


この記事は『CRESCO Advent Calendar 2021』 最終日(25日目)の記事です。
こんにちは、CETにて殿堂入りしました井上です。
“CETって何?”と思ったかたコチラの記事(「困ったら必ず助けてくれる人がいる」クレスコの仕組み紹介します)をどうぞ!
さて、アドベントカレンダーも最終日となりました。
12/1から毎日投稿された、様々なテーマの記事はいかがでしたか?
最終日の記事はディープニューラルネットワーク(以下、DNN)のモデル軽量化について書きます。というのもエッジAIへの取り組みを行なっているのですが、そこで得られたことを記事としてまとめておこうと思います。
現在のDNNは、層の数が多く膨大なパラメータが含まれる傾向にあります。このような巨大なDNNは計算量、メモリ、電力など多くの資源を要求しますが、計算資源の限られたエッジデバイスで動かすには限界があります。
こうした課題をクリアするモデルの軽量化について解説します。

エッジAIとは
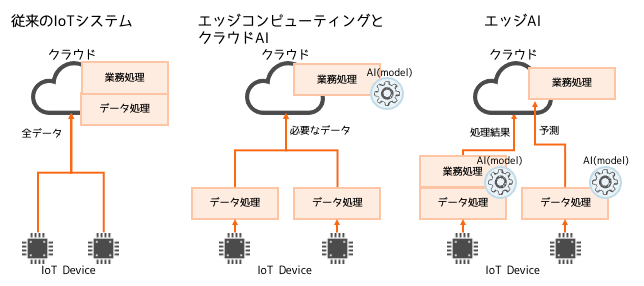
エッジ(edge)は一般的には「ふち」、「へり」などを意味し、まさにその「ふち」のところで動作するAIとなります。では、その「ふち」とはどこなのかと言うとセンサーや測定機器など、データを収集する現場を指します。従来のIoTシステムやエッジコンピューティングは「ふち」にあるセンサーがネットワークを経由し、クラウドサーバにデータを送信し処理を行なっています。これに対しエッジAIは、データの発生源となる現場側にて処理を行います。
このエッジAIのメリットとして、データをその場で処理できるためリアルタイム性の高い機能を実現できることや、ネットワークを経由せず、処理を行えるためデータが外部に漏れず安全性が高いと言えます。また、エッジ側で処理した結果だけをサーバに送れば良いこととなるため、通信量が減りコストの削減が見込まれます。
例えば、農地における鳥獣被害への対策を行うシステムを考えます。
現地にカメラを設置し、撮影された画像から鳥獣を検知した時に警告音を発するとします。
実際のシステムは、もっと複雑と思いますが、話を簡単にしてエッジ側とクラウド側の処理について表に例示します。
表の1番、2番の方法は鳥獣判定をクラウド側で行い、警告の発出指示をエッジ側に送信します。エッジ側からは判断に必要な動画や画像をクラウドに送信しています。これに対して3番のエッジAIでは、エッジ側で鳥獣検知、警告発出までの一連の処理を行い、判定結果だけサーバ側に送っています。 このようにサーバ側に画像を送らず、その場で処理できるため通信の遅延による警告発出の遅れがなく通信費も削減され、レイテンシに依存しないシステムの構築が可能となります。
| # | システム | クラウドへの送信データ | 鳥獣判定 | 警告音発出指示を出す場所 |
|---|---|---|---|---|
| 1 | 従来のIoTシステム | 動画 | クラウドで動画から切り出した画像を解析 | クラウド |
| 2 | エッジコンピューティング | 動画から定期的に切り出した画像 | クラウドで画像を解析 | クラウド |
| 3 | エッジAI | 鳥獣判定の結果 | エッジで画像を解析 | エッジ |

