


技研のまつけんです。
機械学習をやっているとsequentialでない、枝分かれのあるモデルも扱います。先日の記事でも、複数の学習済みモデルを並列に接続することで、結果的に (小規模ですが) 枝分かれのあるモデルを構築しました。
このような場合、テキストベースで記述することが多いのですが、ビジュアルに編集できたら便利です。ビジュアルにプログラミングを行うツールとして、SONY Neural Network ConsoleやSimulinkなどが知られていますが、プラットフォームを限定せず、手軽に利用できるツールがあると、ちょっとしたときに役に立ちそうです。
これらのツールで記述するのは、数学用語でいう“グラフ”です。一般的にグラフというとxとyの関係を“プロット”するようなものをイメージしますが、ここでいうグラフはこちらに書かれているような、nodeとedgeから構成されるものです。
PowerPointやExcelでは、矩形や楕円などの図形を矢印 (コネクタ) で結んで、この“グラフ”を描くことが出来ます。このグラフから隣接行列や二分木を作ることが出来れば、例えば、PowerPointで
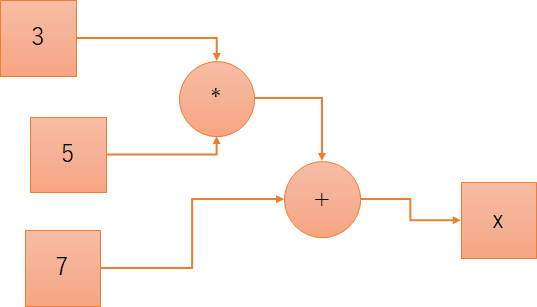
のように描いたものを
x = 3 * 5 + 7
という文字列に変換できそうです。今回は、Beautiful SoupというXML/HTMLパースライブラリを使ってPowerPointのグラフを隣接行列に変換するものを作ってみました。
今回は、矩形や楕円などの図形と矢印を抽出する実験として、以下のグラフを隣接行列に変換してみます:
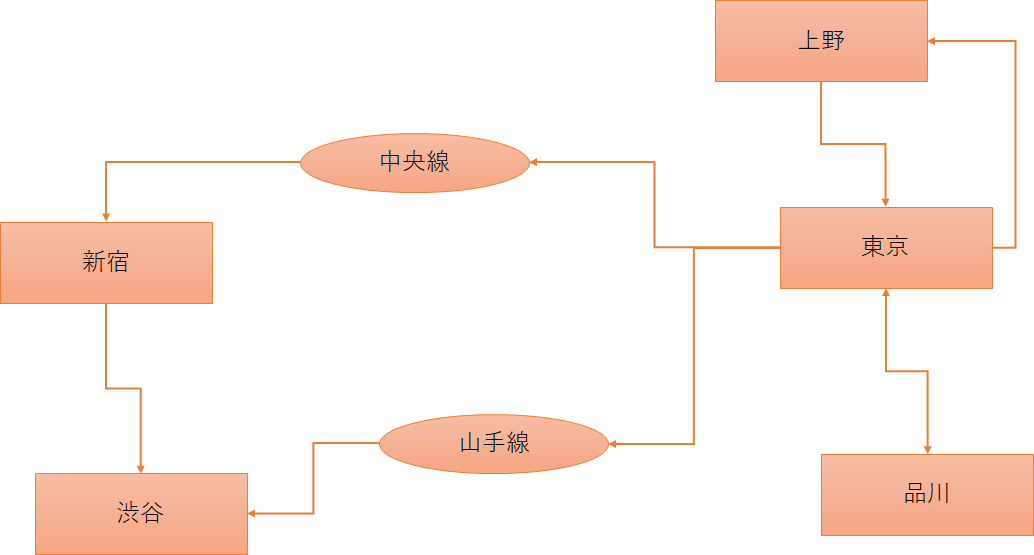
駅の名前は矩形オブジェクトで表し、それらの間の移動を矢印で示します。駅と駅の間には楕円で路線名を指定することが出来ます (指定しなくても良い)。
以前の記事で紹介したunpack_pptx.shでpptxファイルをzipファイルとみなして展開します。その中のslide1.xmlをBeautiful Soupで解析してみます。Importするライブラリは以下の通りです:
| from bs4 import BeautifulSoup |
| import numpy as np ; na = np.array |
| import pandas as pd |
まずは、Beautiful Soupで読み込みます (元のPowerPointのファイル名はarrow_diagramme.pptx):
| SLIDE_NO = 1 |
| with open('arrow_diagramme/ppt/slides/slide%d.xml' % SLIDE_NO) as f: |
| s = f.read() |
| soup = BeautifulSoup(s, 'html.parser') # または soup = BeautifulSoup(s, 'xml') |
まずは、矩形 (rectangle) と楕円 (oval) の一覧を取得します。矩形や楕円などの図形は、以下のように記述されています (今回の記事に関係のないタグは省略、以下同じ):
| <p:sp> |
| <p:cNvPr id="6" name="正方形/長方形 5"> |
| <a:prstGeom prst="rect"> |
| <a:t>品川 |
| </a:t> |
| </p:sp> |
<a:prstGeom prst=”rect”>のrectが図形の種類 (rectangle) です。楕円はellipseです。他には、例えば、以下のようなものがあります:
