの例(抜粋)
| 回,当せん番号,第1数字,第1数字差分,第2数字,第2数字差分,第3数字,第3数字差分 1,191,1,0,9,0,1,0 2,988,9,8,8,-1,8,7 3,194,1,-8,9,1,4,-4 (途中省略) 4314,787,7,0,8,-1,7,0 4315,787,9,2,4,-4,6,-1 4316,081,0,-9,8,4,1,-5 4317,081,7,7,2,-6,7,6 4318,992,9,2,9,7,2,-5 4319,283,2,-7,8,-1,3,1 |

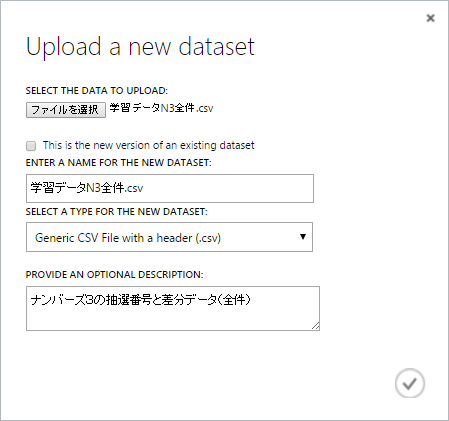
データのアップロード
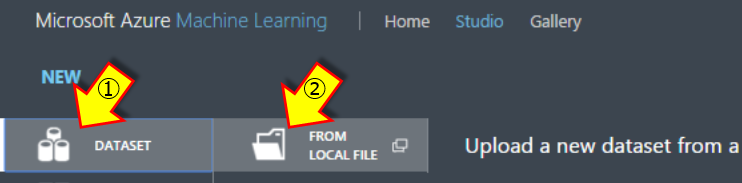
画面左下の「+NEW」をクリック。

下図①、②の順に選択し、ファイルアップロードダイアログを表示する
ファイルアップロードダイアログから”ファイルを選択”をクリックしアップロードするデータファイルを指定します。
ヘッダの有無は”SELECT A TYPE FOR THE NEW DATASET:”にて指定します。
内容に問題が無ければ、右下のチェックマークをクリックしファイルをアップロードします。
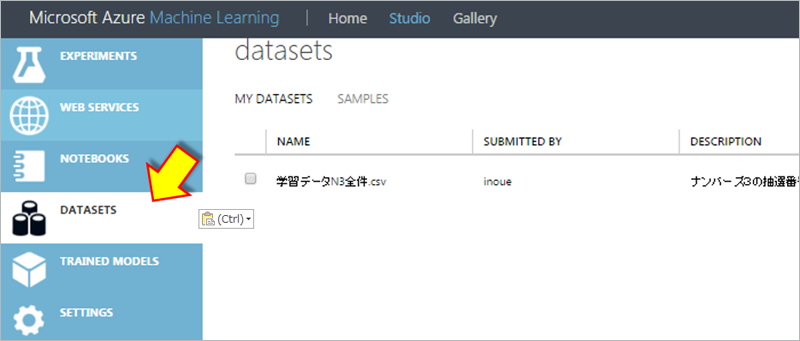
画面下に表示されるアップロード状況がcompletedになる事を確認します。