3つの軽量化手法
DNNの軽量化は”蒸留(Distillation)”、”枝刈り(Pruning)”、”量子化(Quantize)”という3つの手法がありますので順に説明します。
蒸留は学習済みモデルの予測結果を教師データとして、より小さいモデルを学習することで軽量化を行います。そして、その小さいモデルは大きいモデルに匹敵する精度を持つことが確認されています。[1]
蒸留では学習済みのモデルをTeacherモデル、小さいモデルをStudentモデルと呼びます。このStudentモデルは、開発者が新たに設計する必要があります。
ここでは分類器を例とした学習データの扱いについて説明します。TeacherモデルはOne-hot表現を教師データとして学習を行なっていますが、StudentモデルはTeacherモデルが出力した値(例:”犬”=0.7、”猫”=0.3)を教師データとして学習します。つまりOne-hotではありません。なお、One-hot表現によるラベリングはハードラベリングと呼ばれ、連続値による表現をソフトラベリングと呼びます。
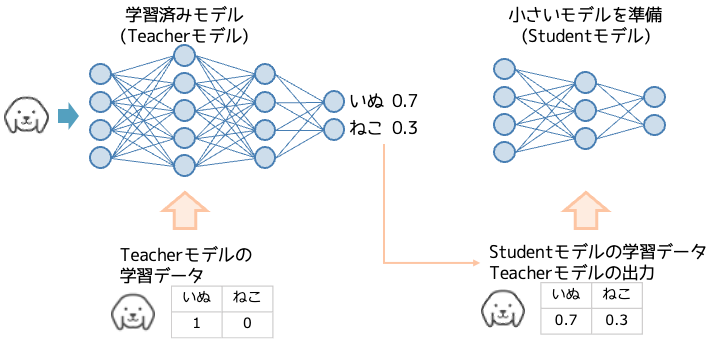
実験によるとStudentモデルは、Teacherモデルと同じハードラベリングされた教師データを使うのではなく、ソフトラベリングを使った方が上手く学習が行えるという事が示されています。
表の1行目はベースモデル、2行目は学習データの3%で学習したもので、3行目も同様に3%ですが、ソフトラベリングによる結果となります。2番目は過学習が起きており、3番目は精度を維持していることがわかります。
| # | System & training set | Train Frame Accuracy | Test Frame Accuracy |
|---|---|---|---|
| 1 | Baseline (100% of training set) | 63.4% | 58.9% |
| 2 | Baseline (3% of training set) | 67.3% | 44.5% |
| 3 | Soft Targets (3% of training set) | 65.4% | 57.0% |
ここでの疑問として、非常によく学習されたモデルの出力はone-hotに近くなるため、この結果をstudentの教師データとして扱ってもソフトラベルと言いつつ、ほぼハードラベルになってしまうのではないか?と私は感じます。多くの場合、そうなると思いますがその場合、ほとんどのクラスにおいて値がゼロに漸近してしまい学習がうまくできない事が懸念されます。その点について、この手法では温度つきソフトマックスを使うことで対処しています。温度つきソフトマックスは温度Tを分母、分子それぞれに与えているという点が通常のソフトマックスと異なります。
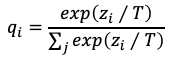
このTの値を小さくしていくとクラス間の差が顕著になりone-hotのような結果が得られるようなります。逆にTを大きくしていくと差が小さくなり、低い確率だった他のクラスから値が出てくるようになりますので、調整したTでソフトマックスした後の値を使い学習を行います。
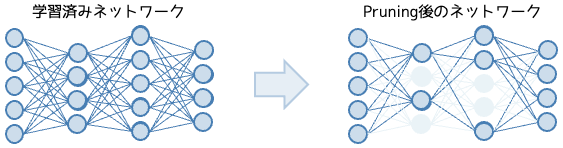
枝刈りは学習済みモデルの重みやノードを削除することで軽量化を行います。これにより計算回数、メモリ使用量の削減が行えます。
この手法はノード間の接続において重みの小さいところを対象に削除を行います。枝刈りは蒸留と違い別途モデルを設計する必要はありませんが、パラメータ削除を行うため精度が低下するため必ず再学習を行い精度を維持する必要があります。
提案手法[2]では3ステップの処理にて軽量化が行われています。最初に行うステップの学習では、重みの他にどの接続が重要であるか学習を行います。 2つ目のステップは重みが閾値以下となるノード間の接続を削除します。 これより密なネットワークを疎なネットワークに変換します。 最後のステップでは再学習を実施します。この時の重みの初期値はStep1、Step2を通過した値を採用します。また、ステップ2,3を繰り返し行う事で精度の良い軽量なモデルを実現します。
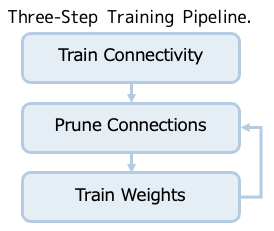
この手法はステップ1,3において学習が行われますが、この際の正則化としてステップ1ではL1正則化を採用します。L1正則化は不要な説明変数を省く作用があり、不要な重みはゼロに寄せられます。これは枝刈り前の学習としては好都合です。ステップ3の再学習では過学習を防ぐためドロップアウトを適用します。ですが枝刈り後のため再学習のたびにノード数が変化する事となります。このためドロップアウト率を調整する必要があります。
提案手法では次の式でドロップアウト率を求めています。
(1)のCiはレイヤーiの接続数を求めています。Niはレイヤーiのノード数となります。
(2)のDrは再学習時のドロップアウト率となります。Doは元のドロップアウト率、Cioを元のネットワークのレイヤーにおけるノード数、Cirは再トレーニング後のネットワークにおけるレイヤーのノード数となります。
(1)
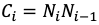
(2)
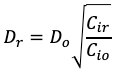
それでは枝刈りによる軽量化の効果について、パラメータの削減やエラーレートについて確認します。
下表は有名な画像認識モデルに対して枝刈りを実施した結果となります。
1列目:対象ネットワーク(モデル)でRefはオリジナルのネットワーク、Prunedは枝刈りを行ったネットワーク
2列目:エラーレート
3列目:パラメータ数
4列名:圧縮率
どのモデルも精度を維持し、パラメータ数が大幅に小さくなっている事がわかります。
最も軽量化されたVGG-16の場合、1億3800万パラメータが、枝刈りによって約1,000万パラメータまで小さくなっています。実に元のモデルの約7.5%と驚異的に小さくなっており、精度も元のモデルと遜色ありません。
| Network | Top-1 Error | Top-5 Error | Parameters | Compresson Rate |
|---|---|---|---|---|
| LeNet-300-100 Ref | 1.64% | – | 267K | |
| LeNet-300-100 Pruned | 1.59% | – | 22K | 12x |
| LeNet-5 Ref | 0.80% | – | 431K | |
| LeNet-5 Pruned | 0.77% | – | 36K | 12x |
| AlexNet Ref | 42.78% | 19.73% | 61M | |
| AlexNet Pruned | 42.77% | 19.67 | 6.7M | 9x |
| VGG-16 Ref | 31.50% | 11.32% | 138M | |
| VGG-16 Pruned | 31.34% | 10.88 | 10.3M | 13x |
量子化はモデルに含まれるパラーメータを少ないビットで表現する事で、ネットワークの構造を変えずにモデルを小さくする手法となります。図では重みパラメータ(w)を6個持つ簡単なネットワークを例にしたものです。32ビット精度の場合は合計192ビットを必要としますが、8ビット精度の制約にすると合計48ビットで表現する事となり、軽量化が行われている事となります。

