


こんにちは、技術研究所のウエサマです。
このエントリーは、”自然言語分類器 IBM Watson Natural Language Classifier”の後編となります。
前編はこちら⇒自然言語分類器 IBM Watson Natural Language Classifier(前編)
前回の記事ではIBM Watson Natural Language Classifier(以下 NLC)の概要、生成のステップ、トレーニングデータの準備まで記述しました。今回はその続きとして準備したトレーニングデータをもとに分類器を生成してみます。ただし、単に分類をするのではなく分類したクラス名が答えとなるようトレーニングし日本語によるなんちゃって質問応答システムを作ってみます。
大まかな手順としては、BluemixのダッシュボードからNLCサービスを作成し、このサービスに対してトレーニングデータをアップロードすることで分類器を生成します。その後、分類器に対して質問を行いクラスの取得を行ってみます。
BluemixにログインしNLCサービスの作成を行います。
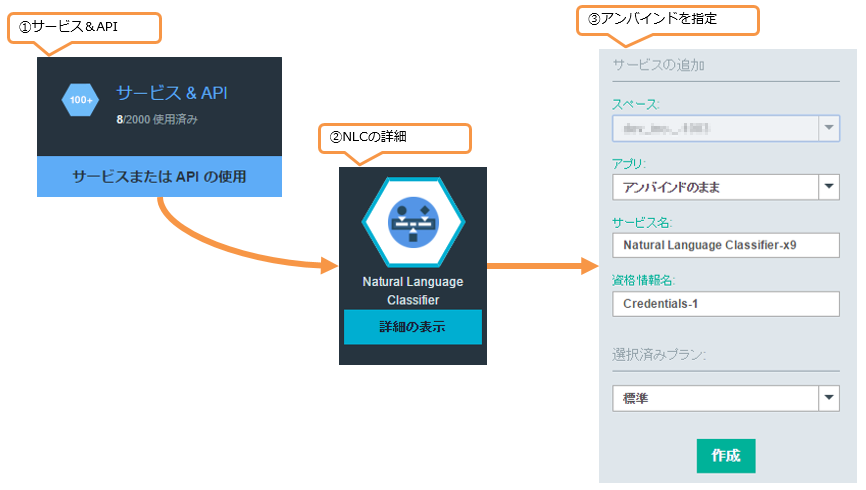
①「サービス&API」
ダッシュボードから「サービス&API」を選択します。
②「Natural Language Classifier」
いくつかサービスが表示されますので、その中からNLCを選択します。
③「作成」
NLC選択後、NLCに関する説明(概要や料金など)があります。右側ペインにサービス追加時に指定する項目がいくつか表示されますが、デフォルトで問題ありません。ただし、アプリ項目は”アンバインドのまま”となっている事を確認してください。 今回、アプリは作らずにCURLコマンドだけでサービスを使うためアプリへのバインドは行いません。
作成したサービスへアクセスする際に指定する資格情報を取得します。この資格情報はAPI実行時に渡すusername, passwordとなります。
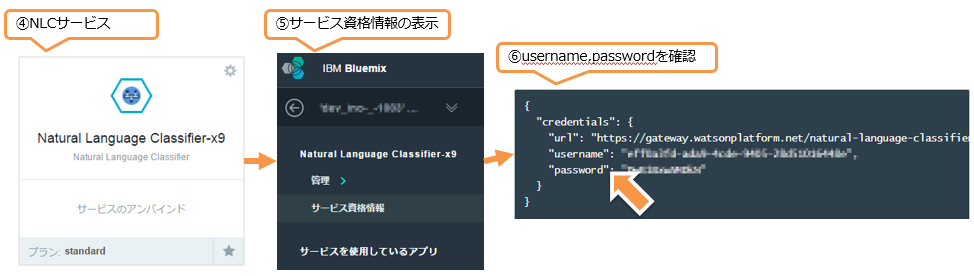
④「NLCサービスを選択」
取得はダッシュボードから先ほど作成したしサービスを選択します。
⑤「サービス資格情報の表示」
左側ペインに表示される「サービス資格情報」を選択し資格情報を表示させます。
➅「username, password」
中央のペインに資格情報が表示されますので、その中にあるusername, passwordを控えておきます。
資格情報を使って分類器の一覧を表示させてみます。当然のことながら分類器はまだ生成していませんので、結果は何も返ってきませんがNLCサービスを実行するための環境ができている事は確認できます。
分類器の一覧表示APIを実行(試しにやってみる)
| 分類器一覧表示API(GET) | /v1/classifiers |
| curl -X GET -u “username“:”password” -H “Content-Type:application/json” “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/” | |
まだ分類器は作っていませんので、情報はありません。
| {
“classifiers” : [ ] } |
準備したデータはAPIを使いアップロードする事でトレーニングされた分類器が生成されます。ポイントとしてトレーニングメタデータのパラメータにある言語指定を”ja”とします。この指定により日本語が扱える分類器の生成が可能となります。(データの文字コードはUTF-8です、くれぐれも)
アップロードしたデータに問題が無ければ、続けて分類器の作成、トレーニングが自動で行われます。
| 分類器生成&トレーニング実行API(POST) | /v1/classifiers |
| curl -u “username“:”password” -F training_data=@トレーニングファイルの名前 -F training_metadata=”{\”language\”:\”ja\”,\”name\”:\”分類器の名前\”}” “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers” | |
コマンドの実行結果が表示され、その中に分類器のIDが含まれていますので控えておきます。
| { “classifier_id” : “分類器のID“, “name” : “分類器の名前”, “language” : “ja”, “created” : “2015-11-07T08:57:43.127Z”, “url” : “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID”, “status” : “Training”, “status_description” : “The classifier instance is in its training phase, not yet ready to accept classify requests” } |
分類器の生成に時間がかかるためAPIを使い、定期的に状態の確認を行います。
| 分類器の状態確認API(GET) | /v1/classifiers/分類器のID |
| curl -X GET -u “username“:”password” -H “Content-Type:application/json” “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID“ | |
下記のように応答されますので、statusを確認します。TrainingからAvailableに変われば分類器の生成は終了です。参考までに今回のデータの場合20分程かかりました。
| {
“classifier_id” : “分類器のID”, } |
以上で分類器の生成が終わりました。
それではさっそく日本語で質問してみましょう。
| 分類の実行API(POST or GET) | /v1/classifiers/分類器のID/classify |
