


みなさん、こんにちは!
ロボティックテクノロジーセンターのやまさきあです。
ご存知の方も多いかと思いますが、RPAのお仕事をしています。
今回は、そんな私が
UiPathでExcelの紐づけ処理を実施する際に苦労したことをお話しします。
※ この記事では、UiPathのバージョン2019.10.5を使用しています。
3種類のExcelを対象に実施します。
処理は、大きく分けて対象列の抽出と、紐づけ処理に分けられます。
3つのExcelそれぞれについて、必要な列のデータを抽出する処理を実施し、
抽出したデータの中から、指定された紐づけ対象列の値について、
1つ目のExcelの値と一致する存在するデータのみ抽出します。
このようなイメージです。
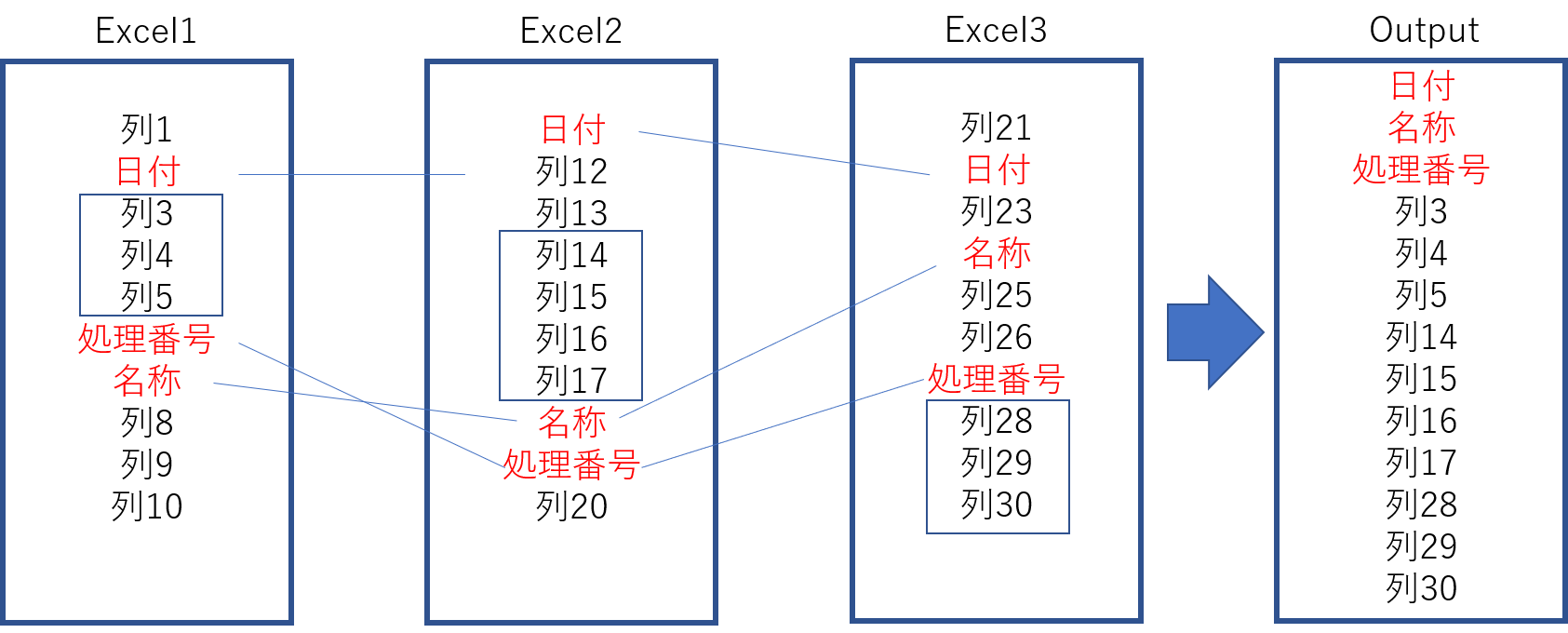
(その後、必要な列を抽出し、昇順に並び替え、データを書き出す処理もあります。)
要件としては、よくあるものではないでしょうか。
ただこのデータ・・・
処理対象のExcelの1つに、50万件以上の行があるものが存在したのです・・・
「データ テーブルを結合 (Join Data Tables)」アクティビティを用いて、
1つ目のDataTableと2つ目のDataTableをInner Join、
上記で出力されたDataTableと3つ目のDataTableをInner Join
という方法で紐づけ処理を実施していました。
その後、必要な行のみ抽出する、という処理を入れていました。
いただいたテストデータで結果が正常なことを確認して、よし!結合テストを実施しよう!ということで
私は、意気揚々とUiPathを実行しました。
すると、結果が返ってこない。
何時間しても、返ってこない。
ファイルを確認すると、処理対象のExcelの1つに、
データが50万行あるファイルが見つかりました。
データ・・・・・・想定していたより多いな・・・・・・・。
テストデータとしていただいていたデータは最大7万件でした。
その時には1時間かからずに処理が返ってきていたので、大丈夫だと思いこんでいました。
(思い込み、本当によくないですね!)