| 二等辺三角形 | triangle |
| 角丸四角 | roundRect |
| 左矢印 | leftArrow |
| 右矢印 | rightArrow |
| 下矢印 | downArrow |
| 上矢印 | upArrow |
今回は矩形と楕円だけと仮定して、それら以外は無視します。2つめのfor文で通し番号を追加していますが、これはあとで隣接行列にする際の列番号、行番号となるものです (楕円の通し番号は不使用)。
| objs = {} |
| for p in soup.find_all('p:sp'): |
| idno = int(p.find('p:cnvpr').get('id')) |
| prst = p.find('a:prstgeom').get('prst') |
| texts = [t.string for t in p.find_all('a:t')] |
| text = ''.join([t if '\n' != t[-1] else t[: -1] for t in texts]) |
| objs.setdefault(prst, {}) |
| objs[prst][idno] = text |
| for prst in objs: |
| objs[prst] = {idno: (i, objs[prst][idno]) for i, idno in enumerate(objs[prst])} |
| rects = objs['rect'] |
| ovals = objs['ellipse'] |
| print(rects) |
| print(ovals) |
図形内部の文字列は、途中でフォントや文字サイズが変更されていると複数に分かれてしまうので、find_all()で探し、末尾の改行を除去して連結します。駅名と路線名が各図形のIDと共に抽出されています:
| {4: (0, '上野'), 5: (1, '東京'), 3: (2, '新宿'), 6: (3, '品川'), 33: (4, '渋谷')} |
| {9: (0, '中央線'), 46: (1, '山手線')} |
続いて、矢印の情報を抽出します。矢印は、以下のように記述されています:
| <p:cxnSp> |
| <p:cNvPr id="11" name="コネクタ: カギ線 10"> |
| <a:stCxn id="5" idx="2" /> |
| <a:endCxn id="6" idx="0" /> |
| <a:headEnd type="triangle" /> |
| <a:tailEnd type="triangle" /> |
| </p:cxnSp> |
3行目と4行目の「id」は接続先の図形のIDです。a:headEndタグが存在する場合は始点が、a:tailEndタグが存在する場合は終点が矢印 (や丸など) になっていることを示します。上の例は、5番と6番を接続するコネクタで、両頭矢印であることを示しています。
| edges = [] |
| for p in soup.find_all('p:cxnsp'): |
| start = int(p.find('a:stcxn' ).get('id')) |
| end = int(p.find('a:endcxn').get('id')) |
| if p.find('a:headend') is not None: |
| edges.append((end, start)) |
| if p.find('a:tailend') is not None: |
| edges.append((start, end)) |