アップロードしたデータは”DATASETS”メニューから確認できます。

モデルの作成と評価

EXPERIMENTSの作成
モデルを構築するためのEXPERIMENTSを追加します。画面左下の「+NEW」をクリック。
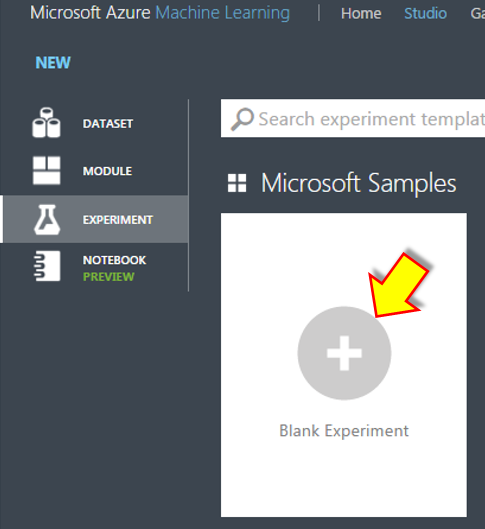
次に空っぽのEXPERIMENTSが表示されますので、画面上部の”Experiment created・・・”部分をクリックし、何を行う機械学習なのか分かるような名前を付けておきます。
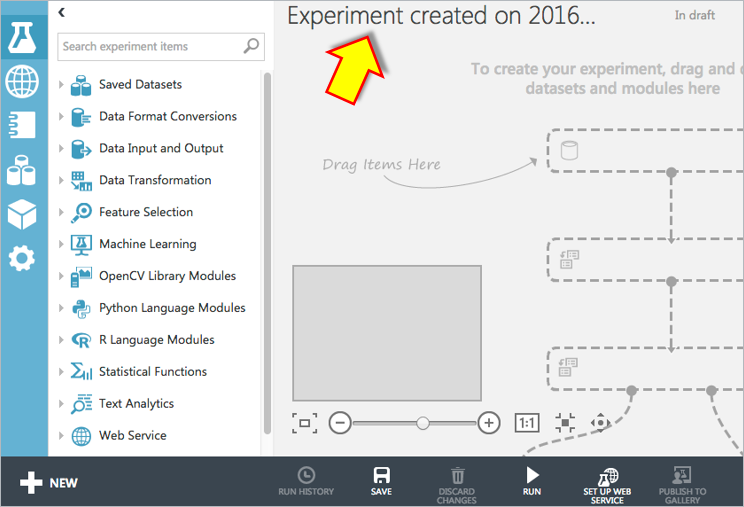

学習データの配置
左側のアイコンから”Saved Datasets > My Datasets”をクリックし、アップロードした学習データをドラッグ&ドロップします。
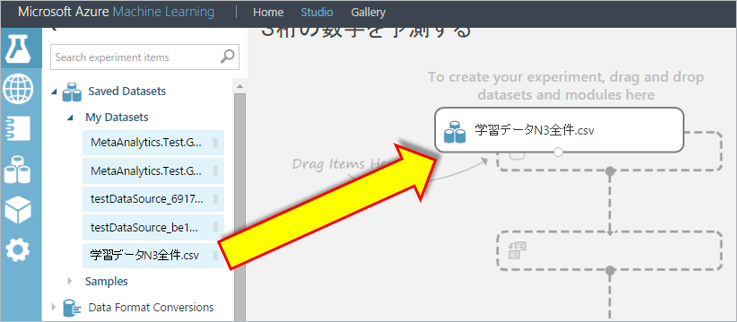

各モジュールの配置
同様に左側のアイコンをたどり、目的のモジュールをドラッグ&ドロップします。
・アルゴリズム
今回は線形回帰を指定。他のアルゴリズムや自信で開発したものなどを指定できます。
“Machine Learning > Initialize Model > Regression > Liner Regression”
・モデル
アルゴリズムと学習データによって作られる予測モデルとなります。
“Machine Learning > Train > Train Model”
・データ選択モジュール
登録したデータから予測に使用するカラムを指定します。
“Data Trasformation > Manipulation > Project Columns”
・データ分割モジュール
登録したデータを学習用、評価用に分割します。
“Data Trasformation > Sample and split > Split Data”
・スコアモジュール
予測した値の確認、評価を行います。
“Machine Learning > Score > Score Model”
全てのモジュールを配置すると下図のようになります。
(赤い警告マークが表示されているモジュールがありますが、この後の設定により解消されます)
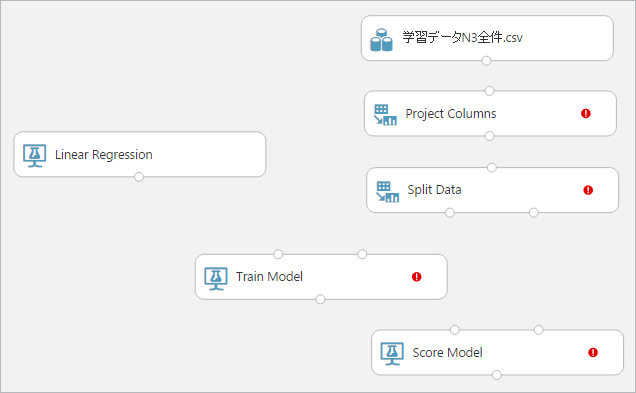