でもこんなことでめげてはいられないので、方法を変えることにしました。
こちら数年分のデータを一気に処理するという仕様でした。
処理の内容的に、2回に分けられるのではないか!と思ったので
ユーザーさんに相談して、データの対象期間を半分にして実行回数を増やす、という運用にしてもらいました。
しかし、それでも20万件超えのデータ。紐づけ処理はうまくいきませんでした(@_@)
データテーブルを結合アクティビティではなく、
Accessに処理を実施させたら、少し速くなるのではないか!?と期待して
Microsoft Accessとデータベースアクティビティを組み合わせて使うことにしました。
まず、Accessでファイルを作成し、3つのテーブルを作成しました。

これに対し、Accessで作成したクエリを実行することで、処理を実施しました。
UiPathの画面はこんなイメージです。
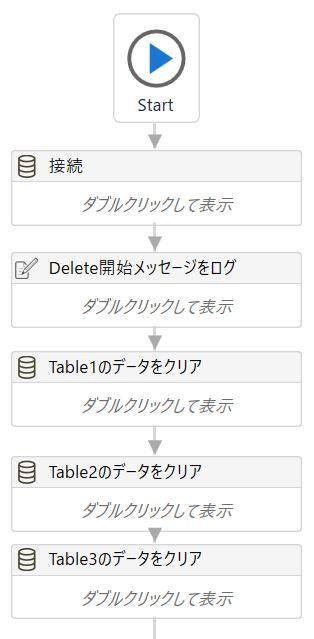
まず対象のAccessファイルを指定してデータベース接続を行い、
その後、一旦すべてのテーブルのデータをクリアします。
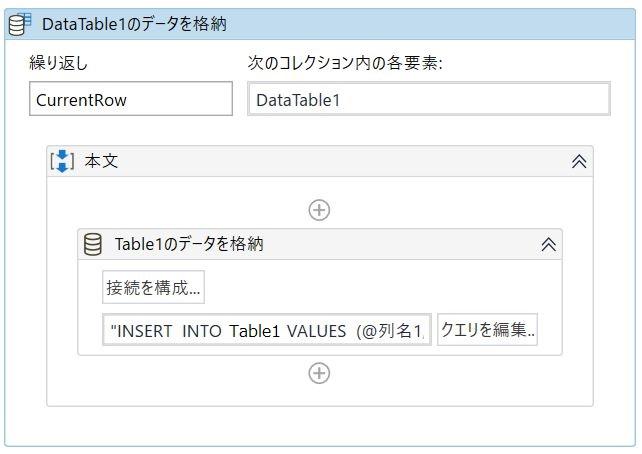
その後、読み込んだExcelのデータが格納されているDataTable変数に対して
行ごとに繰り返し処理を行い、データベース上にデータを格納します。
このとき、DataTableに存在するすべての列ではなく、必要な列のみを格納します。
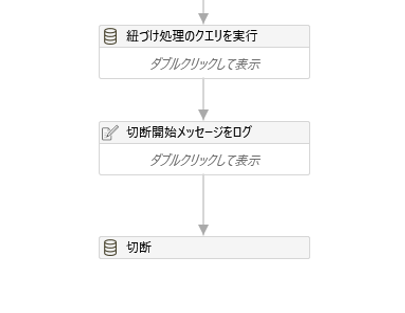
その後、紐づけ処理のクエリを実行し、DataTable型の変数に紐づけ結果を返します。
処理が終わったらデータベースから切断します。
よ~~~~し、これでOK!実行^^
修正したものの、ぜんぜん結果が返ってきませんでした。
もうなすすべがない。私は絶望しました。
でもそこに救世主が現れました。
最近、RPAチームに入っていただいたメンバーがなんと「Accessのプロ」だったのです!!
