


こんにちは。
Creageビジネス事業部 第二部のAo です。
前回の記事からだいぶ間が空いてしまいました…
お仕事ではNutanixからしばらく離れ、IaC関連の技術を扱うことが多い今日この頃です。
原点に立ち返り、Nutanixの記事を書いていこうと思います。
今回は、Nutanixの耐障害性について説明します。
これまでの記事もぜひご覧ください!
HCIことはじめ
Nutanixの基礎 Part1~製品の特長とCVMの概要編~
Nutanixの基礎 Part2~DSFとデータローカリティ・階層化に迫る~
目次
- データの二面コピー・三面コピー
- Replication Factor
- 障害パターン別に見るリビルド動作
- まとめ
1. データの二面コピー・三面コピー
Nutanixに限らず、多くのHCI製品ではデータを二重ないし三重に保持し、データの可用性を担保します。
また、実データからパリティを生成し、それぞれを別ノード上のディスクに配置し、可用性を担保する仕組みも存在します。(この仕組みの詳細は本記事で紹介しません)
データの二面コピーは下図のようなイメージです。
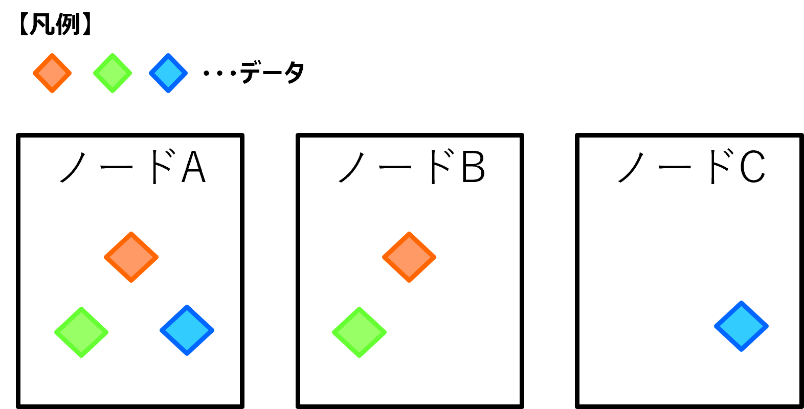
- 拡大
- 図1:二面コピーのイメージ
非常に単純な例ですが、ノードA上のディスクに赤・青・緑のデータがある場合、ノードA以外のディスク上(今回はノードB,Cが該当)にデータのレプリカをコピーします。
このようにデータのレプリカを生成することで、オリジナルデータが配置されているノード自体やディスクに障害が発生した場合でもデータがロストしないようになっています。
三面コピーにする場合も考え方は一緒で、複数ノード・ディスクに分散してレプリカデータを配置する点がポイントです。
※Nutanixで三面コピーを利用する場合は5ノード以上必要となります
先述の通り、Nutanix以外でもこの二面コピーや三面コピーは最も基本的な可用性担保の仕組みなので、HCIを扱う上では必ず覚えておくべき考え方になります。
2.Replication Factor
NutanixにはReplication Factor(以降RFと記載)と呼ばれるデータの冗長数を示すパラメータが存在します。
