


目次
- はじめに
- MarkItDown とDocling
- 環境構築
- プログラム例
- 変換してみた結果
- さいごに
1. はじめに
近年、PDFやWordなどの文書ファイルが、大規模言語モデル(LLM)の学習データやRAG(検索拡張生成)の外部情報として利用されることが増えています。このデータを生成AIに読み取らせる時、人間が理解しやすい形式に整えることが重要とされています。なぜなら文書の形式を整えることで、生成AIの情報読み取り能力が向上し、回答の精度が高くなるからです。
しかし、データを箇条書きの部分を1列で書いたり、表の中のデータをただ羅列したりすると、AIにとっては理解しにくい情報となり、期待する成果が得られないこともあります。
そこで、文書をより読み取りやすくし、AIが理解しやすい形式に変換する方法として、Markdown形式への変換が挙げられます。Markdown形式では、見出しや表、箇条書きなどが視覚的に整理され、情報の構造が明確になります。
今回は文書をMarkdown形式に変換する2つの技術、MarkItDownとDoclingの比較調査を行いました。これらの技術を使うことで、文書がどの程度きれいに整形され、生成AIにとって読み取りやすい状態になるのか、その精度を明らかにしたいと思います。
2. MarkItDown とDocling
MarkItDown は Microsoft が開発した Python ライブラリです。
2025年2月現在、以下のファイル形式を Markdown に変換します。
- PowerPoint
- Word
- Excel
- 画像 (画像説明など)
- 音声 (文字起こしなど)
- HTML
- CSV
- JSON
- XML
- ZIP ファイル
一方Docling は IBM が開発した Python パッケージです。
2025年2月現在、以下のファイル形式を Markdown, HTML, JSON, Text, Doctagsのいずれかの指定した形式に変換します。
- DOCX
- XLSX
- PPTX
- HTML
- PNG, JPEGなどの画像ファイル
etc…
3. 環境構築
3-1. MarkItDown
Python ライブラリであるため、使い方は簡単です。
まずコマンド「pip install markitdown」でパッケージをインストールします。
あとは、「from markitdown import MarkItDown」で機能をインポートして下記プログラム例のように呼び出すだけです。
以下のプログラムの 4 行目で変換するファイルのパスを指定するだけで MarkItDown に変換したテキストを表示させることができます。
|
from markitdown import MarkItDown
md = MarkItDown() result = md.convert("変換するファイルのパス") print(result.text_content) |
3-2. Docling
こちらも使い方は簡単です。
MarkItDownと同様にコマンド「pip install docling」でパッケージをインストールします。
文書をMarkdownに変換するには、まず「from docling.document_converter import DocumentConverter」でインポートを行います。
そして下記プログラム例のように変換するファイルのパスに対してconvertを呼び出します。
|
from docling.document_converter import DocumentConverter
source = “変換するファイルのパス” converter = DocumentConverter() result = converter.convert(source) print(result.document.export_to_markdown()) |
4. プログラム例
今回自分が作成したPythonのプログラムをサンプルとして表示します。