Accessのプロにソースコードを見てもらうと、
どうやら、紐づけ時に、プライマリキーを適切に指定していなかったのが
処理が遅くなってしまう原因だったようでした!
そのため、こちらについてAccess上で修正することにしました。
(プライマリキーについてはここでは割愛しますので、興味があれば調べてみてください。)
やった!!
ついに結果が30分程度で返ってくるようになりました。
これで、使ってもらえます!!!!!
Orchestratorにパッケージを登録して、トリガーも登録して、
OK!OK!!!
あとは結果を待つのみです。
と思いましたが…。
Studioやバッチ実行では動くのですが、
なぜか、Orchestratorから実行すると、正常に動作しません・・・・・・・・・・・
パッケージ化しただけなのに、なぜ。
処理の最初に、「非クエリを実行」アクティビティで
各テーブルからデータをクリアする「DELETE」を実行する処理がうまく動かないようです。
おかしい。アクティビティは合っているはずだ。
UiPath公式ドキュメントにも、
「For UPDATE, INSERT, and DELETE statements」という記載があるしな~。
困り果ててジョンさんに相談したら、
「非クエリを実行」アクティビティ」ではなくて、「クエリを実行」アクティビティで試してみたらどうですか?という
アドバイスをいただきました。
「非クエリを実行」アクティビティは、クエリを実行した際に影響を受けた対象行の合計が
Int型の変数で返ってくるのに対し、
「クエリを実行」アクティビティは、クエリの結果がDataTable 変数として返されます。
特にDELETE処理で影響を受けた行数が必要でもなかったので、
アドバイス通り、「クエリを実行」アクティビティに変更しました。
無事、Orchestratorからも正常に実行されました。
おめでとうございます!!!!!!
(最新のバージョンではこの事象はもしかすると修正されているかもしれません。)
今回はうまく解決したのでひとまずよかったですが、ふと疑問に思いました。
あれ?もしかしたらAccess使わなくても、
UiPathでプライマリキーを指定することができたりして・・・?
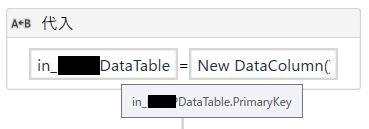
UiPathでは代入アクティビティを使用して、このような感じで書けます。
データテーブル名.Primarykey = New DataColumn() {データテーブル名.Columns.Item("プライマリキーとして指定したい列名"), … , データテーブル名.Columns.Item("プライマリキーとして指定したい列名")}
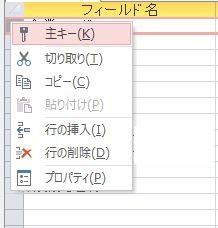
Accessでは、対象のテーブルを開くと、列一覧の情報が表示されるので、
プライマリキーに指定したい列名を右クリックして「主キー」を押せば、その列をプライマリキーに設定できます。
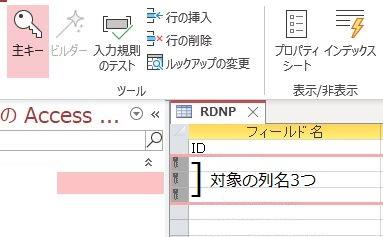
複数の列を1つのプライマリキーとして指定したい場合にも、
複数選択→主キーボタンクリックで簡単に操作ができます。
書いてみた感覚としては、
Accessの方がコーディングなしで操作できるので、簡単な印象です。
使用したのは、以下3つのデータです。
約7万行のデータ×約800行のデータ×約800行のデータ
こちら3つのデータに対しの紐づけを行いました。
また、その後
必要な列を抽出し、昇順に並び替え、データを書き出すところまで実施しました。
データの紐づけには「データテーブルを結合」アクティビティ、
昇順並べ替えには「データテーブルを並べ替え」アクティビティ、
データ書き出しには「データ テーブルをフィルター」アクティビティを使いました。
かかった時間:03:07
なかなか速いですね!!