| print(edges) |
矢印が、どの図形からどの図形に引かれているか、tuple形式で抽出されました:
| [(4, 5), (5, 9), (5, 6), (9, 3), (3, 33), (5, 46), (46, 33), (5, 4)] |
なお、正しく接続されていない矢印がある場合、find()がNoneを返すため、
| AttributeError: 'NoneType' object has no attribute 'get' |
というエラーが出ます。
これらの情報から隣接行列を作ります:
| mat = np.zeros([len(rects)] * 2, dtype='str').tolist() |
| for i in range(len(rects)): |
| mat[i][i] = '*' |
| for start, end in edges: |
| if start in rects and end in rects: |
| mat[rects[start][0]][rects[end][0]] = '1' |
| print(start, end) |
| for idno in ovals: |
| text = ovals[idno][1] |
| frm, to = None, None |
| for start, end in edges: |
| if start == idno: |
| to = end |
| elif end == idno: |
| frm = start |
| mat[rects[frm][0]][rects[to][0]] = text |
| print(idno, text, frm, to) |
各図形について、自分から自分への矢印は無いと仮定し、対角成分は*で埋めています。結果をPandas DataFrameとしてCSV ファイルに保存します:
| index = [rects[key][1] for key in rects] |
| df = pd.DataFrame(mat, index=index, columns=index) |
| df.to_csv('slide%d.csv' % SLIDE_NO) |
生成されたCSVファイルは
| 上野 | 東京 | 新宿 | 品川 | 渋谷 | |
| 上野 | * | 1 | |||
| 東京 | 1 | * | 中央線 | 1 | 山手線 |
| 新宿 | * | 1 | |||
| 品川 | 1 | * | |||
| 渋谷 | * |
のように、路線名を楕円で指定した部分には路線名が、指定が無い部分は1が入っています。なお、分岐のある機械学習モデルの記述や、単純なビジュアルプログラミングに利用することが目的なので、双頭矢印は完全に対応していません。駅間に路線名を入れる場合は、双頭矢印を使うと正常に解釈されないという制限があります 。
次回は、今回の内容を踏まえて、冒頭の
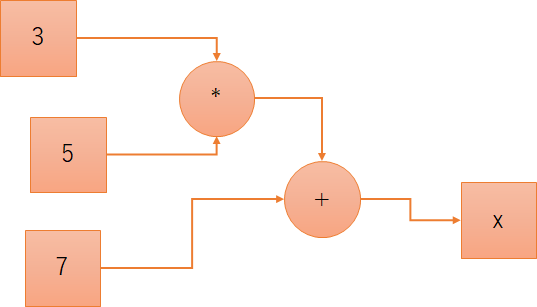
から実際に
| x = ( ( 3 * 5 ) + 7 ) --> 22 |
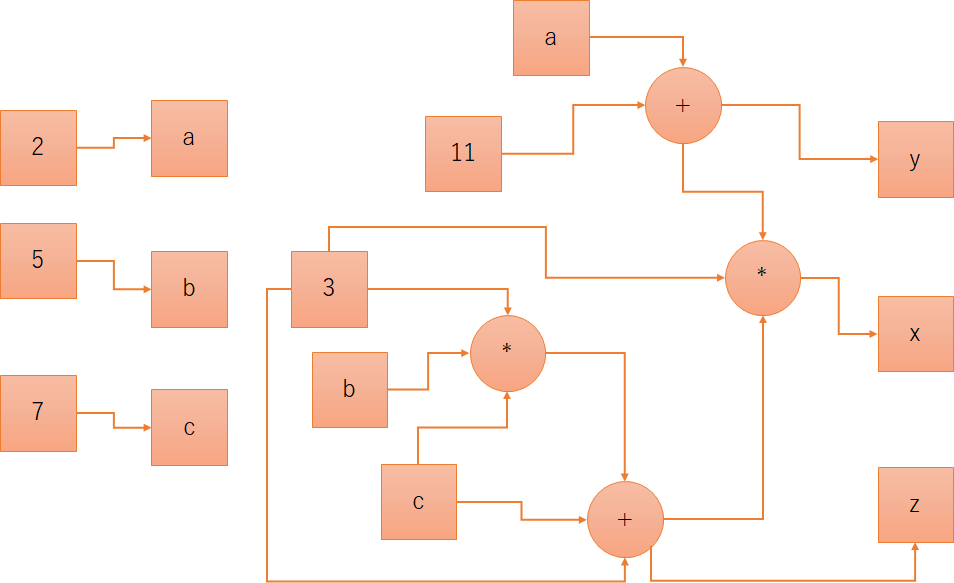
から
| a = 2 --> 2 |
| b = 5 --> 5 |
| c = 7 --> 7 |
| x = ( ( ( 3 * b * c ) + c + 3 ) * 3 * ( a + 11 ) ) --> 4485 |
| y = ( a + 11 ) --> 13 |
| z = ( ( 3 * b * c ) + c + 3 ) --> 115 |