各モジュールを結線
・”学習データ”、”Project Colums”を接続
接続元(図では丸イチとなっている部分)を右クリックし、表示されたメニューから”Visualize”を選択すると学習データの中身を参照する事ができます。
このように各モジュールにて”Visualize”が表示される場合、そのモジュールの特性にあった表示が行われます。
合わせてモジュールのプロパティが右側に表示されますので、必要に応じて設定を行います。
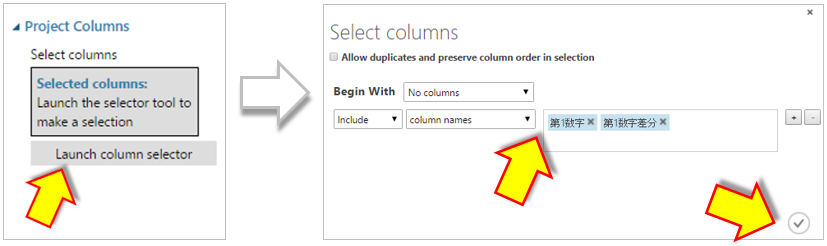
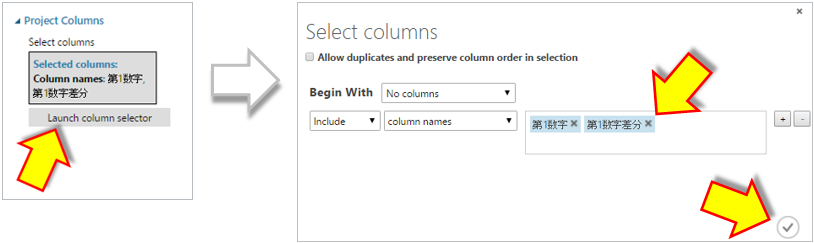
次に”Project Columns”のプロパティを表示し、使用するデータ項目を指定します。
この予測モデルは百の位を予測しますので、”第1数字”と”第1数字差分”の2項目を使用します。
・”Project Colum”、”Split Data”を接続
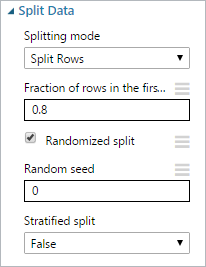
Split Dataのプロパティを表示し、データを学習用、評価用に振り分ける割合を指定します。
下図は80%を学習データとして指定しました。(Fraction of rows in the first output dataset)
・”Lineaar Regression”、”Split Data “を”Train Model”に接続
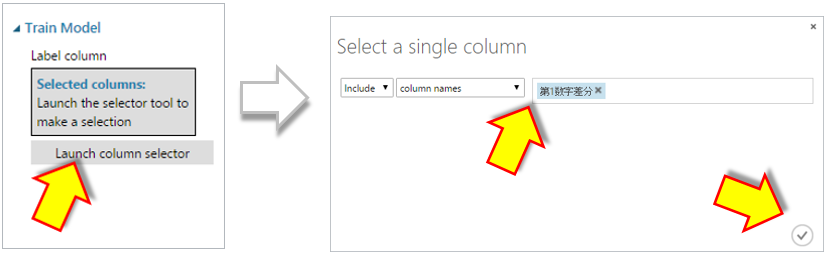
“Train Model”のプロパティを表示し予測する項目を指定します。ここでは差分を予測したいため”第1数字差分”を指定します。
・”Train Model”、”Split Data “を”Score Model”に接続
“Train Model”のプロパティを表示し予測する項目を指定します。ここでは差分を予測したいため”第1数字差分”を指定します。
これで接続とプロパティの設定は完了です。