4-1 MarkItDown
指定したフォルダ内の全ての pdf ファイルを MarkItDown に変換します。
MarkItDown に変換したテキストは md ファイルとして出力されます。
|
from markitdown import MarkItDown # MarkItDownモジュールからMarkItDownクラスをインポート import os # OS関連の操作を行うためのモジュールをインポート
input_folder = "100_PDF" # 入力ファイルが格納されているフォルダの名前を指定 input_files = [os.path.join(input_folder, f) for f in os.listdir(input_folder) if f.endswith(".pdf")] # 指定されたフォルダ内の.pdfファイルのパスをリストとして取得
for input_file in input_files: # 各入力ファイルに対してループを実行 markitdown = MarkItDown() result = markitdown.convert(input_file) # 入力ファイルをMarkdown形式に変換
base_name = os.path.splitext(input_file)[0] # 入力ファイルの拡張子を除いたベース名を取得 text_file = f"{base_name}.md" # 出力するMarkdownファイルの名前を作成 with open(text_file, "w", encoding="utf-8") as f: # MarkdownファイルをUTF-8エンコーディングで書き込みモードで開く f.write(result.text_content) # 変換結果のテキストコンテンツを書き込む |
4-2 Docling
ファイルの内容をMarkdownに変換しmdファイルに出力するdocling_analysis.pyを作成しました。
|
from docling.document_converter import DocumentConverter import os
def convert_markdown(file_full_path): """ファイルをマークダウン文書に変換して中身を返す関数
Args: file_full_path (str): 変換するファイルのフルパス
Returns: str: マークダウン記法に変換されたファイルの内容 """
converter = DocumentConverter() # 内容を解析 result = converter.convert(file_full_path) # Markdownに変換 return result.document.export_to_markdown()
def convert_markdown_mdfile(file_full_path, filename = "document"): """ファイルをマークダウン文書に変換して中身をmdファイルにして返す関数
Args: file_full_path (str): 変換するファイルのフルパス filename (str, optional): ファイルのファイル名。 Defaults to " document". """
# マークダウン記法のファイルの内容を取得 markdown_output = convert_markdown(file_full_path)
# 呼び出し元のディレクトリを取得 caller_directory = os.getcwd()
# 出力するファイル名を作成 markdown_file_name = "output_" + filename + ".md"
# 出力ファイルのフルパスを作成 file_path = os.path.join(caller_directory, markdown_file_name)
# Markdownをファイルに保存 with open(file_path, "w", encoding="utf-8") as md_file: md_file.write(markdown_output) |
これを次のプログラムのように呼び出しています。このプログラムは第1引数のディレクトリ内の全てのpptxファイルの中身をそれぞれMarkdownに変換し、mdファイルに保存する処理を行います。
