


はじめに
こんにちは、ENKです。
今回のテーマは「楽にかつ安全にシステムを運用する」方法について、AWSクラウドのシステム監視における障害監視を取り上げさせていただきます。
障害監視とは、情報システムの状態を監視し、異常が検出されたときに運用・保守者に警告し、適切な措置を講じるためのトリガーとなります。これにより、サービスの安定的かつ持続的な提供を保証する運用手法となります。
障害監視では、システムがどういう状態を異常(エラー)として定義するかが重要になります。この定義には専門的な知識が必要となるため、本テーマではその定義に必要な視点を簡単にご紹介し、AWSのサービスでの対応方法について解説します。
目次
- 本記事の対象範囲
- システム監視項目定義の考え方
- AWSにおけるシステム監視方法
- 監視によって検知された事象の通知
- まとめ
1.本記事の対象範囲
本記事では、AWS(Amazon Web Services)が提供するサービスを活用し、私自身の経験に基づき、頻繁に採用される構成例の障害監視方式を紹介します。ここで取り上げる構成例は現状広く用いられると考えているので、多くの読者の皆様の参考になると思います。
なお、本記事の範囲は最低限必要とされる、システム停止等の異常を検知して通知するための仕組みまでとしますので、その点をご理解いただければと思います。
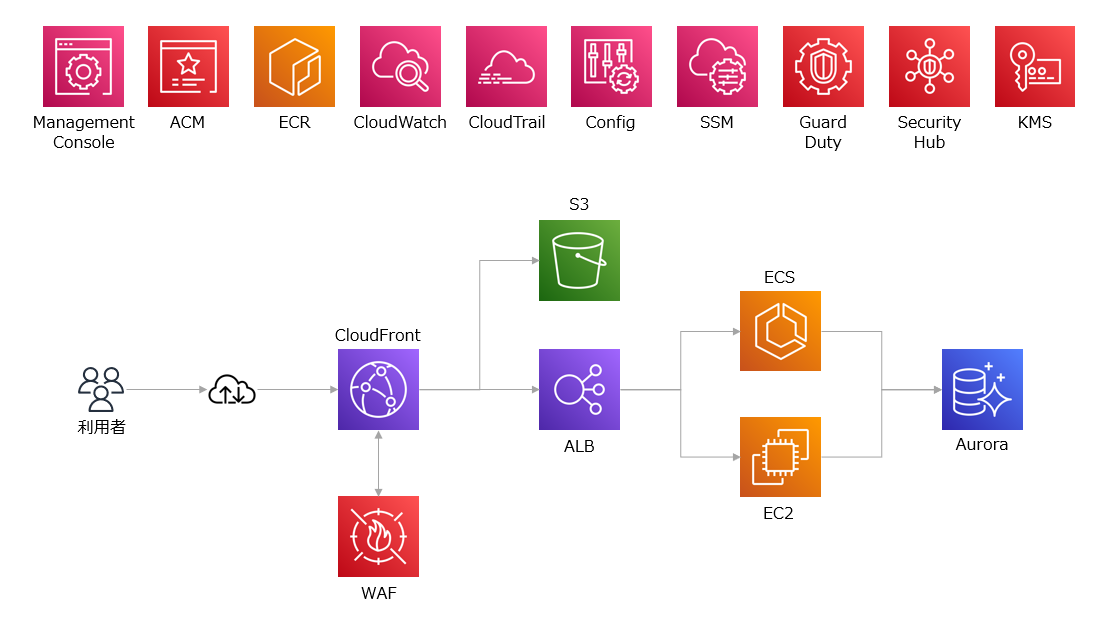
2.障害監視項目定義の考え方
システムに対する障害監視は、まさにシステムの定常的な健康診断ともいえます。不健康な箇所を特定できるように監視対象を定義することが、障害監視項目設計の基本的な考え方となります。例えば、通常時のCPU利用率が30%程度のシステムで、突然5分以上にわたって90%以上が発生した場合、あるいはアプリケーションログに「ERROR」などの文字列が記録された状態を異常として定義し、これらが障害監視項目となります。
また、障害監視項目を設定する際には、システム全体の構成を俯瞰し、異常が発生する可能性がある箇所を見落とさないように慎重な調査・検討を行います。例えば、先述の構成例から考えれば、下記の内容が最低限必要な監視項目となる思います。これらは一種の大分類と位置づけられ、そこから対応した各サービス単位で、サービス・OS・プログラムプロダクト(PP)毎に具体的な監視定義を展開していくことが、障害監視項目実装に向けた進め方になります。
|
サービス |
監視項目 |
目的 |
|---|
|
CloudFront |
URL監視 |
サイトのダウン有無などの状態を監視 |
|
WAF |
セキュリティ監視 |
攻撃予兆や攻撃されていないかを監視 |
|
ALB |
HTTPステータス監視 |
サービス提供に支障があるHTTP5xx系エラーを監視 |
|
ECS |
ログ監視 |
OS・PPにエラーが無いかを監視 |
|
死活監視 |
コンテナ起動数が適切かを監視 |
|
リソース監視 |
コンテナの負荷が高騰し、サービス提供に支障が無いかを監視 |
|
EC2 |
ログ監視 |
OS・PPにエラーが無いかを監視 |
|
死活監視 |
サーバーが起動しているかを監視 |
|
プロセス監視 |
アプリケーションのプロセスが正常に起動しているかを監視 |
|
リソース監視 |
サーバーの負荷の高騰、ディスクリソース等が不足しサービス提供に支障が無いかを監視 |
|
Aurora |
ログ監視 |
DBログにエラーが無いかを監視 |
|
状態監視 |
サービスの異常を示すイベントを監視 |
|
リソース監視 |
サービスの負荷状況やディスクリソース等が不足しサービス提供に支障が無いかを監視 |
|
AWS |
状態監視 |
リージョンやゾーン障害など、サービスの異常を示すイベントを監視 |