モデルの実行
画面下にある”RUN”をクリックし学習と予測を行います。
“RUN”が完了すると各モジュールに緑のチェックマークが付きます。

最後に”Score Model”クリックしVisualizeにて予測結果を確認します。
3カラム目の”Scored Labels”が予測された差分となります。
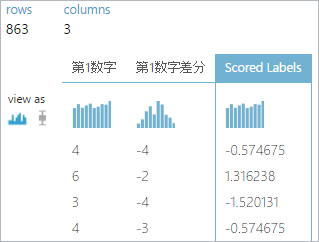
うっ、かなり予想が外れてますが・・・
気にせず進めましょう。

Webサービスとして準備

“Web Service input”、”Web Service output”を配置
左側のアイコンの”Web Service”をクリックし表示さる”Input”、”Output”をドラッグ&ドロップします。
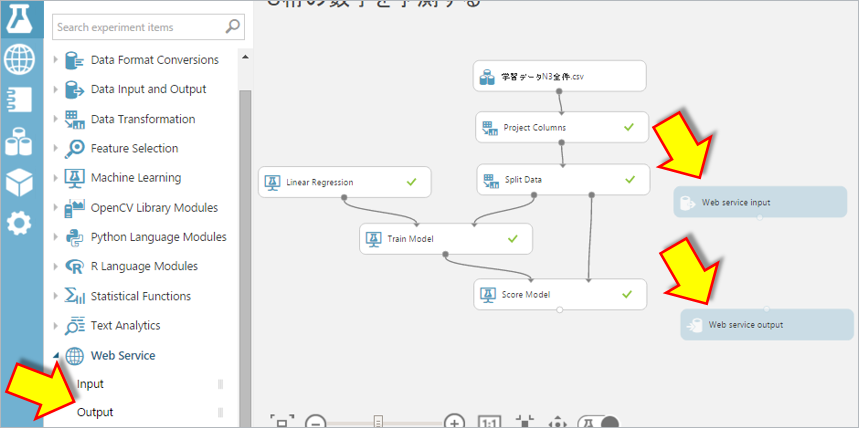

“Web Service input”を”Score Model”に、”Score Model”を”Web Service output”接続
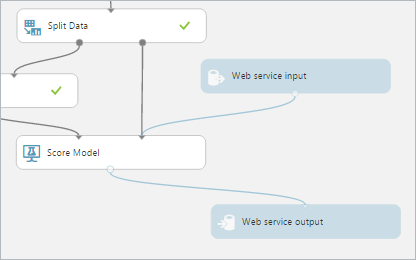
“RUN”をクリックし実行が完了したら”Train Model”を選択してから”Predictive Web Service[Recommended]”を実行します。
すると、配置したモジュールが勝手に動いて処理が完了します。
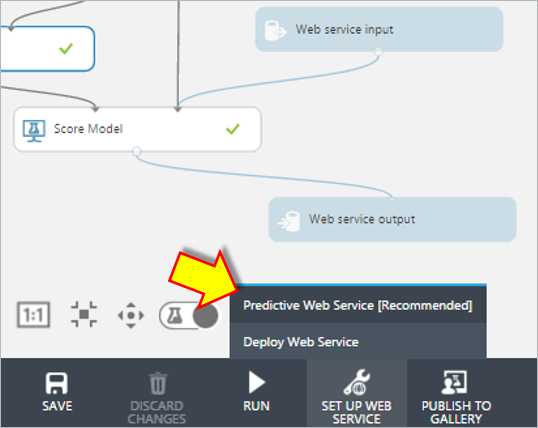

Webサービスパラメータの設定
“Web Service input”と”Score Model”を接続
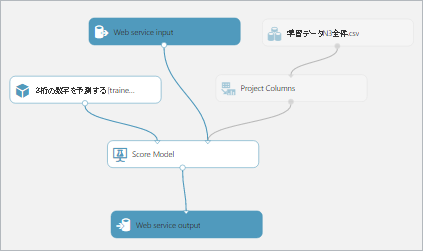
“Project Colum”のプロパティを表示し”第1数字差分”を削除する。