このRFが2であれば1つのデータにつき1つのレプリカが生成されます。(オリジナル+レプリカ)
RFが3であれば1つのデータにつき2つのレプリカが生成されます。(オリジナル+レプリカ × 2)
1章に記載した通り、これらのデータは全て別のノード上のディスクに配置されます。
なお、RFはストレージコンテナ(データストア)単位で設定することが可能です。
従って、重要度の高いデータを格納しているストレージコンテナに対してはRF3を設定、重要度の低いデータを格納しているストレージコンテナに対してはRF2を設定することも可能です。
以下のスクリーンショットはNutanixの管理UIであるPrismの画面でストレージコンテナのRFの設定値を確認した画面です。
お試し利用できるNutanix Test Drive(※)の画面なのでRF1(冗長化無し)になっていますが、ストレージコンテナごとに設定されていることが確認できます。
(※)Nutanix Test DriveはPrismをお試し利用することができるNutanixのサービスです。最小構成の環境なのでRF1となります。
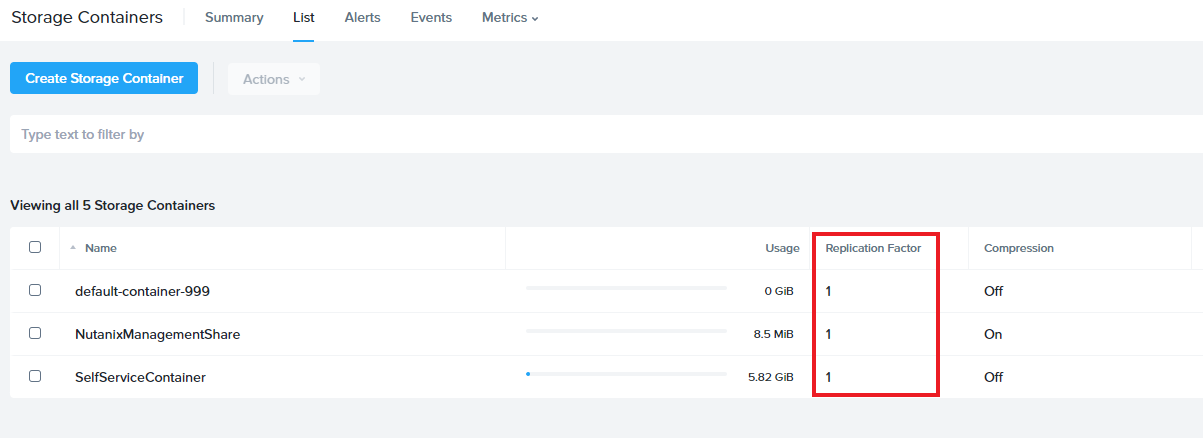
- 拡大
- 図2:Prism上でストレージコンテナの設定を表示
ストレージの容量の面でいえば、RF2は二重でデータを保持するため約1/2の実効容量、RF3は三重でデータを保持するため約1/3の実効容量になる点は注意が必要です。
例えば、1TBのストレージコンテナに対し、RF2を設定すると約500GBが実効容量になります。
容量を節約するためにErasure Codingや圧縮、重複排除も提供されているため、用途に応じてそれらの機能を組み合わせるとよいでしょう。
※キャパシティの最適化の仕組みについては本記事では触れません。
3.障害発生時の挙動
次は障害発生時の挙動(主にリビルド)について説明します。
障害発生時の挙動を理解しておくことは、運用中の障害対応でも非常に役立つため、ぜひ覚えていただくことをオススメします。
また、障害発生時の挙動はHCIの製品選定をする上でも非常に重要なポイントとなります。
ひとことで障害と言っても、様々な障害パターンが存在します。
今回はその中でも代表的な以下3つの障害に焦点をあてて説明させていただきます。