簡単でしたがモデル軽量化については以上となります。

チュートリアルをやってみた
次に実際の軽量化プログラムを掲載したいところですが、長くなってしまうのでtensorflowによるチュートリアルへのリンクを貼っておきますので、試したい方はそちらを参考にしてください。なお、チュートリアルでは3つの手法のうち枝刈り、量子化の2つの手法を用いてモデルの軽量化を行なっています。必ず3つの手法を使わなければいけないという事はありませんので、ひとつの手法で軽量化したり、蒸留を2度行うなど試してみると良いと思います。
機械学習モデルを最適化する(https://www.tensorflow.org/model_optimization?hl=ja)
なお、実行にはtensorflow本体とは別にTensorFlow Model Optimization Toolkitをインストールしておく必要があります。
下表はチュートリアルを実施して得た結果です。手書き文字認識を行うCNNをBaselineとし、軽量化を行なったところサイズが32.31%と小さくなっています。これだけ軽量化しても精度が0.9633となりました。
| # | モデル | accuracy | サイズ(byte) | 対baseline |
|---|---|---|---|---|
| 1 | Baseline (CNN) | 0.9792 | 78,254 | – |
| 2 | 枝刈り | 0.9635 | 26,118 | 0.333 |
| 3 | 枝刈り+量子化 | 0.9633 | 25,287 | 0.323 |
torchで軽量化を行う場合は、下記が参考になります。
枝刈り(https://pytorch.org/tutorials/intermediate/pruning_tutorial.html)
量子化(https://pytorch.org/docs/stable/quantization.html)
(tensorflow、torchは枝刈り、量子化に対応しています。(蒸留は非対応))
まずエッジAIについて説明し、続いてモデル軽量化の3手法について確認し、チュートリアルや実際に試した結果を紹介しました。
枝刈+量子化による軽量化は、驚異的に小さくなり精度もほぼ維持できる事がわかりました。記事では触れていませんが推論速度も元のモデルと遜色がなく、モデル軽量化は良いこと尽くめな感じです。
こうなると多層で膨大なパラメータを持つDNNじゃなくても、最初から小さいネットワークでいいのではないかと思ってしまいます。ですが実際はそうではないんです。このあたりは、宝くじ仮説などを含め別の機会に記事にしたいと思います。
[1]Distilling the Knowledge in a Neural Network
https://arxiv.org/abs/1503.02531
[2]Learning both Weights and Connections for Efficient Neural Networks
https://arxiv.org/pdf/1506.02626.pdf
それでは、良いクリスマスを!