|
import docling_analysis import os import sys import glob
# 第1引数のディレクトリ内のpptxファイルを全て取得 pptx_files = glob.glob(os.path.join(sys.argv[1], '*.pptx'))
# pptxファイルのリストに対して for pptx_file in pptx_files: pptx_file_full_path = os.path.abspath(pptx_file) # pptxファイルの絶対パスを取得 pptx_file_name = os.path.basename(pptx_file) # pptxファイルのファイル名を取得 # pptxファイルをマークダウン形式に変換して保存 # pptx_file_name.replace('.pptx', ""): pptxファイルの拡張子を除いたファイル名 docling_analysis.convert_markdown_mdfile(pptx_file_full_path, pptx_file_name.replace('.pptx', "")) |
5. 変換してみた結果
今回はPDF, PowerPoint, Excel, Wordについて変換の精度を調べてみました!
変換後で気になったところをピックアップして結果をお伝えします。
5-1. PDF
画像は変換対象のPDFの一部です。

|
MarkItDownでは、このページは次のように変換されました
|
生成 AI 活用の取り組みと今後の方針について
株式会社クレスコ(本社:東京都港区、代表取締役 社長執行役員:冨永 宏、以下当社)は、2022 年の生 成 AI 登場後直ちに、その利活用によるサービス品質と生産性向上に向け取り組みを開始しました。開始 後 2 年の取り組み事例や進捗状況、今後の方針につき、お知らせいたします。
■取り組みの経緯(生成 AI ビジネス変革研究室設立)
クレスコは、ChatGPT が注目を浴びた 2022 年から生成 AI 活用に向けた取り組みを開始し、2023 年 5 月には社員向けに生成 AI チャットサービス「CrePT」を構築、社内で運用を開始しました。開発業務に おけるコーディングやテスト支援などの他、管理業務でも各種照会への自動回答、提案書の作成や市場 調査等で使用開始、使用率は着実に上昇しております。
2024 年 7 月には、社長直轄の部門横断組織である『生成 AI ビジネス変革研究室』を設立し、取り組み を強化しています。この研究室は、複数の部門や社内公募メンバーが関わり、中期経営計画 2026 で掲げ るクレスコの成長戦略「技術・デジタルソリューションの拡張」と「デジタル変革実現」を推進する 2 つのチームで構成されています。また、当社と関わりの深い北海道大学の川村教授にアドバイザーとし てご支援をいただいています。
同研究室では、2024 年度に「顧客への新たな価値創出」「生成 AI を利用した社内デジタル変革」「生成
AI 時代に向けた人財育成」の三つの観点で取り組みを進めて参りました。 |
Doclingでは、同ページは次のように変換されました。
|
## 生成 AI 活用の取り組みと今後の方針について
株式会社クレスコ ( 本社:東京都港区、代表取締役 社長執行役員:冨永 宏、以下当社 ) は、 2022 年の生 成 AI 登場後直ちに、その利活用によるサ-ビス品質と生産性向上に向け取り組みを開始しました。開始 後 2 年の取り組み事例や進捗状況、今後の方針につき、お知らせいたします。