| curl -X POST -u “username“:”password” -H “Content-Type:application/json” -d “{\”text\”:\”質問文\”}” “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID/classify” | |
ここでは質問として「寒さに強い犬は?」を指定し実行したところ、下記の応答を得ました。
| { “classifier_id” : “分類器のID”, “url” : “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID”, “text” : “寒さに強い犬は?”, “top_class” : “バーニーズ・マウンテン・ドッグ“, “classes” : [ { “class_name” : “バーニーズ・マウンテン・ドッグ”, “confidence” : 0.6360431393716911 }, { “class_name” : “ボルゾイ”, “confidence” : 0.08441550944285146 }, { “class_name” : “キャバリア・キング・チャールズ・スパニエル”, “confidence” : 0.03186911707549903 }, { “class_name” : “ボストン・テリア”, “confidence” : 0.019644797549845147 }, { “class_name” : “ボクサー”, “confidence” : 0.012418794255164262 }, { “class_name” : “ビション・フリーゼ”, “confidence” : 0.012264892145703393 }, { “class_name” : “プーリー”, “confidence” : 0.011991592856004813 }, { “class_name” : “トイ・プードル”, “confidence” : 0.011724383509932514 }, { “class_name” : “ミニチュア・ピンシャー”, “confidence” : 0.011653499008156884 }, { “class_name” : “ウェルシュ・コーギー・ペンブローク”, “confidence” : 0.011226371474244018 } ] } |
トップに分類されたのはバーニーズ・マウンテン・ドッグでしたね、これは正しいと思います。2番目のボルゾイから確信度ががた落ちですがボルゾイも厳しい寒さに強い犬種ですので、これもあってますね。それ以降はちょっと怪しいですが・・・
無事に分類器ができましたが、実際の運用にのせるには、もっと様々な質問を与えて、その妥当性を検証する必要がありそうです。
さて、せっかく確信度も得られていますので、なんちゃって質問応答システムとするならこの確信度によって回答文をアプリで生成するのも手かと思います。
例えば
0.6以上なら、「その犬種は、トイ・プードルに違いねぇ」
0.4~0.6未満なら、「たぶん、トイ・プードルだと思います」
0.3~0.4未満なら、「ちょっと自信ありませんが、もしかしたらトイプードルかもしれません」
それ以下なら「ごめんなさい、わかりません。」
ちょっとしたデモなら、これでいいかもしれませんね。
一通り確認ができ満足したので、分類器を削除し記事を閉めたいと思います。
| 分類器の削除API(DELETE) | /v1/classifiers/分類器のID |
| curl -u “username“:”password” -X DELETE “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID“ | |
念のためステータス確認をしてみます。
| curl -X GET -u “username“:”password” -H “Content-Type:application/json” “https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/分類器のID”
結果:
{
“code” : 404,
“error” : “Not found”,
“description” : “Classifier not found.”
}
|
ちなみに削除は3秒ほどでした。
なかなかつながらないコールセンターにやっと電話がつながり、音声ガイダンスに従い目的の答えにたどりつく。そんな経験したことありませんか?
| ・紛失・ロック解除に関するお問い合わせは#1を ・口座開設、解約に関する問い合わせは#2を ・残高照会、お取引状況の確認は#3を ・商品、キャンペーンに関するお問い合わせは#4を ・氏名変更、住所変更に関するお問い合わせは#5を ・その他のお手続きは#6 ・オペレータへのお問合せは、そのままお待ちください。 もう一度お聞きになる場合は・・・ |
音声ガイドを繰返し聞きたくないし、何番まであるのかわからない分類先に1度聞いただけで分類しようと、けっこう必死だったりします。
質問を照らし合わせ、自分で分類している。こんな体験はもう終わりにして、自然言語で質問すると勝手に分類してくれ簡単に知りたい事が分かる。
それに使えないかなぁと今回の記事を書いていて思いました。
さて、長々と書きましたがNLCに関してAPIを含め一通りの動作を確認しましたが、ひとつだけ調査不十分なものがあります。それはトレーニングデータに含まれていない場合でも、分類器は類推し正しく分類するとされる点です。
実際”日本原産の犬は?”という質問で試したところ正しい答えを得る事はできませんでした。データに秋田犬、柴犬、スピッツなど日本原産の犬に関する情報をトレーニングデータを含めていましたが「ポメラニアン(0.22)、キャバリア(0.12)、秋田犬(0.11)」と分類されました。(カッコ内は確信度)
秋田犬が3番目というのもイマイチですが、そもそも確信度が低く質問に対する分類はできていないとみるのが正しいでしょう。今回のトレーニングデータに秋田という地名は含まれていましたが、日本という単語は一切含まれていませんでした。秋田が東北地方で、かつ日本の県、都市のひとつだという知識が十分でなかったのかもしれません。このあたりは正式な日本語対応を待ってから再度調べてみるのが良いかもしれません。