- ディスク障害
- ノード障害
- CVM障害
そもそもリビルドってなに?
各障害パターンの説明に入る前に、リビルドとは何かについて触れさせていただきます。
HCIにおけるリビルドとは、障害が発生した際に欠損したデータを再構築(復元)する動作のことを指します。
どのレイヤを担当しているかによってこのリビルドという言葉の捉え方が変わってくるので注意が必要ですね ;)
もう少し具体的に説明すると、Aというデータが書き込まれているディスクに障害が発生した際、他のディスク上のデータを利用し、Aを再構築することをリビルドと言います。
なお、リビルドが開始されるタイミングはHCI製品によって異なり、Nutanixの場合は即座にリビルドが開始されます。
VMwareのHCI製品であるvSANでは、ノード障害が発生してから60分間待機してリビルドを開始するといった動きになります。(手動でリビルドをキックすることで、即座にリビルドを開始させることも可能)
このように、リビルドの挙動もHCI製品ごとに異なるため、製品選定をする際には1つの比較ポイントとして注目することをおすすめします。
ディスク障害時の挙動
まずはディスク障害が発生した際の挙動について説明します。
ディスクは、応答がない場合やI/Oエラーが発生した場合などに障害として判定されます。
また、StargateというCVM上のプロセスが自ノード上のディスクに対して定期的にアクセス確認を行い、アクセスできない状態が一定期間続くと該当ディスクをオフラインと判断して利用可能なディスクから除外します。
このような状況に陥ると、CuratorとCassandraによるスキャンが行われ、リビルドすべきデータが洗い出されます。
※StargateやCurator、CassandraについてはNutanixの基礎 Part1~製品の特長とCVMの概要編~を参照
その後、CVMによってリビルドが行われます。
リビルドのイメージ図は以下になります。
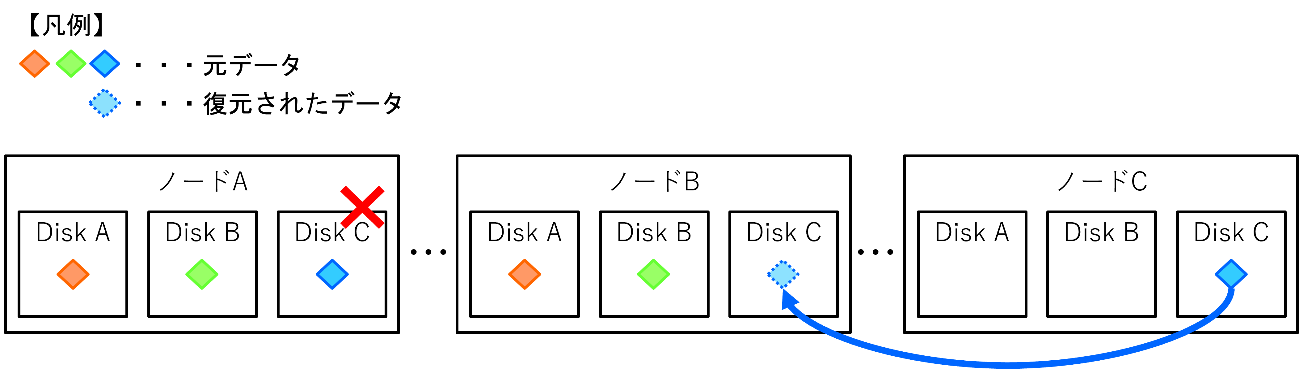
- 拡大
- 図3:ディスク障害時のリビルドイメージ
RF2を設定したクラスタのノードAのDisk Cに障害が発生したとします。