Webサービスの公開
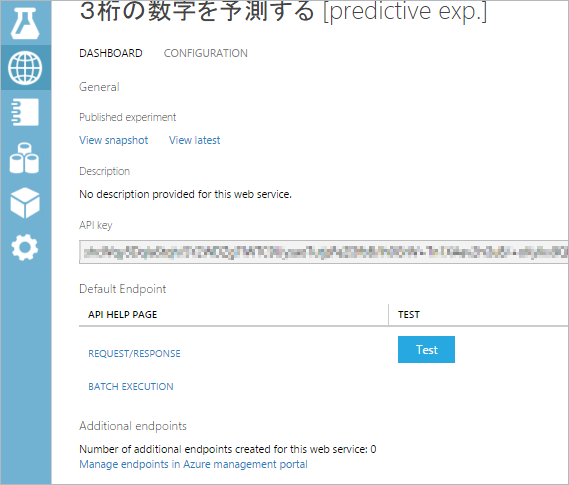
“RUN”を実行後、”DEPLOY WEB SERVICE”をクリックし開発したモデルを公開します。

公開が完了すると下記の画面に切り替わります。
(本画面は左の地球儀アイコンのクリックによって表示されるWebサービスのリストからも開けます)
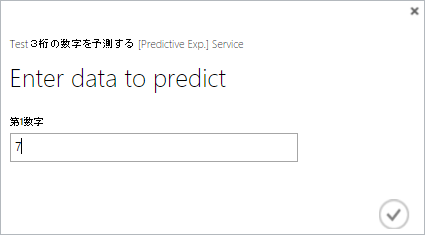
“Test”ボタンをクリックし、公開したWebサービスを呼出し、動作を確認してみます。
第1数字に最新当選番号の百の位を入力します。
本記事執筆時点(2015/1/14)最新の第4317回の当選番号は、”727″ですので、”7″を入力し第4318回の百の位の差分を予測します。
予測結果は”2.26″となりました。(下図参照)
という事は今回の”7″に”2.26″をプラスした”9.26″、つまり”9″という予測結果です。
ちなみに第4318回の百の位は”9″でしたの、この予測は的中です。でも他の桁がはずれた(T_T)
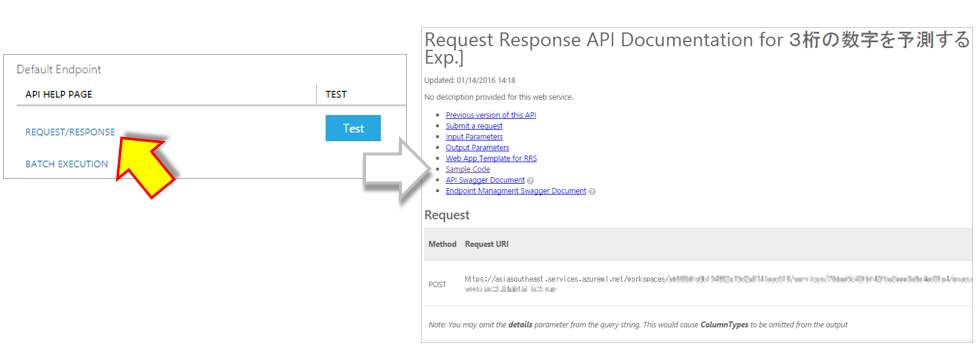
画面下に”DETAILS”をクリックしレスポンスを表示します。


インターフェースとサンプル
WebAPIへのインターフェース及び、各言語からの呼び出し方法に関するサンプルプログラムも生成されているため、その後のアプリ開発に役立てる事ができます。
という事で、チュートリアルはここまでです。
説明をはしおらず丁寧に記述したので、ずいぶんと長文になってしまいましたが、よかったら他の項目を説明変数とし違う予想を試してみるのも良いかと思います。
