


こんにちは、技術研究所のウエサマです。
本ブログにて取り上げた、自然言語分類器 IBM Watson Natural Language Classifier(以下、NLC)に記載した内容を活用し、日本語のしゃべれる質問応答システムとしてRaspberry pi(以下、ラズパイ)上に構築してみましたので、その様子を構成や仕組みについて記載します。
尚、質問応答システムと書いてますが、単に分類器をうまいこと使い、質問応答風に見えるよう開発したものです。
参考:

Raspberry Pi で Watson 日本語質問応答システム

ラズパイ本体にマイクとスピーカ、電源、Wifiが接続されています。
尚、スピーカは外部から電源を取れるタイプにしています。
(さすがにラズパイからの電源供給は厳しい)
たとえば、これにモバイルバッテリを使い、ぬいぐるみに埋め込めばCogniToysのような事も実現できます。(CogniToysはWatsonの頭脳を持つ子供向け玩具)

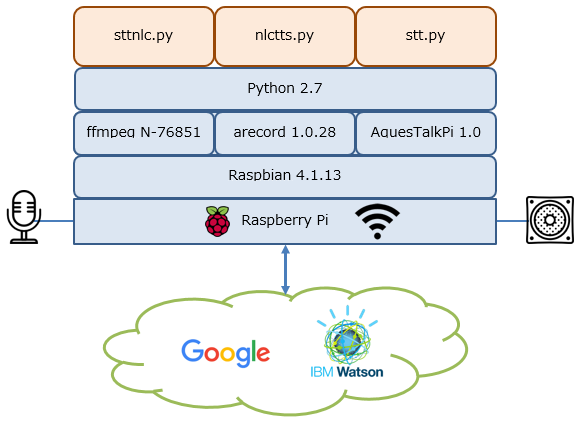
システム構成
実装はPythonにて行っています。
システム構成図の上段3つが今回開発したもので、合計130stepという規模です。
- sttnlc.py — マイクから入力した音声をテキストに変換し、Watsonの自然言語分類器に渡す機能
- stt.py — Google Speech APIを処理する機能(Watson Speech To TextではなくGoogle使いました)
- nlctts.py — 自然言語分類器から得たクラスと確信度を使い、文章を組み立てて発音する機能
日本語の音声入力、音声出力に関して当初Speech To Text、Text To Speechとしていましたが、結局使わず別のものを採用しました。理由は後述します。
WatsonはNLCだけとなります。

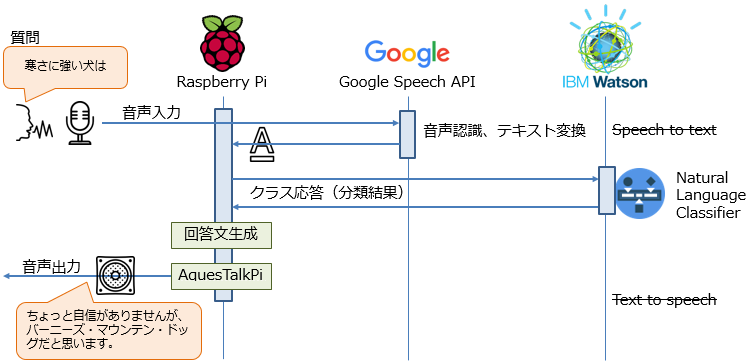
システムのフロー
本システムのフローは次のようになっています。

完成品のデモ
実際に動作している動画です。(音がでます)

音声認識 Watson VS Google
今回Watson Speech To Text、Google Speech APIの両方使ってみて、最終的にGoogleを使う事にしたのですが、その時の評価や思った事を書きたいと思います。
注:Watsonは日本語対応を正式表明していません。私が勝手にやってますので、正式リリース後に改めて確認すべきです。念のため補足。
両者おおむね認識してくれるが、Watsonはときどき変な事を言い出します。
いくつかの音声を試した結果を示します。(かっこ内は確信度)
テスト1:今回開発したシステム向けの質問文
| 音声入力 | 寒さに強い犬は? |
| Watson | ええ 寒さ に 強い 犬 は(0.49) |
| 寒さに強い(0.94) |
Watsonの確信度が低いことと、”ええ” が気になります。
”ええ”って言ってないし。私の滑舌が悪い??(`Д´) ムキー!
Googleは”は”が欠落していますが、分類器にかけるには十分な情報量です。
テスト2:よくある質問文
| 音声入力 | この近くの美味しいラーメン屋かそば屋は? |
| Watson | この 近く の 美味しい ラーメン屋 か そば屋は(0.71) |
| この近くの美味しいラーメン屋かそば屋は(0.91) |
こちらはWatsonもGoogleも正しく認識しています。
テスト3:少し長めの文章
最後は”神隠し”と言ったつもりですが、後で音声データを確認したら”かみか”で切れていました。
| 音声入力 | スタジオジブリの長編アニメーション映画、千と千尋のかみか |
| Watson | スタジオ ジブリ の 長編 アニメーション 映画 千 と 千尋 の 神隠し(0.91) |
| スタジオジブリの長編アニメーション映画 千と千尋のかみか(0.97) |
音声データが”かみか”で切れているので、忠実なのはGoogleとなりますが、Watsonは類推から”神隠し”と判断しているようです。しかも確信度が非常に高い。(できるな、Watson)
ここまでの例では、どちらでもいいような感じがしますね。
今回はテスト4、5の状況からGoogle Speech APIを使う事にしました。
テスト時の音声データもアップしておきます。(フォーマットはSiteの都合上mp3に変換しています)
テスト4:謎の犬現る。
| 音声入力(実際のデータを再生できます)
音声プレーヤー |
しつけのしやすい犬は? |
| Watson | 月 の 深水 犬 は(0.55) |
| しつけのしやすい犬は(0.90) |
Watsonの認識がひどいですね。月の深水犬って、謎すぎるw しかも確信度0.55って(汗)
テスト5:正しいのに自信がない
| 音声入力(実際のデータを再生できます)音声プレーヤー |
日本原産の犬は? |
| Watson | 日本 原産 の 犬 は(0.37) |
| 日本原産の犬は(0.94) |
Watsonは正しい認識をしていますが、確信度が低いです。(ノイズが影響したか??)
アプリとしては信頼度を判断して入力データとして採用するか決めますが、ちょっとコレは頂けませんね。
処理としては聞き直すか、とぼけてごまかすか・・・
いまのところ試してみてGoogle Speech APIは安定しているなぁという感想です。
逆に言うと正式日本語対応まえのWatsonは、ココまでできているという評価もできます。
正式リリースが楽しみです。

