


こんにちは、スマートソリューションセンターの「たーぼう」です。
今回の記事は、IBM BluemixとWatson Developer CloudのWatsonサービスを使用して、
質問応答Androidアプリケーションを作成しましたのでご紹介していきたいと思います。
IBM Bluemix、Watson Developer Cloudのそれぞれのサービス説明については、割愛いたします。
それぞれ、こちらのリンクから製品情報についてご覧ください。
今回は、クレスコの採用情報に関する質問に対して、応答するアプリケーションを作成しました。
Bluemixを介して、Watson Developer Cloudが提供するWatson APIサービスを作成し、
Androidアプリケーションと組み合わせることで、実現することができました。
Watson APIサービスは、Natural Language Classifier(NLC)とDialogを使用しました。
全体的なイメージはこんな感じです。
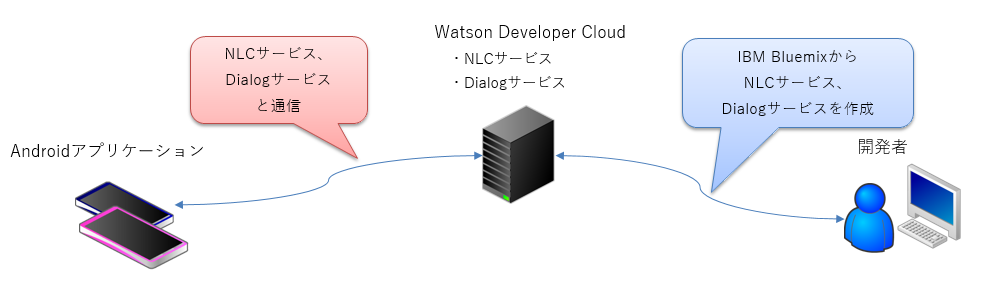
NLCについては既に技術研究所のウエサマが、自然言語分類器 IBM Watson Natural Language Classifier(前編)の記事で語られていますので、参考にしてください。
Dialogについては、あらかじめ定義した会話モデルに応じて回答を返してくれるサービスです。
Watson Developer Cloudに、Dialogのデモサイトがありますので、そちらを利用してみるとイメージしやすいかもしれません。
Androidアプリケーションと通信する為のサーバサイドのアプリケーション開発は行いません。
データベースも利用しませんでした。よって、NLC、Dialogの各Watsonサービスを呼び出して
その結果を判断して画面に表示するAndroidアプリケーションのみ、プログラミングをしました。
”クレスコの採用情報である”という意図を分類し、分類した意図を基に予め定義した回答を答えるだけです。
もうお気づきかと思いますが、Watsonサービスは以下のような使い方になります。
- ”クレスコの採用情報であるという意図を分類” ⇒ NLCにお任せ