3.AWSにおける障害監視の実装方式
従来のシステム監視では、サーバーベンダー製品を活用して専用の監視サーバーを構築し、クライアント・サーバー方式のような監視システムを用意していました。しかし、最近ではAWSのサービスだけでも、ほとんどの障害監視が実装可能となっています。基本的なサービス選定の方針は、AWSが提供している範囲で可能な限り対応し、それでも足りない部分については、サードパーティ製品(SaaSなど)を導入する流れになります。
それでは、CloudWatchで可能な監視内容についておさらいし、CloudWatchを使った実装方法について解説したいと思います。
おさらい
Amazon CloudWatchは、AWSのモニタリングサービスで、AWSリソースとアプリケーションを実行して問題を検出して解決するために、運用健全性、パフォーマンス、アプリケーションとその他のリソースの形式でデータを収集して追跡します。以下のようなIaaS(Infrastructure as a Service)とPaaS(Platform as a Service)サービスに対応しています。
1. Amazon EC2 (IaaS): CloudWatchを使用して、CPU使用率、データ転送、ディスクI/O、インスタンスの状態などを監視する事が可能です。異常を検知した場合、それに対するアクションを自動的に起動します。
2. Amazon S3 (IaaS): CloudWatchを用いて、S3バケットのストレージ使用量を監視します。また、リクエストエラー率や、エラーコード数などのメトリックスを提供します。
3. Amazon RDS (PaaS): CloudWatchは、Amazon RDSのデータベースインスタンスを監視し、CPU使用率、ディスク空間、データベース接続数、読み取り・書き込みI/O操作などの情報を提供します。エラーが発生した場合、CloudWatchアラームを使用して通知を受けることができます。
4. AWS Lambda (PaaS): CloudWatchはLambda関数の実行に関する詳細な情報を提供します。関数の呼び出し回数、実行時間、エラー発生数などの詳細なデータを取得できます。
以上のように、CloudWatchはAWSリソースのモニタリングに利用でき、問題が発生した際にアラートを送信など、特定のアクションをトリガーすることが可能です。
次に構成例で挙げたサービスでの対応を見ていきます。合わせてCloudWatchのサービスで採用する機能も見ていきたいと思います。
下表のように整理してみると、CloudWatchで障害監視が実装することが可能であることが分かります。障害監視設定は自体は、AWSの技術者がよく利用する機能をそのまま使えるのは嬉しいですね。
|
4.監視によって検知された事象の通知
CloudWatchを最大限に活用することで、容易にシステムの状態変化に対してアラームを発報することが可能となります。このアラームはAmazon SNS(Simple Notification Service)とシームレスに連携できることがその理由になります。システム監視運用での通知の大半はメール通知となるでしょうから、その親和性が非常に高くなると言えます。
5.まとめ
テーマとした「楽にかつ安全にシステムを運用する」について、主要なポイントを抑えて説明いたしました。AWSクラウドを利用すれば、提供されているサービスを活用するだけで、システム監視(特に障害監視)が大幅に簡易化され、作業負担が大きく軽減されることが可能です。システム監視では、情報システムの状態に応じて適切なメンテナンスを日々継続する必要がありますが、AWSのサービスを使えばその全てに対応できます。これは、AWSの技術者から見れば非常に喜ばしい事実と言えるのではないでしょうか。