似たような質問の分類は同じだが、確信度が違う件
私たちにとってはどれも同じ質問と解釈できますが、Watsonの分類器は少し違うように解釈しているようで、確信度にブレがあります。
こうしたものはトレーニングデータを見直し、期待した確信度が得られるよう調整が必要になります。
確信度0.71は文句無しに採用ですが、0.40, 0.55はアプリでの扱いに困りますね。
質問と分類器の確信(その1)
| 質問 | 寒さに強い犬は |
| Watson | バーニーズ・マウンテン・ドッグ(0.40) |
質問と分類器の確信(その2)
| 質問 | 寒さに強い犬 |
| Watson | バーニーズ・マウンテン・ドッグ(0.71) |
質問と分類器の確信(その3)
| 質問 | 寒さに強い犬種は |
| Watson | バーニーズ・マウンテン・ドッグ(0.55) |

まとめ
【全体を通して】
- Watsonの自然言語分類器(NLC)を用いて、なんちゃって質問応答システムをラズパイ上に構築した。
- 音声認識はGoole Speech APIを採用した。
- 音声合成はクラウドサービスを使わずローカルで行った。(正直どちらでも良いが、今回はわざわざネットを経由しなくていいだろうと判断)
- 漢字の読み間違いがある。(別途、辞書が必要)
今回、犬種に関する分類器の他に、映画情報やラーメン情報といった分類器も作ってみた。
その時に判明した読み間違いの例。
”千と千尋の” これは ”せんとセンジンの” と読上げてました。(Watson Text To Speech)
なぜか自分が、ちょっと恥ずかしくなった。
このことから日本語の読みについては、読み方に関するデータを辞書として別途持つ必要があると考えます。
参考までにローカルで音声合成を行ったAquesTalkPiはちゃんと読めてました。
【苦労したこと】
- 質問を聴くタイミングを図るのが難しい
質問を聞く状態を、どう作るかが悩みどころでした。何か考えないと全く人の話しを聞かない嫌な奴になってしまいます。
当初、ぬいぐるみに埋め込む想定でしたので、メッセージの表示や、質問開始ボタンのようなトリガーが実装できません。
このため常時ヒアリング状態とするか、一定間隔で”質問ありませんか?”と発話してから質問を受ける。
または加速度センサーにて持ち上げられた事を検出し質問を受けるなどが考えられます。
今回は一定間隔の方式を取りました。(簡単なので^^)
【今後】
- Dialog、Retrieve and Rankを併用した、本格的な会話形式に機能拡張
- ぬいぐるみ仕込んでみる
- Speech To Text, Text To Speechを組込んだWatsonフルバージョンを作ってみる

さいごに
IBM Watsonの日本語対応は2015年12月という予定となっていますので、正式リリース後に改めて評価してみるのが良いと思っています。
ちなみに当初の発表では「Watson Engagement Advisor」などが対象に入っていましたが、これを支えるQuestion and Answer serviceが11/20に提供を停止すると正式な発表がありました。(発表はコチラ)
という事はですよ、当初予定の「Watson Engagement Advisor」の日本語対応ができないという事態になると思うんですよね。どうするのかな。
そしてQuestion and Answer serviceの代わりに半年くらい前に公開された4つのAPIを使う事になるようです。
- Natural Language Classifer
- Dialog
- Retrieve and Rank
- Documennto Concersion
最後のAPIは未確認ですが、他の3つは日本語が使えていますので、これらを使う事になると思います。
さいごの話しは、私の憶測でどうなるか分かりませんが、まもなく迎える12月末を楽しみにしましょう。