ノードAのDisk C上にあったデータ(青のひし形のオブジェクト)は障害によってアクセスできなくなるため、一時的に冗長性が無い状態になります。
そのため、RF2の状態に戻すため、すぐさまリビルドが動作し、ノードCのDisk C上の同一データがノードBのディスクにコピーされます。
※各ノードのディスク空き状況によっては、ノードBではなくノードAのディスクにリビルドされることもあります
もちろん、これらのリビルド動作は完全自動で行われるため、我々利用者が手を加える必要はありません。
また、Nutanixクラスタ上で稼働している仮想マシンに対する影響ですが、リビルド中も自ノード以外のノード上のデータにアクセスが可能なため、ディスクI/Oが止まることはありません。
ノード障害時の挙動
次はノード障害が発生した際の挙動を見ていきましょう。
ノード障害は、ハイパーバイザの障害や物理的な故障により発生することがあります。
ノード障害が発生した場合、該当ノード上の仮想マシンはAHVのVM HAやESXiのvSphere HAなどの機能により他ノード上で再起動されます。
再起動後は、そのノード上のCVMを利用して、ローカルのディスクに書き込みを行う動作となります。
リビルド動作に関しては、下図のイメージになります。
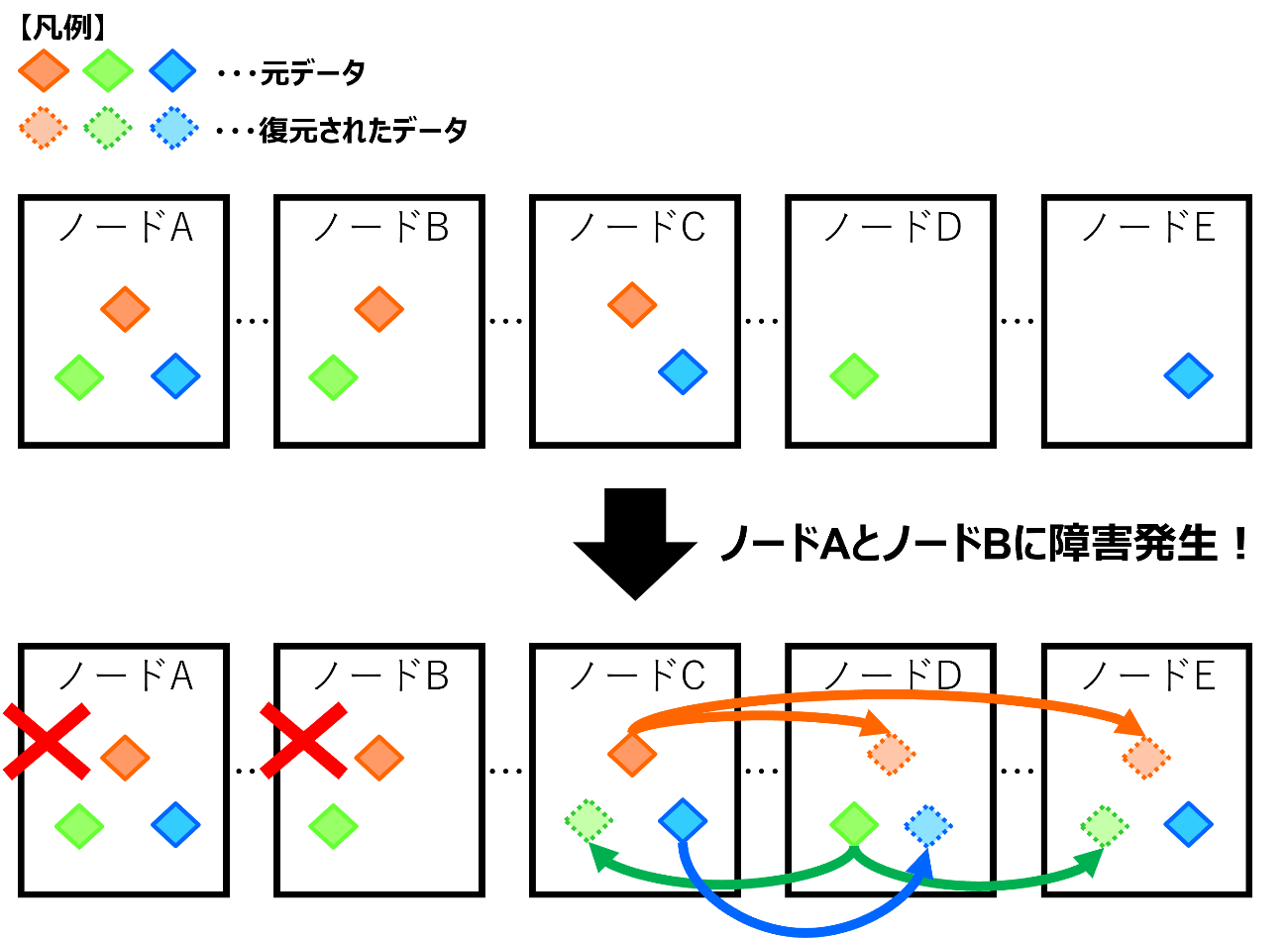
- 拡大
- 図4:ノード障害時のリビルドイメージ
RF3の状態(図4の上半分)でノードAとBに障害が発生したとします。
すると、ノードAとBのローカルディスクに存在しているデータにはアクセスできなくなるため、一時的に冗長性が崩れた状態となります。
そのため、残ったノードのローカルディスクに存在しているデータをもとにリビルドが行われます。
今回の例だと、赤のひし形のデータと緑のひし形のデータは冗長性が無い状態になっているため、RF3に戻すため正常なノード上のデータから2つコピーを生成します。
青のひし形のデータは2面コピーされた状態なので、残ったデータから1つコピーを生成します。
このように、ノード自体に障害が発生した場合も、RFで指定した冗長性となるように自動的にリビルドが行われます。
なお、リビルドが完了した後に障害発生ノードが復旧した場合、データが過剰に存在する状態(RF3だが4面コピーされた状態など)になりますが、Curatorによる定期スキャンの際に余分なデータが削除されるため心配無用です。