こちらの詳細は、上記に記載した通りです。
かかった時間:04:41
速度的にはUiPathが速かったですね(^^)/
接続やデータの格納はコーディングしなくてはなりませんが、
プライマリキーの設定はボタンをクリックしたり選択したりというように、
ノンコーディングで実施できるので、ストレスがなく操作できたな~と思いました。
また、処理のクエリを書くのが難しそう・・・という方も、
デザインビューというものがあるので、簡単に操作できます。
引っ張られている黒線が、紐づけをする列の情報です。
また、列のソートも昇順・降順・なしを選択するだけとなっています。
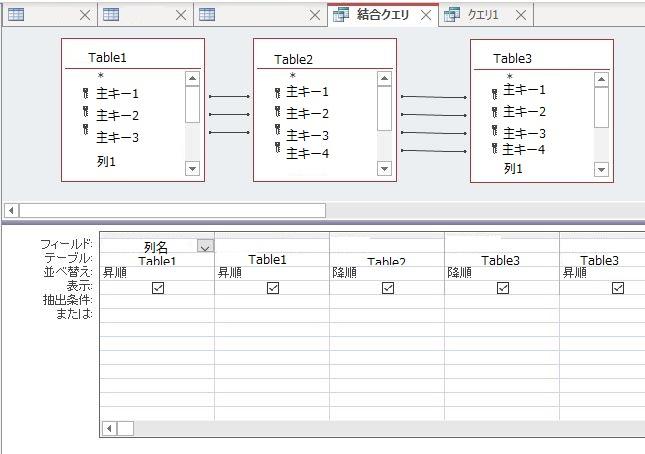
こちらのタブを右クリックしSQLビューを開くと、クエリが表示されます!
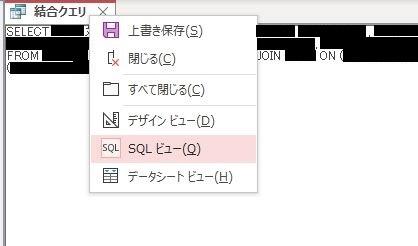
この内容をUiPathのクエリ記述箇所に記載するだけです。
とても便利だと思いませんか?