- ”予め定義した回答を答える” ⇒ Dialogにお任せ
お任せといっても、
Watsonサービスを利用するにはトレーニングデータを作成して学習させる必要がありますので、
サーバサイド側の作業が全く無くなるわけではありません。
Androidアプリ、NLC、Dialogの各Watsonサービスを組み合わせたフローは次の通りです。
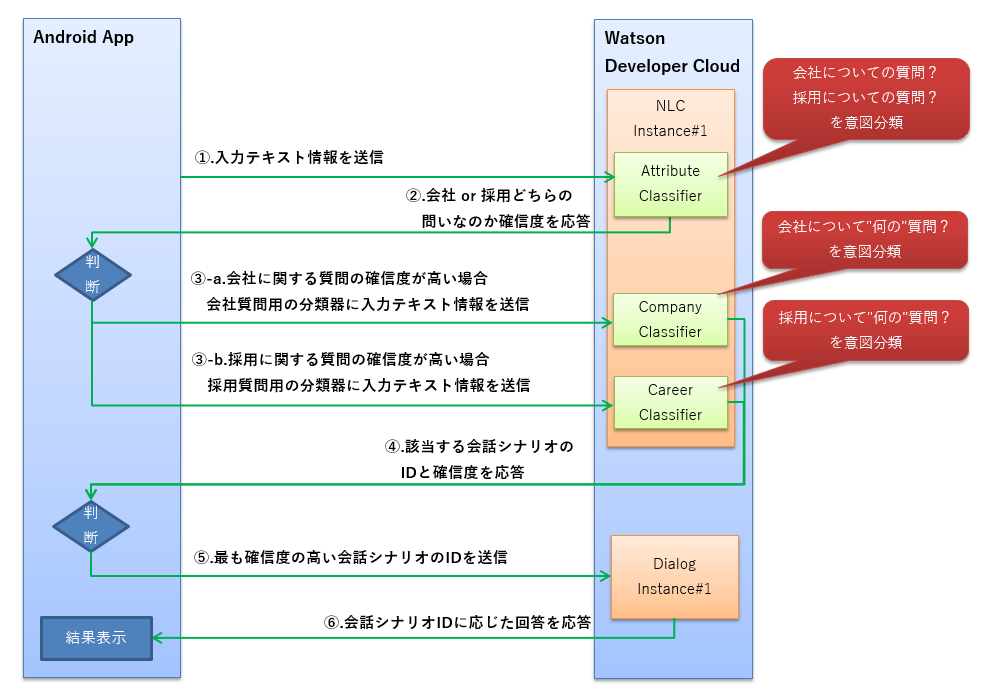
作成したトレーニングデータ以下の通りです。
<NLCへのトレーニングデータ>
- 会社に関する質問なのか?採用に関する質問なのか?を分類するデータ(Attribute)
- 会社のことの中で、代表者の名前、会社の所在地、といったような、
会社の何に対する質問なのか?を分類するデータ(Company) - 採用のことの中で、募集要項や必要資格といったような、
採用の何に対する質問なのか?を分類するデータ(Career)
<Dialogへのトレーニングデータ>
- 会話シナリオIDに紐づいた回答を定義した対話モデルデータ
各トレーニングデータの中身(一部)とデータ間の紐づき関係は次の通りです。
これまでWatsonサービスに与えるトレーニングデータを中心に記載してきましたが
Androidアプリケーションを、これらのWatsonサービスと繋ぎ合わせることで
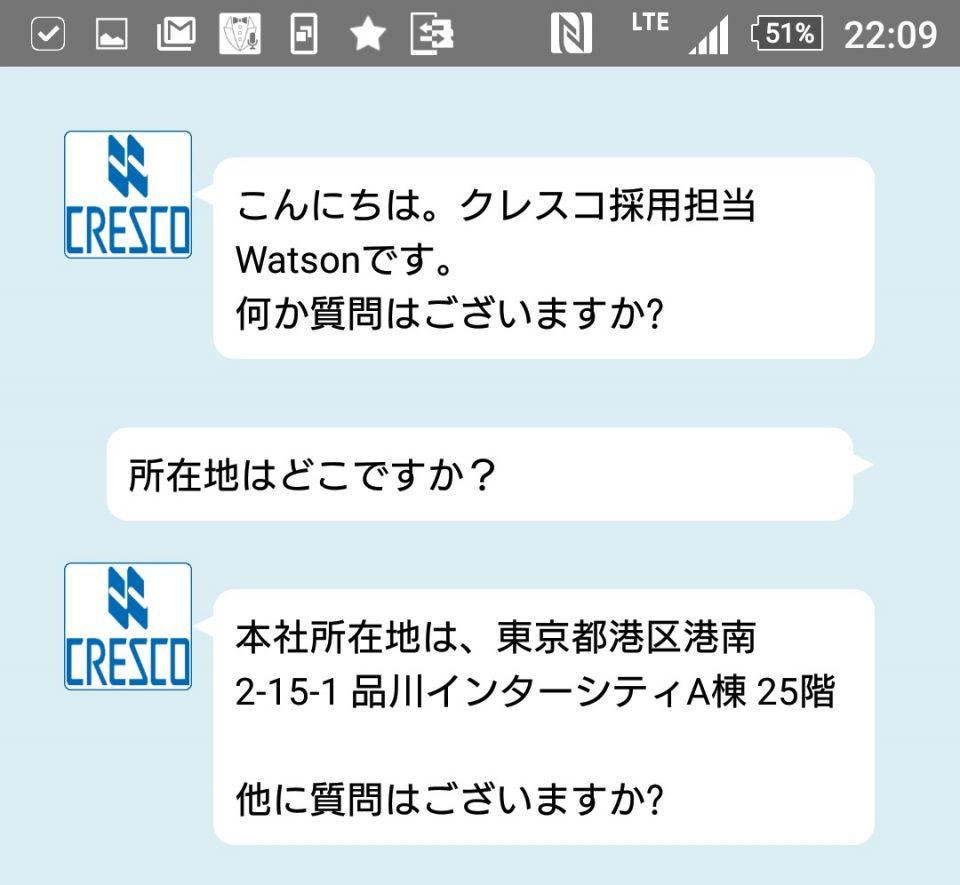
最終的に出来上がったアプリケーションは以下のものになりました。
全く関係の無い質問に対して応答するなど、会話のバリエーションに幅を持たせるには
そのバリエーションに応じて、トレーニングさせるデータも膨らんでいくと思います。
質問応答のシステムを作るにあたり、わざわざWatsonサービスと通信さないで実現することも可能でしょう。しかし、今回Watsonサービスを利用することで、今までであればプログラム側で条件分岐を組み合わせて行ってきたものが、Watsonに学習させることで対応できてしまうというところが、一つポイントになると感じています。
機械学習のトレーニングデータの作成のコツについてはもっと勉強が必要ですね。
また勉強して、記事を書かせてもらいます。
最後まで読んでいただいた方、感謝いたします。ありがとうございました。