CVM障害時の挙動
最後にCVM自体に障害が発生した際の挙動を見ていきましょう。
あまり遭遇することはないと思いますが、OSクラッシュ等でCVMが一時的に利用できない状態になった場合、仮想マシンは他ノード上のCVMを利用してディスクにアクセスするようになります。
これはCVM Autopathingと呼ばれる機能で処理されます。
通常、仮想マシンのディスク I/Oは自ノード上のCVMを経由するため、CVMの内部IPアドレスである「192.168.5.2」にトラフィックが転送されますが、この転送先を内部IPアドレスから他のCVMの外部IPアドレスに変更することで、他ノード上のCVMを利用するようになります。
ハイパーバイザのルーティングテーブルが上記のように書き換えられるイメージです。
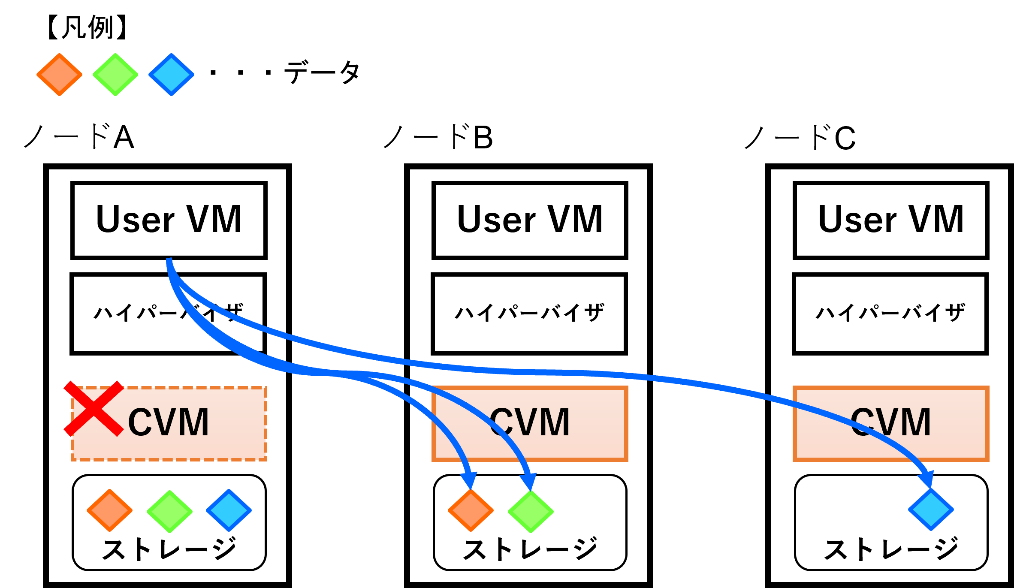
- 拡大
- 図5:CVM障害時のディスクI/Oのイメージ
なお、このルーティングの切り替えに関しても自動で行われるため、管理者が手動でパス切り替えを行う必要はありません。
また、この機能を利用することで、仮想マシンのディスクI/Oを止めることなく、CVM自体のOSバージョンアップ(ローリングアップデート)などを行うことができます。
4.まとめ
今回はNutanixの耐障害性にフォーカスしましたが、障害時の動作についてイメージできたでしょうか。
ディスク障害・ノード障害・CVM障害のいずれのパターンでもゲストOS(仮想マシン)のディスクI/Oは継続できるということがポイントとなります。
また、リビルド(データの復元)は自動で行われ、再びデータの冗長性が復活する点も覚えておいていただければと思います。
先にも記載しましたが、HCI製品の選定には障害時の挙動も比較対象になることが多々あるため、HCI製品に触れる際にはぜひ“耐障害性”に注目してみてください!
なお、Nutanixの基礎シリーズを継続するかどうかは検討中ですが、もし執筆機会があればキャパシティ最適化技術(Erasure Coding、圧縮、重複排除)や管理UIであるPrismについて説明させていただきたいと思います。
最後までお読みいただきありがとうございました!