## ■取り組みの経緯(生成 AI ビジネス変革研究室設立)
クレスコは、 ChatGPT が注目を浴びた 2022 年から生成 AI 活用に向けた取り組みを開始し、 2023 年 5 月には社員向けに生成 AI チャットサ-ビス「 CrePT 」を構築、社内で運用を開始しました。開発業務に おけるコ-ディングやテスト支援などの他、管理業務でも各種照会への自動回答、提案書の作成や市場 調査等で使用開始、使用率は着実に上昇しております。
2024 年 7 月には、社長直轄の部門横断組織である『生成 AI ビジネス変革研究室』を設立し、取り組み を強化しています。この研究室は、複数の部門や社内公募メンバ-が関わり、中期経営計画 2026 で掲げ るクレスコの成長戦略「技術·デジタルソリュ-ションの拡張」と「デジタル変革実現」を推進する 2 つのチ-ムで構成されています。また、当社と関わりの深い北海道大学の川村教授にアドバイザ-とし てご支援をいただいています。
同研究室では、 2024 年度に「顧客への新たな価値創出」 「生成 AI を利用した社内デジタル変革」 「生成 AI 時代に向けた人財育成」の三つの観点で取り組みを進めて参りました。 |
MarkItDownの結果を確認したところ、文章中のテキストは正しく抽出されています。
しかし、本文中に改行がある箇所については、変換後のテキストで1文の途中であってもそのまま改行が反映されていたり、空白の行が1行挟まれていたりと、形式が統一されていません。
サンプルにはありませんが、箇条書きで書かれた要素の順番が変換前と異なる問題もあります。
Doclingは、生成AIを活用してPDFからテキストを抽出する仕組みになっています。
見出しの部分は変換後Markdownの見出し形式にしていますね。
また画像にはありませんが、MarkItDownとは違ってPDF内の表や箇条書きの部分は変換後Markdown形式の表、箇条書きになるという利点があります。ただし、複雑な表だと要素が1マスずれていたり、箇条書き部分の近くに書かれた箇条書きでない文もまとめて箇条書きの要素として変換されたりなど、整形の精度はやや低めです。
また、テキストについて正しく抽出されていない点も多く見受けられます。
例えば、漢数字の一や長音記号(―)は全てマイナス(-)として抽出されています。
他にも本文中で改行がある箇所が変換後には半角スペースになるといった問題などもあり、このような状態で生成AIに読み込ませると正しい文の認識がしづらくなる可能性があります。
文章の正確さならMarkItDown, 整形の綺麗さならDoclingの方が優れていると思います。
どちらを使うかは文書の内容や用途によって決まりそうです。
5-2 PowerPoint
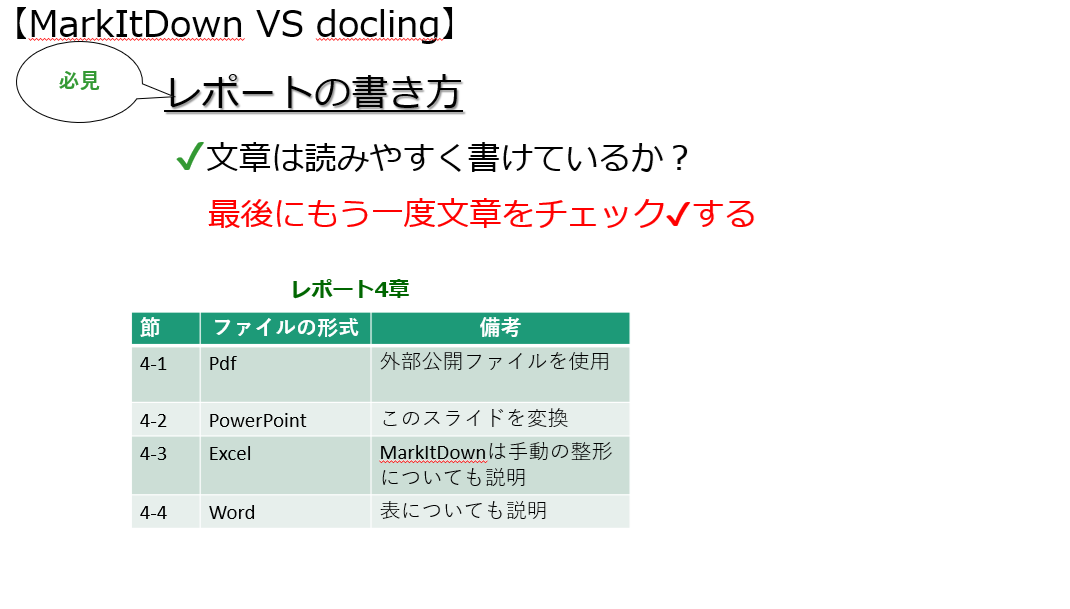
画像は変換対象のスライドの一部です。
このスライドをMarkItDownとDoclingでMarkdownに変換してみました。
|
MarkItDown
|
# ■概要 レポートの書き方 【MarkItDown VS docling】 ✔文章は読みやすく書けているか? 最後にもう一度文章をチェック✔する
必見
| 節 | ファイルの形式 | 備考 | | --- | --- | --- | | 4-1 | Pdf | 外部公開ファイルを使用 | | 4-2 | PowerPoint | このスライドを変換 | | 4-3 | Excel | MarkItDownは手動の整形についても説明 | | 4-4 | Word | 表についても説明 | レポート4章 |
Docling
|
# ■概要
レポートの書き方
【MarkItDown VS Docling】
✔文章は読みやすく書けているか?
最後にもう一度文章をチェック✔する
必見
| 節 | ファイルの形式 | 備考 | |------|------------------|--------------------------------------| | 4-1 | Pdf | 外部公開ファイルを使用 | | 4-2 | PowerPoint | このスライドを変換 | | 4-3 | Excel | MarkItDownは手動の整形についても説明 | | 4-4 | Word | 表についても説明 |