今回のデータ量だと1分くらい速かったので、速度を求めるのであれば
UiPathが良いでしょうか。
ただその分、メモリ消費は大きいです。
下に最大メモリ使用量を示します。
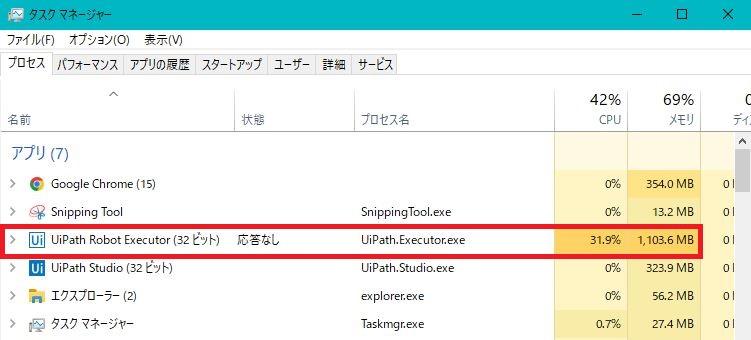
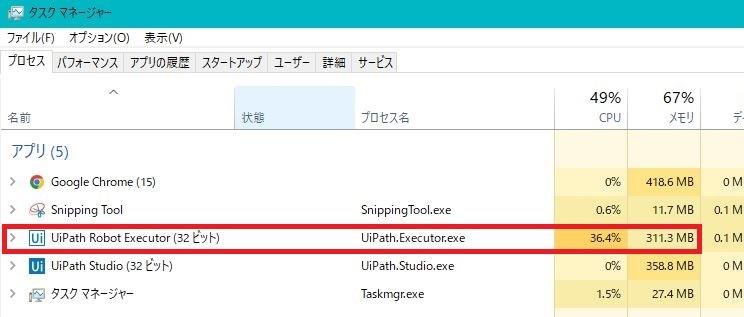
Accessでは最大でも400MB程度でしたが、
UiPathでは最大1,000MBを超えることがありました。
UiPathは結構メモリをたくさん使っていますね。
速度を求めたい!UiPath以外のファイル管理をしたくない!
という方は、Accessに頼らない方法で処理を実施する方法を好まれると思います。
私の感想としては、Accessを使用するとコーディングすることが少なく、実装が簡単だったので
データベース初心者の方にもオススメだなという印象でした。
また、データテーブルを結合する際に使用する結合の種類についても
「今回はINNER?LEFT?それともRIGHT?」とならなくて済むのでとても楽でした。
あとこれは願望になってしまうのですが、私はUiPathのアクティビティに、
「プライマリキーとして指定」ができると、とても便利そうだなと思っています!!
みなさんは、どう感じましたか?
また、今回は問題にならなかったのですが、RPAチームの吉田さんにこの話をしてみると、
過去には100万件以上のデータを扱ったこともあるらしく、
その時はUiPathでDataTableに読み込むこと自体にすごく時間がかかったそうです。
今回は、ファイルの読み込みに関してはそれほど時間がかからなかったのですが
確かに、行数が増えれば増えるほど読み込みには時間がかかりそうですね。
その際の対処法としては、マクロを使って、
案件番号などでフィルターした行だけを別のExcelファイルに出力するという前処理を行ったそうです。
そのファイルで処理するようにしたら、なんと
数時間かかっていた処理時間が数秒になったそうです!
「事前に50万件を条件によってフィルターできるようならそうするのが一番シンプルかもしれないね。」
ということでしたので、あてはまりそうな場合にはこちらも参考にしてみてください。
- Excelを使用する際には、本番のデータが何行あるかを確認する(基本の「き」です!!)
- Excelの行数が多い場合には、プライマリキーを指定すると、実行速度向上につながる
- データベースアクティビティとAccessを使うと、コーディングを少なくできる
- Orchestratorで実行する際に「非クエリを実行」アクティビティでうまく動作しない場合には、「クエリを実行」アクティビティを使用してみる
- 必要な場合には、マクロを使ってフィルターした行だけを別のExcelファイルに出力するという前処理を行う
技術的なまとめは以上ですが、その他にも、
- 周囲に相談して、アドバイスをいただく
- UiPathで処理を記述する可能性のある、データベース等の知識を身に着ける
ということも大事であると気づき、
3人寄れば文殊の知恵、といったような感じで、チームで働くことで生まれる知恵もあるのだな~と、
チームで働くことの有意義さを改めて体感しました。
また、知識面については、エンジニアとしてまだまだだな~と改めて感じました。
データベースやネットワーク等、RPAエンジニアに必要な知識を身に着けるための勉強会や
フルスタックエンジニアになるための勉強会は、社内で開催していただけるとのことですので、
そちらに参加して知識を得てきます!!!(とてもいい会社だと思いました。)
以上、やまさきあのお送りする
「UiPathで行数が多いExcelを処理するのにてこずった話」でした。
読んでいただきありがとうございました。