レポート4章 |
両者ともテキストだけでなく表まで正しく抽出できているようですね。
しかし、変換前は「レポート4章」よりも表の方が読む順番で先に配置されているにも関わらず、変換後はMarkItDownとDoclingともにこの順序が逆転しています。このように変換前の要素の順序が崩れている箇所が多々見られました。
MarkItDownでは、pptxファイル内の表をMarkdownの表形式に変換できる点が好印象です。
その他気になった点は、pdfと同じく本文中で改行がある箇所が、変換後ではそのまま改行が反映されていたり、空白の行が1行挟まれていたりと、形式が統一されていないことです。
Doclingでは本文中で改行がある箇所が、変換後は空白の行を1行挟む形式になりましたが、読み取りやすさの点ではMarkItDownとさほど変わりはないと思います。
ただDoclingは1文の途中で改行している箇所も変換後に空白の行を1行挟む形式になるので、こちらの方が少々見づらいかもしれません。
5-3 Excel
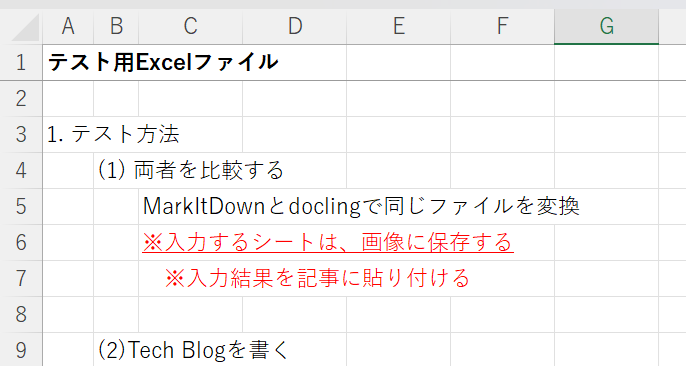
画像は変換対象のシートの一部です。
変換を行った後の結果を比較してみましょう。
|
MarkItDown
|
## テスト用シート | テスト用Excelファイル | Unnamed: 1 | Unnamed: 2 | | --- | --- | --- | | NaN | NaN | NaN | | 1. テスト方法 | NaN | NaN | | NaN | (1) 両者を比較する | NaN | | NaN | NaN | MarkItDownとdoclingで同じファイルを変換 | | NaN | NaN | ※入力するシートは、画像に保存する | | NaN | NaN | ※入力結果を記事に貼り付ける | | NaN | NaN | NaN | | NaN | (2)Tech Blogを書く | NaN | |
表形式で出力できますが、テキストがないセルは変換後”NaN”と書かれており邪魔です。
“NaN”だけ消しても縦棒が残るばかりで見づらいので、置換などを使って縦棒と” NaN ”の両方を消してしまいましょう。
|
## テスト用シート テスト用Excelファイル Unnamed: 1 Unnamed: 2 --- --- ---
1. テスト方法 (1) 両者を比較する MarkItDownとdoclingで同じファイルを変換 ※入力するシートは、画像に保存する ※入力結果を記事に貼り付ける
(2)Tech Blogを書く |
余計なテキストがだいぶ減りましたね!
しかしこの方法では、1つのシート中に文章と表が混在する場合、変換して置換した後、表がある箇所が表形式で表示されないので見づらくなります。
表がある箇所だけ表形式で出力するのが最も望ましい形式ですが、変換後のテキストから表と表でない部分の判別をプログラムにさせるとなると難しそうです。
次に、Doclingで変換した結果を示します。
|
| MarkItDownとdoclingで同じファイルを変換 | |-------------------------------------------| | ※入力するシートは、画像に保存する | | ※入力結果を記事に貼り付ける | |
画像で示した変換対象ファイルの5、6、7行目を除き、他の行が変換後に消えてしまいました。
同じ列からテキストが存在するセルが並ぶ行が複数あると、それを表として抽出し、他の部分は変換しないようです。
このように情報が抜け落ちている状態では、生成AIに読み込ませるための形式にふさわしいとは言えません。
したがって、余計な文字列を消す手間はかかるもののMarkItDownの方が変換に優れているといえます。
5-4 Word
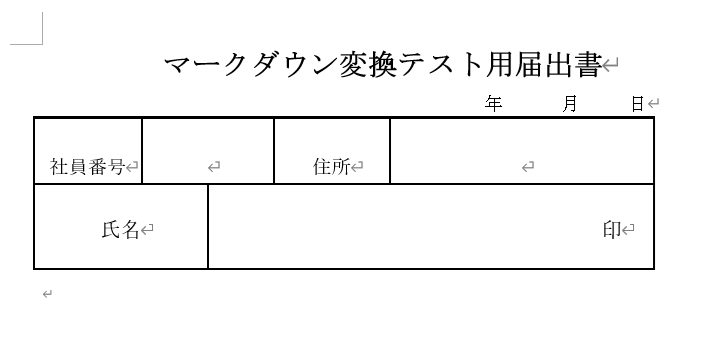
画像は変換対象のWordファイルの一部です。
変換を行った後の結果を比較してみましょう。

|
MarkItDown
|
**目次**
1. はじめに 2. MarkItDown とDocling 3. プログラム例 4. 変換してみた結果
5. さいごに
**1.はじめに**
近年、PDFやWordなどの文書ファイルが、大規模言語モデル(LLM)の学習データやRAG(検索拡張生成)の外部情報として利用されることが増えています。この読み込ませる文書の内容のデータを人間が理解しやすい形式に整えることが重要です。文書の形式を整えることで、生成AIの情報読み取り能力が向上し、回答の精度が高くなります。
しかし、データをそのまま箇条書きにしたり、表の中の情報を羅列したりすると、AIにとっては理解しにくい情報となり、期待する成果が得られないこともあります。そこで、文書をより読み取りやすくし、AIが理解しやすい形式に変換する方法として、MarkDown形式への変換が挙げられます。Markdown形式では、見出しや表、箇条書きなどが視覚的に整理され、情報の構造が明確になります。
今回は文書をMarkdown形式に変換する2つの技術、MarkItDownとDoclingの比較調査を行いました。これらの技術を使うことで、文書がどの程度きれいに整形され、生成AIにとって読み取りやすい状態になるのか、その精度を明らかにしたいと思います。 |
Dociling
|
目次
- はじめに - MarkItDown とDocling - プログラム例 - 変換してみた結果
5. さいごに
1.はじめに
近年、PDFやWordなどの文書ファイルが、大規模言語モデル(LLM)の学習データやRAG(検索拡張生成)の外部情報として利用されることが増えています。この読み込ませる文書の内容のデータを人間が理解しやすい形式に整えることが重要です。文書の形式を整えることで、生成AIの情報読み取り能力が向上し、回答の精度が高くなります。
しかし、データをそのまま箇条書きにしたり、表の中の情報を羅列したりすると、AIにとっては理解しにくい情報となり、期待する成果が得られないこともあります。そこで、文書をより読み取りやすくし、AIが理解しやすい形式に変換する方法として、MarkDown形式への変換が挙げられます。Markdown形式では、見出しや表、箇条書きなどが視覚的に整理され、情報の構造が明確になります。
今回は文書をMarkdown形式に変換する2つの技術、MarkItDownとDoclingの比較調査を行いました。これらの技術を使うことで、文書がどの程度きれいに整形され、生成AIにとって読み取りやすい状態になるのか、その精度を明らかにしたいと思います。 |
どちらも変換前のテキストをそのままMarkdownに抽出できています。
また、箇条書き部分の最後の要素が変換後に箇条書きの要素と認識されませんでした。これは元ファイルでも箇条書きの要素だと認識されていないからだと思います。
ここでのMarkItDownとDoclingの主な違いは、MarkItDownは見出し部分をMarkdownの見出しの形式に変換していることでした。
次に、画像のような表も変換してみます。
|
MarkItDown

Docling

両者ともMarkdown形式の表に変換できます。
しかしDoclingの結果では、変換前の表でセルの結合がある場合、変換後は結合したセル数の分だけ中のテキストを出力しているようです。
生成AIに読み込ませることが目的ですから、無駄なテキストは存在はない方がいいですね。
というわけで、MarkItDownの方がDoclingよりも若干ですが上手く整形してくれそうです。
6. さいごに
Markdownへの変換に関して、4つのファイル形式を対象にMarkItDownとDoclingを比較しました。
その結果、PDF以外はMarkItDownを使用する方が無難であると感じました。
PDFは内容や用途によってMarkItDownを使った方がいい場面、doclingを使った方がいい場面があるのかな?と思います。
両者もすぐに導入と開発ができるはずなので、皆さまもぜひ一度試してみてはいかがでしょうか?
